Haute multicolinéarité et votre modèle économétrique
Des résultats de haute multicolinéarité d'une relation linéaire entre vos variables indépendantes avec un haut degré de corrélation, mais ne sont pas totalement déterministe (en d'autres termes, ils ne disposent pas de corrélation parfaite). Il est beaucoup plus fréquent que son homologue parfait et peut également être problématique quand il vient à l'estimation d'un modèle économétrique.
Vous pouvez décrire une relation linéaire approximative, qui caractérise haute multicolinéarité, comme suit:
où le Xs sont des variables indépendantes dans un modèle de régression et u représente un terme d'erreur aléatoire (qui est le composant qui différencie haute multicolinéarité de multicolinéarité parfaite). Par conséquent, la différence entre colinéarité parfaite et haut est que des variations dans la variable indépendante est pas expliquée par la variation de l'autre variable (s) indépendante.
Le plus fort de la relation entre les variables indépendantes, le plus vous êtes susceptible d'avoir des problèmes d'estimation avec votre modèle.
Relations linéaires fortes résultant en haute multicolinéarité peuvent parfois vous prendre par surprise, mais ces trois situations ont tendance à être particulièrement problématique:
Vous utilisez des variables qui sont les valeurs de l'autre à la traîne. Par exemple, une variable indépendante est le revenu d'un individu dans l'année en cours, et une autre variable indépendante mesure le revenu d'un individu dans l'année précédente. Ces valeurs peuvent être complètement différents pour certaines observations, mais pour la plupart des observations des deux sont étroitement liés.
Vous utilisez des variables qui partagent une composante de tendance commune de temps. Par exemple, vous utilisez des valeurs annuelles du PIB (produit intérieur brut) et le DJIA (Dow Jones Industrial Average) comme variables indépendantes dans un modèle de régression. La valeur de ces mesures tend à augmenter (avec des baisses occasionnelles) et se déplacent généralement dans la même direction au fil du temps.
Vous utilisez des variables qui saisissent des phénomènes similaires. Par exemple, vos variables indépendantes pour expliquer la criminalité dans les villes peut être le taux de chômage, le revenu moyen et le taux de pauvreté. Ces variables ne sont pas susceptibles d'être parfaitement corrélés, mais ils sont probablement fortement corrélées.
Techniquement, la présence d'une forte multicolinéarité ne viole pas les hypothèses de CLRM. En conséquence, les estimations MCO peuvent être obtenus et sont en bleu (meilleurs estimateurs linéaires sans) avec une forte multicolinéarité.
Bien estimateurs MCO restent BLEU en présence d'une forte multicolinéarité, il renforce un souhaitable échantillonnage répété propriété. Dans la pratique, vous avez probablement pas la possibilité d'utiliser plusieurs échantillons, de sorte que vous voulez un échantillon donné pour produire des résultats sensibles et fiables.
Avec haute multicolinéarité, l'OLS estimations ont toujours le plus petit écart, mais plus petit est un concept relatif et ne garantissent pas que les écarts sont en fait des petits. En fait, les écarts plus importants (et les erreurs types) des estimateurs MCO sont la raison principale pour éviter haute multicolinéarité.
Les conséquences typiques de haute multicolinéarité comprennent ce qui suit:
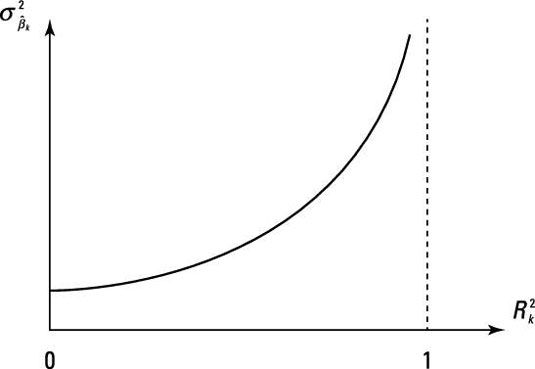
Erreurs standard plus grandes et insignifiante t-Statistiques: La variance estimée d'un coefficient dans une régression multiple est
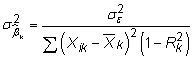
où
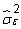
est l'erreur quadratique moyenne (MSE) et
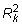
est la valeur de R au carré à partir de la régression Xk de l'autre Xs. Résultats de multicolinéarité supérieur dans une grande
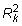
ce qui augmente l'erreur-type du coefficient. La figure illustre l'effet de la multicolinéarité sur la variance (ou erreur-type) d'un coefficient.
Parce que le t-statistique associée à un coefficient est le rapport entre le coefficient estimé de l'erreur-type
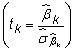
haute multicolinéarité tend également à entraîner insignifiante t-statistiques.
