Lorsque vous travaillez avec des populations et des échantillons (un sous-ensemble d'une population) dans les statistiques commerciales, vous pouvez utiliser trois types de mesures pour décrire l'ensemble de données: la tendance centrale, dispersion, et l'association.
Par convention, les formules statistiques utilisées pour décrire les mesures de population contiennent des lettres grecques, tandis que les formules utilisées pour décrire les mesures d'échantillons contiennent des lettres latines.
Mesures de tendance centrale
Dans les statistiques, la moyenne, la médiane et le mode sont connus comme des mesures de tendance centrale- ils sont utilisés pour identifier le centre d'un ensemble de données:
Signifier: La valeur entre les valeurs les plus grandes et les plus petites d'un ensemble de données, obtenu par une méthode prescrite.
Médiane: La valeur qui divise un ensemble de données en deux moitiés égales
Mode: La valeur la plus fréquemment observée dans un ensemble de données
Les échantillons sont choisis au hasard à partir de populations. Si ce processus est effectué correctement, chaque échantillon doit refléter exactement les caractéristiques de la population. Ainsi, une mesure de l'échantillon, tel que le signifier, devrait être une bonne estimation de la mesure de la population correspondante. Considérons les exemples suivants de la moyenne:
Moyenne de la population:
Cette formule vous dit tout simplement d'additionner tous les éléments de la population et de diviser par la taille de la population.
Moyenne de l'échantillon:
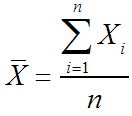
Le processus de calcul de ce est exactement le same- vous additionnez tous les éléments de l'échantillon et diviser par la taille de l'échantillon.
En plus des mesures de tendance centrale, deux autres principaux types de mesures sont des mesures de dispersion (diffusion) et des mesures d'association.
Des mesures de dispersion
Mes mesures de dispersion inclure la variance / écart-type et percentiles / quartiles / intervalle interquartile. La variance et l'écart type sont étroitement liés les uns aux autre- l'écart-type est toujours égal au racine carrée de la variance.
Les formules pour la population et de variance de l'échantillon sont:
La variance de la population:
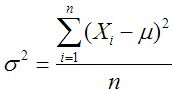
Variance échantillon:
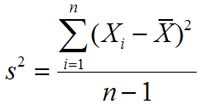
Percentiles diviser un ensemble de données en 100 parties égales constituées chacune de 1 pour cent des valeurs dans l'ensemble de données. Quartiles sont un type spécial de percentiles- ils se séparent les données en quatre parties égales. La interquartile gamme représente le milieu 50 pour cent de la de données il est calculé comme le troisième quartile moins le premier quartile.
Mesures d'association
Un autre type de mesure, connue sous le nom de mesure association, se réfère à la relations entre deux échantillons ou des deux populations. Deux exemples de ce sont les covariance et le corrélation:
Covariance de la population:
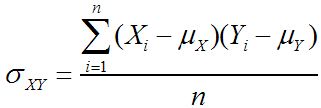
Covariance échantillon:
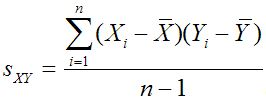
Corrélation de la population:
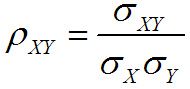
Corrélation échantillon:
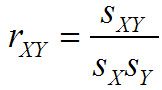
La corrélation est étroitement liée à la covariance- il est défini pour assurer que sa valeur est toujours comprise entre un négatif et un positif.
Variables aléatoires et distributions de probabilités statistiques d'entreprises
Variables aléatoires et distributions de probabilité sont deux des concepts les plus importants en matière de statistiques. UN variable aléatoire assigne des valeurs numériques uniques pour les résultats d'un experiment- aléatoire ceci est un processus qui génère des résultats incertains. UN distribution de probabilité assigne des probabilités pour chaque valeur possible d'une variable aléatoire.
Les deux types de base de distributions de probabilité sont discret et continu. Une distribution de probabilité discrète ne peut assumer un fini nombre de valeurs différentes.
Des exemples de distributions discrètes comprennent:
Une distribution de probabilité continue peut assumer un infini nombre de valeurs différentes. Des exemples de distributions continues comprennent:
Uniforme
Ordinaire
T de Student
Chi-carré
F
Comprendre Distributions d'échantillonnage dans les statistiques des entreprises
Dans les statistiques, les distributions d'échantillonnage sont les distributions de probabilité de toute statistique donnée sur la base d'un échantillon aléatoire, et sont importantes parce qu'elles fournissent une simplification importante sur la route de l'inférence statistique. Plus précisément, ils permettent des considérations analytiques pour être basées sur la distribution d'échantillonnage d'une statistique, plutôt que sur la distribution de probabilité conjointe de toutes les valeurs d'échantillons individuels.
