Comment tester une différence moyenne en utilisant le test t apparié
Vous pouvez tester pour une différence moyenne en utilisant la apparié t-tester si la variable est numérique (par exemple, le revenu, le niveau de cholestérol, ou de miles par gallon) et les individus dans l'échantillon statistique sont soit jumelé d'une certaine façon en fonction de variables pertinentes telles que l'âge ou peut-être du poids, ou les mêmes personnes sont utilisé deux fois (par exemple, en utilisant un pré-test et post-test).
Des couples de tests sont généralement utilisés pour des études dans lesquelles quelqu'un teste pour voir si un nouveau traitement, une technique ou méthode fonctionne mieux que une méthode existante, sans avoir à se soucier d'autres facteurs sur les sujets qui peuvent influer sur les résultats.
Avec la différence moyenne, vous correspondre les sujets de sorte qu'ils sont considérés comme provenant d'une seule population, et l'ensemble des écarts mesurés pour chaque sujet (par exemple, pré-test par rapport post-test) sont considéré comme un échantillon. Le test d'hypothèse revient ensuite vers le bas pour un test pour une moyenne de la population.
Par exemple, supposons un chercheur veut voir si les élèves d'apprendre à lire à l'aide d'un jeu d'ordinateur donne de meilleurs résultats que l'enseignement avec une méthode phonétique essayé-et-vrai. Elle sélectionne au hasard 20 élèves et les met en 10 paires en fonction de leur niveau de préparation à la lecture, l'âge, le QI, et ainsi de suite. Elle sélectionne au hasard un élève de chaque paire d'apprendre à lire par la méthode de jeu de l'ordinateur (CM abrégé), et l'autre dans la paire apprend à lire en utilisant la méthode phonétique (PM abrégé). A la fin de l'étude, chaque étudiant suit le même test de lecture. Les données sont présentées dans le tableau suivant.
| Scores lecture pour Computer Game Methodversus Phonétique Méthode | |||
| Paire étudiants | Méthode informatique | Phonétique Méthode | Différence (CM - PM) |
|---|---|---|---|
| 1 | 85 | 80 | +5 |
| 2 | 80 | 80 | 0 |
| 3 | 95 | 88 | +7 |
| 4 | 87 | 90 | -3 |
| 5 | 78 | 72 | +6 |
| 6 | 82 | 79 | +3 |
| 7 | 57 | 50 | +7 |
| 8 | 69 | 73 | -4 |
| 9 | 73 | 78 | -5 |
| 10 | 99 | 95 | +4 |
Les données d'origine sont en paires, mais vous êtes vraiment intéressé seulement dans la différence dans les scores de lecture (phonétique score en lecture informatique de moins lire score) pour chaque paire, ne pas les scores de lecture elles-mêmes. Donc le différences appariées (les différences dans les paires de scores) sont votre nouvel ensemble de données. Vous pouvez voir leurs valeurs dans la dernière colonne du tableau.
En examinant les différences dans les paires d'observations, vous avez vraiment avoir qu'un seul ensemble de données, et vous avez seulement un test d'hypothèse pour une moyenne de population. Dans cet exemple spécifique, l'hypothèse nulle est que la moyenne (des différences appariées) est égal à 0, et l'hypothèse alternative est que la moyenne (des différences appariées) est supérieure à 0.
Si les deux méthodes de lecture sont les mêmes, la moyenne des différences appariées devrait être proche de 0. Si la méthode de l'ordinateur est meilleure, la moyenne des différences appariées devrait être nettement plus que 0- qui est, le score de la lecture informatique serait plus grande que les phonétique marquer.
La notation pour l'hypothèse nulle est
(La ré dans l'indice vous rappelle juste que vous travaillez avec les différences appariées.)
La formule pour la statistique de test pour les différences appariées est

l'échantillon, et tn-1 est une valeur sur la t-distribution avec nré - 1 degrés de liberté.
