Statistiques des entreprises: recours à l'analyse de régression pour déterminer la validité des relations
L'analyse de régression est une des techniques statistiques les plus importantes pour les applications d'entreprise. Il est une méthode statistique qui permet d'estimer la force et la direction de la relation entre deux ou plusieurs variables. L'analyste peut utiliser l'analyse de régression pour déterminer la relation réelle entre ces variables en regardant les ventes et les bénéfices d'une société au cours des dernières années. Les résultats de la régression montrent si cette relation est valable.
Sommaire
- Étape 1: spécifier la variable dépendante et indépendante (s)
- Étape 2: vérifiez linéarité
- Étape 3: vérifiez approches alternatives si les variables ne sont pas linéaires
- Étape 4: estimer le modèle
- 5 étapes: tester l'ajustement du modèle en utilisant le coefficient de variation
- Étape 6: effectuer un test de l'hypothèse conjointe sur les coefficients
- Etape 7: effectuer des tests d'hypothèses sur les coefficients de régression individuelles
- Étape 8: vérifiez les violations des hypothèses de l'analyse de régression
- Etape 9: interpréter les résultats
- Étape 10: prévisions valeurs futures
En plus des ventes, d'autres facteurs peuvent également déterminer les bénéfices de la société, ou il peut arriver que les ventes ne expliquent les bénéfices à tous. En particulier, les chercheurs, les analystes, les gestionnaires de portefeuille et les commerçants peuvent utiliser l'analyse de régression pour estimer les relations historiques entre les différents actifs financiers. Ils peuvent ensuite utiliser cette information pour élaborer des stratégies de négociation et de mesurer le risque contenue dans un portefeuille.
L'analyse de régression est un outil indispensable pour l'analyse des relations entre les variables financières. Par exemple, il peut:
Identifier les facteurs qui sont les plus responsables pour les profits d'une société
Déterminer combien un changement des taux d'intérêt aura des répercussions sur un portefeuille d'obligations
Développer une prévision de la valeur future du Dow Jones Industrial Average
Les dix sections suivantes décrivent les étapes utilisées pour mettre en œuvre un modèle de régression et analyser les résultats.
Étape 1: Spécifier la variable dépendante et indépendante (s)
Pour mettre en œuvre un modèle de régression, il est important de spécifier correctement la relation entre les variables étant utilisé. La valeur d'un variable dépendante est supposé être lié à la valeur d'un ou plusieurs variables indépendantes. Par exemple, supposons qu'un chercheur étudie les facteurs qui déterminent le taux d'inflation. Si le chercheur estime que le taux d'inflation dépend de la vitesse de la masse monétaire de la croissance, il peut estimer un modèle de régression en utilisant le taux d'inflation comme variable dépendante et le taux de l'offre de monnaie comme variable indépendante de la croissance.
Un modèle de régression sur la base d'une seule variable indépendante est connu comme un simple modélisation de régression avec deux ou plusieurs variables indépendantes, le modèle est connu comme un multiple modèle de régression.
Étape 2: Vérifiez linéarité
Une des hypothèses fondamentales de l'analyse de régression est que la relation entre les variables dépendantes et indépendantes est linéaire (à savoir, la relation peut être illustré par un ligne droite.) Une des façons les plus rapides pour vérifier cela est de représenter graphiquement les variables à l'aide d'un nuage de points. Un diagramme de dispersion montre la relation entre deux variables avec la variable dépendante (Y) sur l'axe vertical et la variable indépendante (X) sur l'axe horizontal.
Par exemple, supposons qu'un analyste estime que les rendements excédentaires à Coca-Cola de stock dépendent des rendements excédentaires (la SP) de la Standard and Poor 500. (Le rendement excédentaire à un stock correspond au rendement réel moins le rendement d'un bon du Trésor .) À l'aide des données mensuelles de Septembre 2008 à Août 2013, l'image suivante montre les rendements excédentaires à la SP 500 sur l'axe horizontal, tandis que les rendements excédentaires à Coca-Cola sont sur l'axe vertical.
