Comment calculer les paramètres et estimateurs
En économétrie, lorsque vous récupérez un échantillon aléatoire de données et de calculer une statistique à ces données, vous êtes produire un estimation ponctuelle, qui est d'une seule estimation d'un paramètre de population.
Statistiques descriptives sont des mesures qui peuvent être utilisés pour résumer les données des échantillons et, par la suite, faire des prédictions au sujet de votre population d'intérêt. Lorsque des mesures descriptives sont calculées en utilisant les données de la population, ces valeurs sont appelées punramètres. Lorsque vous calculez mesures descriptives des données d'exemple, les valeurs sont appelées estimunteurs (ou statistiques).
Vous pourriez estimer nombreux paramètres démographiques des échantillons de données, mais ici vous calculer les statistiques les plus populaires: moyenne, variance, écart-type, covariance et corrélation. La liste suivante indique comment chaque paramètre et son estimateur correspondant est calculé.
Moyenne (moyenne): La signifier est la moyenne simple de la variable aléatoire, X. La population signifie pour X est
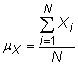
où Xje représente les mesures individuelles et N est la taille de la population. La moyenne de l'échantillon est
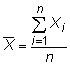
La différence entre l'échantillon et de la population signifie est que que la moyenne d'échantillon utilise la taille de l'échantillon n au lieu de la taille de la population N.
Variance: La variance est la moyenne des carrés des différences de la moyenne. La variance de la population d'une variable aléatoire X est
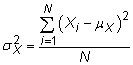
où Xje représente les mesures individuelles,
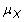
est la moyenne de population, et N est la taille de la population. La variance de l'échantillon est
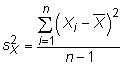
Notez que le dénominateur pour la variance de l'échantillon utilise non seulement la taille de l'échantillon n mais aussi soustrait 1 de ce nombre. Ce changement est connu comme un degrés de liberté l'ajustement. Degrés de liberté ajustements sont généralement importante à prouver que les estimateurs sont sans biais.
L'écart-type: La écart-type comment mesures réparties sur la variable aléatoire est, en moyenne, à partir de la moyenne. L'écart-type est la racine carrée de la variance, de sorte que le écart type de population pour la variable aléatoire X est
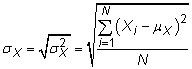
et l'écart type d'échantillon est
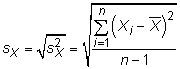
Covariance: La covariance mesures combien deux variables aléatoires changent ensemble. La covariance de la population entre deux variables aléatoires X et Y est
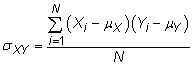
où Xje représente l'individu X valeurs, Yje représente l'individu Y valeurs, et N est le nombre total de mesures effectuées dans la population. L'échantillon est covariance
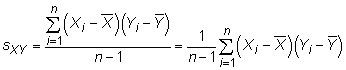
où
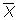
est la moyenne d'échantillon X,
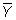
est la moyenne d'échantillon Y, et n est la taille de l'échantillon.
Corrélation: La corrélation se réfère à la relation entre les deux variables aléatoires ou des ensembles de données. Le coefficient de corrélation de population entre deux variables aléatoires X et Y est
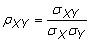
où
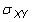
est la covariance de la population,
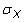
est l'écart type de population de X, et
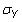
est l'écart type de population de Y. Le coefficient de corrélation est échantillon
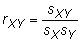
où sXY est la covariance de l'échantillon, sX est l'écart type d'échantillon de X, et sY est l'écart type d'échantillon de Y.
Maintenant, essayer de travailler avec quelques chiffres. Le tableau montre cinq observations de la vente de hamburgers et les prix. Utilisez les formules pour calculer la moyenne, la variance, écart-type, covariance et corrélation.
| Les ventes de Hamburger (en unités), Y | Hamburger Prix (en $), X |
|---|---|
| 100 | 1 |
| 80 | 2 |
| 63 | 3 |
| 45 | 4 |
| 21 | 5 |
Vous pouvez utiliser le logiciel de l'ordinateur, tels que Stata, pour calculer les statistiques descriptives des données. En tapant “ somme ” sur la ligne de commande, vous obtenez les statistiques descriptives pour toutes les variables de votre ensemble de données. Si vous voulez que la corrélation entre deux variables, sélectionnez Statistiques-résumés, tables, et des tests-Résumé et statistiques descriptives-corrélations et covariances à partir de la barre de menu.