Vous utilisez un t-Répartition ici parce que dans la plupart des expériences appariée la taille de l'échantillon est faible et / ou l'écart type de la population
est inconnue, il est donc estimé par sré.
Pour calculer la statistique de test pour les différences appariées, procédez comme suit:
Pour chaque paire de données, prendre la première valeur de la paire moins la deuxième valeur de la paire de trouver la différence jumelé.
Pensez aux différences que votre nouvel ensemble de données.
Calculer la moyenne,
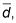
et l'écart-type, sré, de toutes les différences.
Laisser nré représenter le nombre de différences paires que vous avez, calculons l'erreur type:
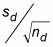
Diviser
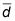
par l'erreur-type de l'étape 3.
Car
est égal à 0 si H0 est vrai, il n'a pas vraiment besoin d'être inclus dans la formule de la statistique de test. En conséquence, vous voyez parfois la statistique de test écrit comme ceci:
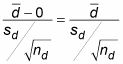
Pour l'exemple des notes de lecture, vous pouvez utiliser les étapes précédentes pour voir si la méthode de l'ordinateur est mieux en termes de l'enseignement aux élèves à lire.
Pour trouver la statistique, suivez ces étapes:
Calculer les différences pour chaque paire (ils sont affichés dans la colonne 4 du tableau ci-dessus). Remarquez que le signe sur chacune des différences est important- il indique la méthode de meilleurs résultats pour cette paire particulière.
Calculer la moyenne et l'écart-type de la différence de l'étape 1. Dans cet exemple, la moyenne des différences est
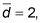
et l'écart type est sré = 4,64. Noter que nré = 10 ici.
L'erreur-type est
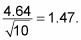
(Rappelez-vous que ici, nré est le nombre de paires, ce qui est 10.)
Prendre la moyenne des différences (étape 2) divisé par l'erreur-type de 1,47 (étape 3) pour obtenir 1,36, la statistique de test.
Est le résultat de l'étape 4 suffit pas de dire que la différence dans les scores en lecture trouvés dans cette expérience applique à l'ensemble de la population en général? Parce que l'écart type de population,
est inconnue et vous avez estimé que la norme de l'échantillon-type (s), Vous devez utiliser le t-la répartition plutôt que Z-Répartition de trouver votre p-valeur. Utilisation du dessous t-table, vous regardez jusqu'à 1,36 sur la t-répartition de 10 - 1 = 9 degrés de liberté pour calculer la p-valeur.

La p-dans ce cas, la valeur est supérieure à 0,10 (et donc supérieur à 0,05), parce que 1,36 est plus petit que (ou à la gauche de) la valeur de 1,38 sur la table, et par conséquent son p-valeur est supérieure à 0,10 (le p-valeur pour le titre de la colonne correspondant à 1,38).
Parce que le p-valeur est supérieure à 0,05, vous ne parvenez pas à rejeter H0- vous ne disposez pas de suffisamment de preuves que la différence moyenne dans les scores entre la méthode de l'ordinateur et la méthode phonétique est nettement supérieure à 0. Toutefois, cela ne signifie pas nécessairement une réelle différence est pas présent dans la population de tous les élèves. Mais le chercheur ne peut pas dire que le jeu d'ordinateur est une meilleure méthode de lecture sur la base de cet échantillon de 10 étudiants.
Vous pourriez vous demander, “ Hé, l'échantillon moyenne des différences est de 2,0 ce qui montre que la méthode de l'ordinateur était mieux que la méthode phonétique. Pourquoi le test d'hypothèse ne rejette H0 depuis 2.0 est évidemment supérieure à 0 ° 148?; Parce que dans ce cas, 2.0 est pas significativement supérieure à 0. Vous devez également tenir compte de la variation en utilisant l'erreur-type et la t la distribution de pouvoir dire quelque chose à propos de l'ensemble de la population d'étudiants.