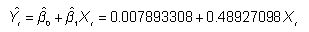
Il peut être vu à partir du nuage de points que cette relation est au moins approximativement linéaire. Par conséquent, la régression linéaire peut être utilisée pour estimer la relation entre ces deux variables.
Étape 3: Vérifiez approches alternatives si les variables ne sont pas linéaires
Si la personne à charge spécifiée (Y) et indépendant (x) les variables ne disposent pas d'une relation linéaire entre eux, il peut être possible de transformer ces variables de sorte qu'ils ont une relation linéaire. Par exemple, il se peut que la relation entre le logarithme naturel de X et Y est linéaire. Une autre possibilité est que la relation entre le logarithme naturel de Y et le logarithme naturel de X est linéaire. Il est également possible que la relation entre la racine carrée de X et Y est linéaire.
Si ces transformations ne produisent pas une relation linéaire, les variables indépendantes de substitution peuvent être choisis mieux expliquer que la valeur de la variable dépendante.
Étape 4: Estimer le modèle
Le modèle de régression linéaire standard peut être estimée à l'aide d'une technique appelée moins ordinaire carrés. Cela se traduit dans les formules pour la pente et l'interception de l'équation de régression qui "fit" la relation entre la variable indépendante (X) et variable dépendante (Y) aussi étroitement que possible.
Par exemple, les tableaux suivants présentent les résultats de l'estimation d'un modèle de régression pour les rendements excédentaires à Coca-Cola stock et le SP 500 sur la période Septembre 2008 à Août 2013.
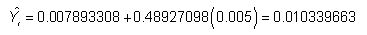
Dans ce modèle, les rendements excédentaires à Coca-Cola de stock sont la variable dépendante, tandis que les rendements excédentaires à la SP 500 sont la variable indépendante. Dans la colonne des coefficients, on peut voir que le point d'intersection d'environ l'équation de régression est 0,007893308, et la pente est d'environ 0,48927098.
5 étapes: tester l'ajustement du modèle en utilisant le coefficient de variation
Le coefficient de variation (aussi connu comme R2) Est utilisé pour déterminer à quel point un modèle de régression "unique" ou explique la relation entre la variable indépendante (X) et la variable dépendante (Y). R2 peut prendre une valeur entre 0 et 1- la plus proche R2 est à 1, le meilleur est le modèle de régression explique les données observées.
Comme indiqué dans les tableaux de l'étape 4, le coefficient de variation est indiqué comme «R-carré" - ce qui équivaut à 0,271795467. L'ajustement est pas particulièrement forte. Très probablement, le modèle est incomplète, comme d'autres facteurs que les rendements excédentaires à la SP 500 également déterminer ou expliquer les rendements excédentaires à Coca-Cola stock.
Pour un modèle de régression multiple, le coefficient de détermination ajusté est utilisé au lieu du coefficient de détermination pour tester l'ajustement du modèle de régression.
Étape 6: Effectuer un test de l'hypothèse conjointe sur les coefficients
Une équation de régression multiple est utilisée pour estimer la relation entre une variable dépendante (Y) et deux ou plusieurs variables indépendantes (X). Lorsque la mise en œuvre d'un modèle de régression multiple, la qualité d'ensemble des résultats peut être vérifié avec un test d'hypothèse. Dans ce cas, l'hypothèse nulle selon laquelle tous les coefficients de pente du modèle égal à zéro, avec l'hypothèse alternative que au moins l'un des coefficients de pente est différente de zéro.
Si cette hypothèse ne peut être rejetée, les variables indépendantes font pas expliquer la valeur de la variable dépendante. Si l'hypothèse est rejetée, au moins une des variables indépendantes ne explique la valeur de la variable dépendante.
