L'estimation de la fonction de régression et les résidus
La fonction de régression est généralement exprimée mathématiquement dans l'une des façons suivantes: la notation de base, la notation de sommation, ou la notation matricielle. La Y variable représente le résultat que vous êtes intéressé à, appelé la variable dépendante, et la Xs représentent toutes les variables indépendantes (ou explicatives). Votre objectif est maintenant d'estimer la fonction de régression de la population (PRF) en utilisant les données des échantillons.
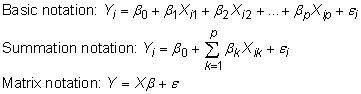
Lorsque l'on travaille sur les problèmes économétriques monde réel, vous spécifiez généralement un PRF avec une variable dépendante et plusieurs variables indépendantes. Par exemple, supposons que vous êtes intéressé par le nombre de hamburgers achetés pendant l'heure du déjeuner à cafétérias scolaires.
La théorie microéconomique suggère que les ventes devraient être influencés par le prix des hamburgers avec d'autres facteurs, comme le prix des autres produits alimentaires, le prix des boissons gazeuses, et ainsi de suite. Avec cela à l'esprit, vous pouvez spécifier votre PRF en utilisant les ventes de hamburgers comme variable dépendante et tous les autres facteurs pertinents tels que les variables indépendantes.
Pour visualiser la régression MCO et d'obtenir une compréhension de base du concept fondamental, supposons maintenant que la variable dépendante (de vente de hamburger) est influencé par une seule variable explicative (le prix des hamburgers).
L'exemple de fonction de régression (SRF) est exprimée en
où Y est la vente de hamburgers et X est le prix. Dans ce cas, la SRF est une ligne, avec la valeur de
l'estimation de l'ordonnée à l'origine et
l'estimation de la valeur de la pente.
Remarquez comment la représentation mathématique de la SRF utilise chapeaux (^) ci-dessus, les coefficients et les erreurs terme. Ce symbole est utilisé pour désigner que ces chiffres sont des estimations de leurs vraies valeurs de la population, mais gardez à l'esprit que certains manuels scolaires utilisent l'anglais (latins) des lettres pour représenter les coefficients de régression de l'échantillon et d'autres estimations.
-
 Résultats d'une régression sur la TI-Nspire
Résultats d'une régression sur la TI-Nspire -
 L'estimation économétrique et les hypothèses de CLRM
L'estimation économétrique et les hypothèses de CLRM - Econometrics: le choix de la forme fonctionnelle de votre modèle de régression
-
 Econométrie et le modèle log-linéaire
Econométrie et le modèle log-linéaire -
 Econométrie et le modèle log-log
Econométrie et le modèle log-log -
 Comment désaisonnaliser les données de séries chronologiques
Comment désaisonnaliser les données de séries chronologiques
Effets de saisonnalité peuvent être corrélées avec vos deux variables dépendantes et indépendantes. Afin d'éviter de confondre les effets de saisonnalité avec ceux de vos variables indépendantes, vous devez contrôler explicitement pour la…
Vous devez rappeler à partir de votre cours de statistiques façon de mener la t-test pour examiner les différences de moyens entre les deux groupes. Mais ce que vous ne pouvez pas savoir est que vous pouvez utiliser des variables nominales et…
L'une des décisions les plus importantes que vous faites lorsque vous spécifiez votre modèle économétrique est variables à inclure comme variables indépendantes. Ici, vous trouverez ce que des problèmes peuvent survenir si vous incluez trop…
Avant de commencer avec l'analyse de régression, vous devez identifier le regre de populationsfonction de Sion (PRF). Le PRF définit la réalité (ou votre perception de celui-ci) en ce qui concerne votre sujet d'intérêt. Pour l'identifier, vous…
Variables dépendantes limitées surgissent quand une certaine valeur de seuil minimum doit être atteint avant que les valeurs de la variable dépendante sont observées et / ou quand une certaine valeur maximale de seuil limite les valeurs…
Obtenir une emprise sur multicolinéarité parfaite, ce qui est rare, est plus facile si vous pouvez imaginer un modèle économétrique qui utilise deux variables indépendantes, telles que les suivantes:Supposons que, dans ce modèle,où les…
Parce que les relations économiques sont rarement linéaires, vous voudrez peut-être pour permettre à votre modèle économétrique d'avoir une certaine souplesse. Avec une fonction quadratique, vous permettez à l'effet de la variable…
En économétrie, le modèle de régression est un point de départ commun d'une analyse. Comme vous définir votre modèle de régression, vous devez tenir compte de plusieurs éléments:La théorie économique, l'intuition et le bon sens devraient…
Beaucoup de phénomènes économiques sont dichotomique en nature- en d'autres termes, le résultat soit se produit ou ne se produit pas. Résultats dichotomiques sont le type le plus commun de variables dépendantes discrètes ou qualitatives…
L'analyse de régression est une des techniques statistiques les plus importantes pour les applications d'entreprise. Il est une méthode statistique qui permet d'estimer la force et la direction de la relation entre deux ou plusieurs variables.…
L'analyse de régression est un outil statistique utilisé pour l'étude des relations entre les variables. Habituellement, l'enquêteur cherche à savoir l'effet causal d'une variable sur une autre - l'effet d'une hausse des prix sur demande, par…
Après vous estimez la droite de régression de la population, vous pouvez vérifier si l'équation de régression est logique en utilisant le coefficient de détermination, également connu comme R2 (R au carré). Ceci est utilisé comme une mesure…
Dans les statistiques de la psychologie, les études de recherche qui impliquent la collecte des données quantitatives (toutes les données qui peut être compté ou rendu sous forme de nombres) exigent habituellement que vous récupériez et…
Bien qu'une corrélation parle à la force d'une relation entre les deux variables, et la r2 contribue à expliquer que la force de la relation, ce que vous devez faire pour prédire une variable d'un autre est d'utiliser une extension de l'analyse…