-
 Test d'hypothèse pour des données aberrantes
Test d'hypothèse pour des données aberrantes -
 techniques") Analyse exploratoire des données quantitatives (eda) techniques
Analyse exploratoire des données quantitatives (eda) techniques -
 Comment comparer les données appariées avec r
Comment comparer les données appariées avec r -
 Calculer les statistiques de test appropriées pour les deux grandes populations indépendantes avec des variances inégales
Calculer les statistiques de test appropriées pour les deux grandes populations indépendantes avec des variances inégales -
 Calculer des statistiques de test pour les deux populations indépendantes avec des variances inégales et au moins un petit échantillon
Calculer des statistiques de test pour les deux populations indépendantes avec des variances inégales et au moins un petit échantillon - Tirer des conclusions sur une population en utilisant des intervalles de confiance et tests d'hypothèses
Vous utilisez des tests d'hypothèses de contester si certains prétendent d'une population est vrai (par exemple, une demande que 90 pour cent des Américains possèdent un téléphone portable). Pour tester une hypothèse statistique, vous prenez…
Dans les statistiques, htests ypothesis se réfère au processus de choix entre hypothèses concurrentes sur une distribution de probabilités, basée sur les données observées à partir de la distribution. Il est un sujet de base et une partie…
Vous pouvez tester des hypothèses à propos de deux moyens de population où les populations sont indépendants les uns des autres, mais ils ont la taille et la variance égale. Avec une population égale écarts, la statistique de test nécessite…
Comparé à d'autres types de tests d'hypothèses, la construction de la statistique de test pour analyse de la variance est assez complexe. La première étape dans la recherche de la statistique de test est de calculer la somme des carrés des…
De loin la mesure la plus courante de variation pour les données numériques dans les statistiques est l'écart type. La écart-type comment les mesures sont concentrés les données autour de la signification la plus concentrée, plus l'écart…
Vous pouvez comparer les données numériques pour les deux populations ou des groupes (tels que les niveaux de cholestérol chez les hommes par rapport aux femmes, ou des niveaux de revenu pour l'école secondaire par rapport diplômés des…
Comparé à d'autres types de tests d'hypothèses, la construction de la statistique de test pour analyse de la variance est assez complexe. Vous construisez la statistique de test (ou statistique F) à partir de l'erreur quadratique moyenne (MSE)…
Vous pouvez utiliser un test d'hypothèse à examiner ou contester une réclamation statistiques sur une moyenne de population si la variable est numérique (par exemple, l'âge, le revenu, le temps, et ainsi de suite) et une seule population ou un…
Vous pouvez utiliser un test d'hypothèse à tester une réclamation statistiques sur la proportion de la population lorsque la variable est catégorique (par exemple, le sexe ou l'appui / opposition) et une seule population ou un groupe est à…
Lorsque vous utilisez une statistique de test pour une moyenne de la population, il ya deux cas où vous devez utiliser la t-au lieu de la répartition Z-distribution. Le premier cas est celui où la taille de l'échantillon est faible (en dessous…
Un moyen important de tirer des conclusions sur les propriétés d'une population est avec des tests d'hypothèses. Tu peux utiliser tests d'hypothèses à comparer une mesure de la population à une valeur spécifiée, comparer les mesures de deux…
Les non appariés (indépendant-échantillon), l'un des tests t-Way ANOVA, ANCOVA, et leurs homologues non paramétriques traitent avec des comparaisons entre deux ou plusieurs groupes de indépendant échantillons de données, tels que les…
Vous pouvez exécuter les test t de Student en utilisant un logiciel statistique typique et interpréter la sortie produite. Dans cet exemple, vous serez en utilisant le logiciel OpenStat.L'idée de base d'un test tTous les tests t de Student pour…
Dans la biostatistique, lorsque l'on compare les mesures appariées (tels que les changements entre deux points dans le temps pour le même sujet) en utilisant un test t de Student apparié, le taille de l'effet est exprimée comme le rapport de #…