Etape 7: Effectuer des tests d'hypothèses sur les coefficients de régression individuelles
Chaque coefficient estimé dans une équation de régression doit être testée pour déterminer si elle est statistiquement significative. Si le coefficient est statistiquement significative, la variable correspondant contribue à expliquer la valeur de la variable dépendante (Y). L'hypothèse nulle qui est testée est que le coefficient est égal à zéro si cette hypothèse ne peut être rejetée, la variable correspondante est pas statistiquement significatif.
Ce type de test d'hypothèse peut être effectuée avec un p-valeur (également connu en tant que valeur de probabilité.) Les tableaux de l'étape 4 montrent que la valeur p associée au coefficient de pente est 1,94506 E-05. Cette expression est écrit en termes de notation scientifique- il peut également être écrit comme 1,94506 X 10-5 ou 0,0000194506.
La valeur p est comparé au seuil de signification de l'essai d'hypothèses. Si la p-valeur est moins de le niveau de signification, l'hypothèse nulle que le coefficient est égal à zéro est rejected- la variable est, par conséquent, statistiquement significative.
Dans cet exemple, le niveau de signification est de 0,05. La p-valeur de 0,0000194506 indique que la pente de cette équation est statistiquement significative- par exemple, les rendements excédentaires au SP 500 expliquer les rendements excédentaires à Coca-Cola stock.
Étape 8: Vérifiez les violations des hypothèses de l'analyse de régression
L'analyse de régression est basée sur plusieurs hypothèses clés. Les violations de ces hypothèses peuvent conduire à des résultats erronés. Trois des violations les plus importantes qui peuvent être rencontrés sont connus comme: autocorrélation, hétéroscédasticité et multicolinéarité.
Autocorrélation lorsque les résultats de résidus d'un modèle de régression ne sont pas indépendants les uns des autres. (A résiduelle est égale à la différence entre la valeur de Y prédit par une équation de régression et la valeur réelle de Y.)
Autocorrélation peut être détectée à partir des graphiques des résidus ou en utilisant des mesures statistiques plus formels tels que la statistique de Durbin-Watson. L'autocorrélation peut être éliminé par des transformations appropriées des variables de régression.
Hétéroscédasticité se réfère à une situation où les variances des résidus d'un modèle de régression sont pas égaux. Ce problème peut être identifié avec un terrain de transformations residuals- des données peut parfois être utilisé pour surmonter ce problème.
Multicolinéarité est un problème qui peut survenir seulement avec analyse de régression multiple. Il se réfère à une situation où deux ou plusieurs des variables indépendantes sont fortement corrélées les unes des autres. Ce problème peut être détectée avec des mesures statistiques officielles, comme le facteur d'inflation variance (VIF). Lorsque multicolinéarité est présent, l'une des variables fortement corrélées doivent être retirés de l'équation de régression.
Etape 9: Interpréter les résultats
L'ordonnée à l'origine et le coefficient estimé de un modèle de régression peuvent être interprétés de la manière suivante. L'ordonnée montre ce que la valeur de Y serait si X était égal à zéro. La pente montre l'impact sur Y d'un changement de X.
Basé sur les tables à l'étape 4, l'interception est estimé à 0,007893308. Cela indique que l'excès de rendement mensuel de Coca-Cola de stock serait 0,007893308 ou 0,7893308 pour cent, si l'excès de rendement mensuel à la SP 500 était de 0 pour cent.
En outre, la pente estimée est 0,48927098. Cela indique qu'une augmentation de 1 pour cent de l'excédent de rendement mensuel à la SP 500 se traduirait par une augmentation de 0,48927098 pour cent dans l'excès de rendement mensuel de Coca-Cola stock. De manière équivalente, à 1 pour cent de diminution du rendement mensuel excédent au SP 500 se traduirait par une diminution de 0,48927098 pour cent dans l'excès de rendement mensuel de Coca-Cola stock.
