Définir les formats d'enregistrement de la table dans la ruche
La technologie Java qui utilise la ruche pour traiter les enregistrements et les mapper aux types de données de colonnes dans les tables de la ruche est appelée SerDe, qui est court pour SerializerDesérialiseur. La figure illustre comment SerDes sont endettés et il vous aidera à comprendre comment Hive garde formats de fichier séparé de formats d'enregistrement.
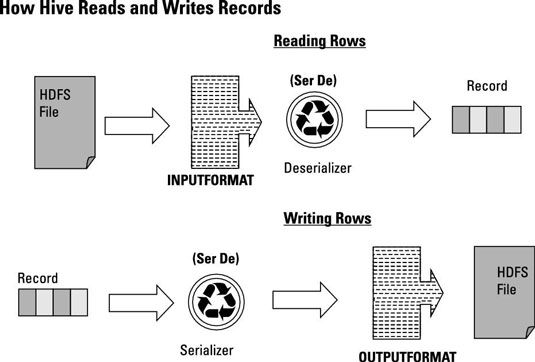
Donc la première chose à remarquer est le InputFormat objet. InputFormat vous permet de spécifier votre propre classe Java si vous voulez Hive à lire à partir d'un format de fichier différent. Stocké comme TEXTFILE est plus facile que l'écriture InputFormat org.apache.hadoop.mapred.TextInputFormat - l'arbre entier Java package et le nom de classe pour l'objet de format de fichier d'entrée de texte par défaut, en d'autres termes.
La même chose est vraie de la FORMAT DE SORTIE objet. Au lieu d'écrire sur l'ensemble de Java arbre de package et la classe nom, le Stocké comme TEXTFILE déclaration prend soin de tout cela pour vous.
Hive vous permet de séparer votre format d'enregistrement de votre format de fichier, donc exactement comment vous y parvenir? Simple, soit vous remplacez Stocké comme TEXTFILE avec quelque chose comme Stocké comme rcfile, ou vous pouvez créer votre propre classe Java et de préciser les catégories d'entrée et de sortie à l'aide InputFormat packagepath.classname et OUTPUTFORMAT packagepath.classname.
Enfin notez que quand la ruche est en train de lire les données à partir de la HDFS (ou système de fichiers local), un désérialiseur Java formate les données dans un dossier qui correspond à des types de données de colonnes de table. Cela caractériser le flux de données pour une HiveQL SELECT déclaration. Quand la ruche est en train d'écrire des données, un sérialiseur Java accepte le dossier Hive utilise et la traduit telle que la FORMAT DE SORTIE classe peut écrire à HDFS (ou système de fichiers local).
Cela caractériser le flux de données pour une HiveQL CREATE TABLE AS-SELECT déclaration. Donc le InputFormat, FORMAT DE SORTIE et les objets SerDe permettent Hive pour séparer le format d'enregistrement de la table du format de fichier de la table.
Hive regroupe un certain nombre de SerDes pour vous de choisir, et vous trouverez un plus grand nombre disponible auprès de tiers, si vous recherchez en ligne. Vous pouvez également développer vos propres SerDes si vous avez un type de données plus inhabituel que vous souhaitez gérer avec une table Hive. (Exemples possibles ici sont des données vidéo et de données e-mail.)
Dans la liste suivante, quelques-uns des SerDes fournies avec Hive sont décrites ainsi comme une option tiers que vous pourriez trouver utiles.
LazySimpleSerDe: Le SerDe par défaut qui est utilisé avec le TEXTFILE formatage il serait utilisé avec our_first_table à partir de la liste suivante.
(UN) $ $ HIVE_HOME / bin ruche --service cli(B) ruche> set hive.cli.print.current.db = vrai-(C) ruche (par défaut)> CREATE DATABASE ourfirstdatabase-OKTime prise: 3.756 secondes(RÉ) ruche (par défaut)> UTILISATION ourfirstdatabase-OKTime prise: 0.039 secondes(E) ruche (ourfirstdatabase)> CREATE TABLE our_first_table (> Prénom STRING,> LastNameSTRING,> EmployeeId INT) -OKTime prise: 0,043 secondshive (ourfirstdatabase)> quit-(F) $ Ls /home/biadmin/Hive/warehouse/ourfirstdatabase.dbour_first_table
Il serait également être utilisé avec data_types_table à partir de la liste suivante.
