Clustering dans nosql
Bases de données NoSQL sont bien adaptés à de très grands ensembles de données. Clones Bigtable comme HBase ne font pas exception. Vous aurez probablement à utiliser plusieurs serveurs de matières premières bon marché dans un cluster unique plutôt qu'une machine très puissante. Ceci est parce que vous pouvez obtenir une meilleure performance globale pour un dollar en utilisant de nombreux serveurs des produits de base, plutôt qu'un seul, puissant serveur beaucoup plus coûteux.
En plus d'être capable d'évoluer rapidement, serveurs de matières premières peu coûteuses peuvent également rendre votre service de base de données plus résistants et donc aider à éviter les défaillances matérielles. C'est parce que vous avez d'autres serveurs pour prendre en charge le service si la carte mère d'un serveur unique échoue. Cela ne veut pas le cas avec un seul gros serveur.
La figure montre une configuration hautement disponible HBase avec un exemple de données réparties entre les serveurs.
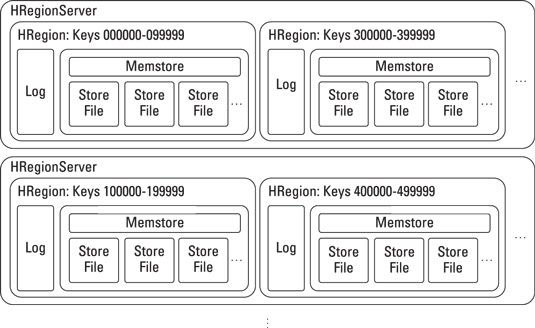
Le diagramme montre deux noeuds (HRegionServers) dans une configuration hautement disponibles, chacun agissant comme une sauvegarde pour l'autre.
Dans de nombreuses configurations de production, vous voudrez peut-être au moins trois noeuds pour la haute disponibilité pour assurer deux pannes de serveur proches dans le temps à l'autre peut être manipulé. Ce ne sont pas aussi rares que vous ne le pensez! Conseils varie selon Bigtable- par exemple, HBase recommande cinq nœuds comme un minimum pour un cluster:
Chaque serveur de région gère son propre jeu de clés.
Concevoir une clé # 8208 stratégie d'allocation ligne est importante car elle dicte la façon dont la charge est répartie sur la grappe.
| Chaque région possède son propre journal d'écriture et en magasin # 8208-mémoire.
Dans HBase, toutes les données sont écrites dans un magasin de # 8208-mémoire, et plus tard de ce magasin est écrit sur le disque. Sur disque, ces magasins sont appelés de stocker des fichiers.
HBase interprète de stocker des fichiers comme des fichiers simples, mais en réalité, ils sont distribués dans les morceaux à travers un système Hadoop Distributed File (HDFS). Cette offre pour une grande acquisition et la vitesse de récupération, car toutes les grandes opérations d'E / S sont réparties sur de nombreuses machines.
Afin de maximiser la disponibilité des données, par défaut, Hadoop gère trois copies de chaque fichier de données. Les grandes installations ont
Une copie primaire
Une réplique dans le même rack
Un autre réplique dans un autre rack
Avant Hadoop 2.0, Namenodes ne pouvait pas être hautement disponible. Ceux-ci ont maintenu une liste de tous les serveurs actifs dans le cluster. Ils étaient, par conséquent, d'un point de défaillance unique. Depuis Hadoop 2.0, cette limite ne existe plus.
-
 3 configurations de cluster Hadoop
3 configurations de cluster Hadoop -
 Zookeeper bases de données NoSQL Apache et
Zookeeper bases de données NoSQL Apache et - Bigtable / large magasin de fonctionnalités de bases de données NoSQL dans la colonne
-
 Mises à jour de points de reprise dans Hadoop système de fichiers distribué
Mises à jour de points de reprise dans Hadoop système de fichiers distribué -
 fédération") Hadoop système de fichiers distribué (HDFS) fédération
Hadoop système de fichiers distribué (HDFS) fédération -
 haute disponibilité") Hadoop système de fichiers distribué (HDFS) haute disponibilité
Hadoop système de fichiers distribué (HDFS) haute disponibilité
Le système de fichiers distribués Hadoop est un résilient approche polyvalente, cluster à la gestion des fichiers dans un environnement grand de données. HDFS est pas la destination finale pour les fichiers. Au contraire, il est un service de…
Capacités de lecture rapide de clé-valeur magasins découlent de leur utilisation de clés bien définis. Ces touches sont généralement hachés, qui donne un magasin clé-valeur d'une manière très prévisible de déterminer quelle partition…
Pour permettre une meilleure compréhension des alternatives SQL-sur-Hadoop Hive, il pourrait être utile d'examiner une amorce sur le traitement massivement parallèle (MPP) des bases de données en premier.Apache Hive est posée sur le dessus du…
Les nœuds maîtres dans les clusters Hadoop distribués abritent les différents services de stockage et de gestion de traitement, décrits dans cette liste, pour l'ensemble du cluster Hadoop. La redondance est essentiel pour éviter les points de…
RegionServers sont les processus logiciels (souvent appelés démons) vous activez pour stocker et récupérer des données dans HBase (Base de données Hadoop). Dans les environnements de production, chaque RegionServer est déployé sur son propre…
Distributed File System Hadoop (HDFS) est conçu pour stocker des données sur peu coûteux et plus fiable, le matériel. Peu coûteux a une jolie bague à elle, mais elle soulève des préoccupations quant à la fiabilité du système dans son…
Dans un cluster Hadoop, chaque noeud de données (également connue en tant que nœud esclave) Exécute un processus de fond nommée DataNode. Ce processus d'arrière-plan (également connu en tant que démon) Garde la trace des tranches de données…
Dans un univers Hadoop, nœuds esclaves sont où les données Hadoop est stockée et où le traitement de données a lieu. Les services suivants permettent nœuds esclaves pour stocker et traiter les données:NodeManager: Coordonne les ressources…
Lorsque l'on considère les capacités de Hadoop pour travailler avec des données structurées (ou de travailler avec des données de tout type, d'ailleurs), rappelez-vous les caractéristiques de base de Hadoop: Hadoop est, d'abord et avant tout,…
Ici, vous trouverez comment télécharger et déployer HBase en mode autonome. Il est incroyablement simple à installer HBase et commencer à utiliser la technologie. Il suffit de garder à l'esprit que HBase est généralement déployée sur un…
Hadoop est plus que MapReduce et HDFS (Distributed File System Hadoop): Il est également une famille de projets connexes (un écosystème, vraiment) pour le calcul distribué et le traitement de données à grande échelle. La plupart (mais pas…
HBase (Base de données Hadoop) est une implémentation Java de BigTable de Google. Google définit comme un BigTable “ clairsemée, distribué, carte triés multidimensionnelle persistante ”. Il est une définition assez concise, mais…
Zookeeper est un cluster de serveurs distribués qui fournit collectivement des services de coordination et de synchronisation fiables pour des applications en cluster. Certes, le nom “ Zookeeper ” peut sembler à première vue être un…
Les bases de données en colonnes peuvent être très utiles dans votre grand projet de données. Bases de données relationnelles sont orientée rangée, que les données de chaque ligne d'une table sont stockées ensemble. Dans une forme de…