Les estimations des coefficients qui sont sensibles aux changements de spécifications: Si les variables indépendantes sont très colinéaires, les estimations doivent soulignent petites différences dans les variables afin d'attribuer un effet indépendant à chacun d'eux. Ajout ou suppression de variables du modèle peut changer la nature des petites différences et changer radicalement vos estimations des coefficients. En d'autres termes, vos résultats ne sont pas robustes.
Signes et magnitudes de coefficients absurdes: Avec multicolinéarité supérieur, la variance des coefficients estimés augmente, ce qui à son tour augmente les chances d'obtenir des estimations de coefficients avec des valeurs extrêmes. Par conséquent, ces estimations peuvent avoir incroyablement grandes amplitudes et / ou des signes qui contrent la relation attendue entre les variables indépendantes et dépendantes. La figure illustre comment la distribution d'échantillonnage des coefficients estimés est affectée par la multicolinéarité.
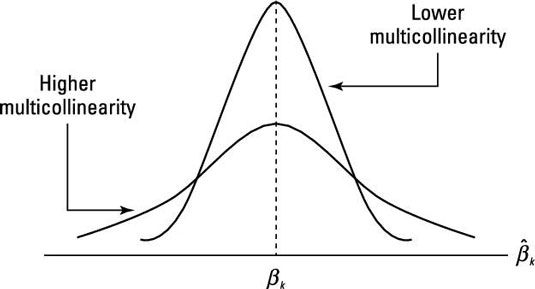
Lorsque deux (ou plusieurs) des variables présentent une forte multicolinéarité, il n'y a plus d'incertitude que la variable à laquelle devrait être crédité expliquer la variation de la variable dépendante. Pour cette raison, un haut R-valeur carré combinée avec de nombreux coefficients statistiquement insignifiants est une conséquence fréquente de haute multicolinéarité.




La fonction de régression est généralement exprimée mathématiquement dans l'une des façons suivantes: la notation de base, la notation de sommation, ou la notation matricielle. La Y variable représente le résultat que vous êtes intéressé…
Dans de nombreux cas, les tendances saisonnières sont supprimés des données de séries chronologiques quand ils sont libérés sur les bases de données publiques. Les données qui a été dépouillé de ses tendances saisonnières est appelé…
Le terme d'erreur est le composant le plus important du modèle de régression linéaire classique (CLRM). La plupart des hypothèses de CLRM qui permettent économètres pour prouver les propriétés souhaitables des estimateurs MCO (le théorème…
Effets de saisonnalité peuvent être corrélées avec vos deux variables dépendantes et indépendantes. Afin d'éviter de confondre les effets de saisonnalité avec ceux de vos variables indépendantes, vous devez contrôler explicitement pour la…
L'une des décisions les plus importantes que vous faites lorsque vous spécifiez votre modèle économétrique est variables à inclure comme variables indépendantes. Ici, vous trouverez ce que des problèmes peuvent survenir si vous incluez trop…
Variables dépendantes limitées surgissent quand une certaine valeur de seuil minimum doit être atteint avant que les valeurs de la variable dépendante sont observées et / ou quand une certaine valeur maximale de seuil limite les valeurs…
Obtenir une emprise sur multicolinéarité parfaite, ce qui est rare, est plus facile si vous pouvez imaginer un modèle économétrique qui utilise deux variables indépendantes, telles que les suivantes:Supposons que, dans ce modèle,où les…
En économétrie, le modèle de régression est un point de départ commun d'une analyse. Comme vous définir votre modèle de régression, vous devez tenir compte de plusieurs éléments:La théorie économique, l'intuition et le bon sens devraient…
Multicollinearity lorsque survient une relation linéaire existe entre deux ou plusieurs variables indépendantes dans un modèle de régression. Dans la pratique, vous rencontrez rarement multicolinéarité parfaite, mais de haute…
L'analyse de régression est une des techniques statistiques les plus importantes pour les applications d'entreprise. Il est une méthode statistique qui permet d'estimer la force et la direction de la relation entre deux ou plusieurs variables.…
L'analyse de régression est un outil statistique utilisé pour l'étude des relations entre les variables. Habituellement, l'enquêteur cherche à savoir l'effet causal d'une variable sur une autre - l'effet d'une hausse des prix sur demande, par…
Vous pouvez utiliser le coefficient de détermination ajusté afin de déterminer comment une équation de régression multiple "adapte" données de l'échantillon. Le coefficient de détermination ajusté est étroitement lié au coefficient de…
Après vous estimez la droite de régression de la population, vous pouvez vérifier si l'équation de régression est logique en utilisant le coefficient de détermination, également connu comme R2 (R au carré). Ceci est utilisé comme une mesure…
Dans les statistiques de la psychologie, les études de recherche qui impliquent la collecte des données quantitatives (toutes les données qui peut être compté ou rendu sous forme de nombres) exigent habituellement que vous récupériez et…