Ou vous pouvez entrer “ corr variable1 variunBle2” sur la ligne de commande. Dans votre commande, remplacez variable1 et variable2 avec les noms réels que vous avez donné les variables de votre ensemble de données. Vous pouvez obtenir covariance en ajoutant une option pour le type de corrélation commandement “ corr varjeable1 variable2, cov ” sur la ligne de commande.

Vous devez vérifier que vos calculs manuels de ces mesures sont compatibles avec la sortie de STATA.
Résumé des données statistiques descriptives est une procédure relativement simple, mais assurez-vous que vous examinez attentivement les valeurs. Vous pouvez utiliser des mesures descriptives pour assurer que votre échantillon contient des mesures qui sont réalistes. Par exemple, si votre population d'intérêt est les diplômés du collégial, vous ne seriez pas attendre de votre échantillon aléatoire de ce groupe à avoir une moyenne d'âge de 21 ans.
Attention à ces détails fournit plus de crédibilité dans vos données et les conclusions ultérieures que vous faites.
-
 L'analyse statistique avec Excel pour les nuls
L'analyse statistique avec Excel pour les nuls -
 3 façons de décrire les populations et les échantillons dans les statistiques des entreprises
3 façons de décrire les populations et les échantillons dans les statistiques des entreprises - Briser formules statistiques
- Statistiques sur les entreprises pour les nuls
- Tirer des conclusions sur une population en utilisant des intervalles de confiance et tests d'hypothèses
-
 Déterminer la taille de l'échantillon dans les statistiques
Déterminer la taille de l'échantillon dans les statistiques
Dans les statistiques, l'écart-type dans une population affecte l'erreur-type pour cette population. Ecart-type mesure la quantité de variation dans une population. Dans la formule de l'écart-typevous voyez l'écart type de population,est dans le…
Moments sont des mesures sommaires d'une distribution de probabilité, et comprennent la valeur attendue, la variance et l'écart type. La valeur attendue représente la valeur moyenne ou moyenne d'une distribution. La valeur attendue est parfois…
Deux des termes les plus importants sont dans les statistiques moyenne et la variance, et si vous avez besoin pour être en mesure d'identifier leurs notations lorsque l'on travaille avec des variables aléatoires discrètes.La signifier d'une…
Lorsque l'on compare des échantillons de données de différentes populations, deux des mesures les plus populaires de l'association sont covariance et corrélation. Covariance et corrélation montrer que les variables peuvent avoir une relation…
Bien que la normale (Z-) Distribution et t-la distribution sont similaires, ils regardent différents les uns des autres et sont utilisées à des fins statistiques différentes. La distribution normale est que la distribution en forme de cloche…
Mesures de tendance centrale montrent le centre d'un ensemble de données. Trois des mesures les plus courantes de la tendance centrale sont la moyenne, la médiane et le mode.SignifierSignifier est un autre mot pour la moyenne. Voici la formule de…
Mesures de dispersion centrale montrent comment "étalées" les éléments d'un ensemble de données sont de la moyenne. Trois des mesures les plus courantes de la dispersion centrale sont les suivantes:GammeVarianceL'écart-typeGammeLa gamme d'un…
Lors de la conception d'une étude, la taille de l'échantillon est une considération importante parce que plus la taille de l'échantillon, plus les données que vous avez, et la plus précise vos résultats seront (en supposant données de haute…
Avec les outils d'analyse des données disponibles dans Excel 2007, vous pouvez créer des feuilles de calcul qui montrent les détails de toute statistique, vous pouvez créer une formule à trouver - et vous pouvez trouver un certain nombre. Il…
Mesures de tendance centrale montrent le centre d'un ensemble de données. Trois des mesures les plus courantes de la tendance centrale sont la moyenne, la médiane et le mode.SignifierSignifier est un autre mot pour la moyenne. Voici la formule de…
Après les données ont été recueillies, la première étape de l'analyse, il est à croquer quelques statistiques descriptives pour obtenir une sensation pour les données. Par example:Où est le centre de données situé?Comment étaler est les…
Comme chaque sujet, des statistiques a sa propre langue. La langue est ce qui vous permet de savoir ce qui est un problème pour la demande, quels résultats sont nécessaires, et la façon de décrire et d'évaluer les résultats d'une manière…
L'idée d'échantillonnage d'une population est un des concepts les plus fondamentaux dans les statistiques - en fait, de toute la science. Par exemple, vous ne pouvez pas tester la façon dont un médicament de chimiothérapie travaillera en tous…
La écart-type (généralement abrégé SD, sd, ou juste s) D'un tas de chiffres vous indique combien les numéros individuels ont tendance à différer (dans les deux sens) de la moyenne. Il est calculé comme suit:Cette formule est dit que vous…