Étape 10: Prévisions valeurs futures
Un modèle de régression estimée peut être utilisée pour produire des prévisions de la valeur future de la variable dépendante. Dans cet exemple, l'équation estimée est la suivante:
Supposons qu'un analyste a des raisons de croire que l'excès de rendement mensuel à la SP 500 en Septembre 2013 sera de 0,005 ou 0,5 pour cent. L'équation de régression peut être utilisée pour prédire le rendement excédentaire mensuel à Coca-Cola de stock comme suit:
Le rendement excédentaire mensuelle prévue à Coca-Cola boursier est 0,010339663 ou 1,0339663 pour cent.
-
 Comment utiliser régressions linéaires dans l'analyse prédictive
Comment utiliser régressions linéaires dans l'analyse prédictive - L'analyse de régression dans l'analyse statistique des données volumineuses
-
 Résultats d'une régression sur la TI-Nspire
Résultats d'une régression sur la TI-Nspire - L'estimation économétrique et les hypothèses de CLRM
- Econometrics: le choix de la forme fonctionnelle de votre modèle de régression
-
 Econométrie et le modèle log-linéaire
Econométrie et le modèle log-linéaire
Utilisation des journaux naturelles pour les variables sur les deux côtés de votre spécification économétrique est appelé log-log modèle. Ce modèle est à portée de main lorsque la relation est non linéaire dans les paramètres, car la…
La fonction de régression est généralement exprimée mathématiquement dans l'une des façons suivantes: la notation de base, la notation de sommation, ou la notation matricielle. La Y variable représente le résultat que vous êtes intéressé…
L'une des décisions les plus importantes que vous faites lorsque vous spécifiez votre modèle économétrique est variables à inclure comme variables indépendantes. Ici, vous trouverez ce que des problèmes peuvent survenir si vous incluez trop…
Avant de commencer avec l'analyse de régression, vous devez identifier le regre de populationsfonction de Sion (PRF). Le PRF définit la réalité (ou votre perception de celui-ci) en ce qui concerne votre sujet d'intérêt. Pour l'identifier, vous…
Obtenir une emprise sur multicolinéarité parfaite, ce qui est rare, est plus facile si vous pouvez imaginer un modèle économétrique qui utilise deux variables indépendantes, telles que les suivantes:Supposons que, dans ce modèle,où les…
En économétrie, le modèle de régression est un point de départ commun d'une analyse. Comme vous définir votre modèle de régression, vous devez tenir compte de plusieurs éléments:La théorie économique, l'intuition et le bon sens devraient…
Multicollinearity lorsque survient une relation linéaire existe entre deux ou plusieurs variables indépendantes dans un modèle de régression. Dans la pratique, vous rencontrez rarement multicolinéarité parfaite, mais de haute…
L'analyse de régression est un outil statistique utilisé pour l'étude des relations entre les variables. Habituellement, l'enquêteur cherche à savoir l'effet causal d'une variable sur une autre - l'effet d'une hausse des prix sur demande, par…
Vous pouvez utiliser le coefficient de détermination ajusté afin de déterminer comment une équation de régression multiple "adapte" données de l'échantillon. Le coefficient de détermination ajusté est étroitement lié au coefficient de…
Pour estimer un modèle de régression série de temps, une tendance doit être estimée. Vous commencez par créer un graphique de ligne de la série chronologique. Le graphique linéaire montre comment une variable change plus Time-il peut être…
Après vous estimez la droite de régression de la population, vous pouvez vérifier si l'équation de régression est logique en utilisant le coefficient de détermination, également connu comme R2 (R au carré). Ceci est utilisé comme une mesure…
Dans les statistiques de la psychologie, les études de recherche qui impliquent la collecte des données quantitatives (toutes les données qui peut être compté ou rendu sous forme de nombres) exigent habituellement que vous récupériez et…
Qu'est-ce que les praticiens Six Sigma doivent faire avec toutes les situations où plus d'un X une influence Y? Tu utilises la régression linéaire multiple. Après tout, ce genre de situation est plus commun que d'une seule variable d'influence…
Bien qu'une corrélation parle à la force d'une relation entre les deux variables, et la r2 contribue à expliquer que la force de la relation, ce que vous devez faire pour prédire une variable d'un autre est d'utiliser une extension de l'analyse…