La valeur d'un échantillon statistique telle que la moyenne échantillon (X) est susceptible d'être différent pour chaque échantillon tiré à partir d'une population. Il peut donc être considéré comme un variable aléatoire, dont les propriétés peuvent être décrites avec un distribution de probabilité. La distribution de probabilité d'un échantillon statistique est connu en tant que distribution d'échantillonnage.
Selon un résultat clé dans les statistiques connues sous le théorème central limite, la distribution d'échantillonnage de la moyenne de l'échantillon est normal si l'une des deux choses l'une:
Deux moments sont nécessaires pour calculer les probabilités pour l'échantillon significations la moyenne de la distribution d'échantillonnage est égale à:
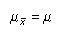
L'écart-type de la distribution d'échantillonnage (également connu sous le nom erreur standard) Peut prendre une des deux valeurs possibles:
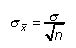
Ceci est un choix approprié pour une sample- "petit" par exemple, la taille de l'échantillon est inférieure ou égale à 5 pour cent de la taille de la population.
Si l'échantillon est "grand", l'erreur-type devient:
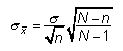
Probabilités peuvent être calculées pour la moyenne de l'échantillon directement depuis la table normale standard en appliquant la formule suivante:
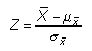
Explorez Test d'hypothèse dans les statistiques des entreprises
Dans les statistiques, htests ypothesis se réfère au processus de choix entre hypothèses concurrentes sur une distribution de probabilités, basée sur les données observées à partir de la distribution. Il est un sujet de base et une partie fondamentale de la langue de statistiques.
Test d'hypothèse est une procédure en six étapes:
Hypothèse 1.Null
Hypothèse 2.Alternative
3.Level d'importance
4.PROCÉDURE statistique
5.Critical valeur (s)
6.Decision règle
La hypothèse nulle est une déclaration qui est supposé être vrai, sauf si il ya de fortes preuves contradictoires. La hypothèse alternative est une déclaration qui sera acceptée à la place de l'hypothèse nulle si elle est rejetée.
La niveau de signification est choisi pour contrôler la probabilité d'un "type I" ERREUR ceci est l'erreur qui se produit lorsque l'hypothèse nulle est rejetée par erreur.
La statistique de test et valeurs critiques sont utilisées pour déterminer si l'hypothèse nulle doit être rejetée. La règle de décision qui est suivie est qu'un des résultats de test statistique «extrêmes» dans le rejet de l'hypothèse nulle. Ici, une statistique de test est une extrême qui se trouve en dehors des limites de la valeur ou des valeurs critiques.
Les hypothèses sont souvent testés sur les valeurs de mesures de la population telles que la moyenne et la variance. Ils sont également utilisés pour déterminer si une population suit une distribution de probabilité déterminée. Ils forment également une partie importante de l'analyse de régression, où les hypothèses sont utilisées pour valider les résultats d'une équation de régression estimée.
Comment les entreprises Statistiques Analyse utiliser la régression
L'analyse de régression est un outil statistique utilisé pour l'étude des relations entre les variables. Habituellement, l'enquêteur cherche à savoir l'effet causal d'une variable sur une autre - l'effet d'une hausse des prix sur demande, par exemple, ou l'effet des variations de la masse monétaire sur le taux d'inflation.
L'analyse de régression est utilisée pour estimer la force et la direction de la relation entre les deux variables en relation linéaire: X et Y. X est la variable «indépendant» et Y est la variable "dépendante".
Les deux types de base de l'analyse de régression sont:
Analyse de régression simple: Utilisé pour estimer la relation entre une variable dépendante et une seule Variable- indépendante par exemple, la relation entre les rendements des cultures et des précipitations.
Analyse de régression multiple: Utilisé pour estimer la relation entre une variable dépendante et deux ou variables- plus indépendant par exemple, la relation entre les salaires des employés et de leur expérience et de l'éducation.
Analyse de régression multiple introduit plusieurs complexités supplémentaires, mais peut produire des résultats plus réalistes que l'analyse de régression simple.
L'analyse de régression est basée sur plusieurs hypothèses fortes sur les variables qui sont estimées. Plusieurs tests clés sont utilisés pour assurer que les résultats sont valides, y compris des tests d'hypothèses. Ces tests sont utilisés pour veiller à ce que les résultats de la régression ne sont pas simplement due au hasard aléatoire, mais indiquent une relation réelle entre deux ou plusieurs variables.
Une équation de régression estimée peut être utilisée pour une grande variété d'applications d'entreprise, telles que:
Mesurer l'impact sur les bénéfices d'une société d'une augmentation des profits
Comprendre comment sensible des ventes d'une société sont à des changements dans les dépenses de publicité
En voyant comment un prix de l'action est affectée par les variations des taux d'intérêt
L'analyse de régression peut également être utilisé pour la prévision purposes- par exemple, une équation de régression peut être utilisée pour prévoir la demande future pour les produits d'une entreprise.
En raison de l'extrême complexité de l'analyse de régression, il est souvent mis en œuvre par l'utilisation de calculatrices spécialisées ou des tableurs.


 techniques")