$ ./hive --service Clihive> CREATE DATABASE data_types_db-OKTime prise de vue: 0,119 secondshive> UTILISATION data_types_db-OKTime prise: 0,018 secondes(1)Hive> CREATE TABLE data_types_table ((2) > Our_tinyint TINYINT COMMENT '1 octet entier signé »,(3) > Our_smallintSMALLINT COMMENT '2 octets signée entier »,(4) > Our_int INT COMMENT '4 octets entier signé »,(5) > Our_bigint BIGINTCOMMENT '8 octets entier signé »,(6) > Our_float FLOAT COMMENTAIRE «simple précision en virgule flottante»,(7) > Our_double DOUBLECOMMENT 'double précision en virgule flottante »,(8) > Our_decimal DECIMAL COMMENT 'basée précise le type décimal(9) > Java BigDecimal objet »,(10) > Our_timestamp TIMESTAMP COMMENT 'AAAA-MM-JJ HH: MM: SS.fffffffff "(11) > (9 décimale de précision) ',(12) > Our_boolean BOOLEAN COMMENT 'booléenne de type de données TRUE ou FALSE',(13) > Our_string STRINGCOMMENT 'Chaîne de caractères type de données »,(14) > BINARYCOMMENT our_binary 'Type de données pour le stockage arbitraire(15) > Nombre d'octets »,(16) > Array our_array
COMMENTAIRE «Une collection de champs de tous(17) > Le même type de données indexée par(18) > Un entier »,(19) > Our_map Map Commentaire »Une collection de clés, les couples de valeur(20) > Où la clé est une primitive(21) > Type et la valeur peut être(22) > Rien. Les données choisi(23) > Types pour les clés et valeurs(24) > Doit rester la même pour la carte »,(25) > Our_structSTRUCT (26) > COMMENT 'Un complexe de données imbriqué(27) > structure »,(28) > Our_union UNIONTYPE(29) > COMMENT 'un type de données complexe qui peut(30) > tenir une de ses données possibles(31) > Types at Once »)(32) > COMMENT 'Tableau illustrant tous les types de données Apache Hive »(33) > ROW format délimité(34) > FIELDS TERMINATED BY ','(35) > Articles de collection TERMINATED BY '|'(36) > Clés de MAP TERMINATED BY '^'(37) > LINES TERMINATED BY ' n'(38) > Stocké comme TEXTFILE(39) > TBLPROPERTIES («créateur» = «Bruce Brown ',' created_at '=' sam 21 septembre 20:46:32 EDT 2013») - OKTime prise: 0.886 secondes ColumnarSerDe: Utilisé avec le Rcfile le format.
RegexSerDe: Le SerDe d'expression régulière, qui est livré avec la ruche pour permettre l'analyse de fichiers de texte, RegexSerDe peut former une approche puissante pour la construction de données structurées dans des tables ruche des blogs non structurées, des fichiers semi-structurées journaux, e-mails, tweets et autres données de Média social. Les expressions régulières permettent d'extraire des informations significatives (une adresse e-mail, par exemple) avec HiveQL partir d'un document de texte non structuré ou semi-structuré incompatible avec SQL traditionnel et SGBDR.
HBaseSerDe: Inclus avec Hive à lui permet d'intégrer avec HBase. Vous pouvez stocker des tables ruche HBase en tirant parti de cette SerDe.
JSONSerDe: Un SerDe tiers pour la lecture et l'écriture des enregistrements de données JSON avec Hive. Vous pouvez trouver rapidement (via Google et GitHub) deux JSON SerDes par la recherche en ligne pour l'expression JSON serde pour ruche.
AvroSerDe: Inclus avec la ruche de sorte que vous pouvez lire et écrire des données dans les tableaux Avro ruche.
Examiner le manuel de langue DDL peut être très utile avant de commencer à créer vos tables.

Ici, vous importez la totalité de la base de données directement à partir de l'ordre de service MySQL dans la ruche et exécutez une requête HiveQL contre la base de données nouvellement importée sur Hadoop. La liste suivante vous montre…
Imaginez une base de données relationnelle utilisée par une société de service fictif qui a été pris (vous l'aurez deviné) les appels de service Apache Hadoop et veut maintenant déplacer certains de ses données vers Hadoop pour exécuter…
Prêt à plonger dans l'importation de données avec Sqoop? Commencez par jeter un oeil à la figure, qui illustre les étapes d'une opération typique Sqoop d'importation à partir d'un SGBDR ou un système d'entrepôt de données. Rien de trop…
Création d'un index est une pratique courante avec les bases de données relationnelles quand vous voulez accélérer l'accès à une colonne ou un ensemble de colonnes dans votre base de données. Sans index, le système de base de données doit…
Vous savez probablement déjà que les experts en modélisation de base de données relationnelle et la conception passent généralement beaucoup de leur temps à la conception des bases de données normalisées, ou schémas. Base de données…
La communauté Apache Hive vivante et active en permanence ajouters déjà à un vaste ensemble de fonctionnalités, ce qui rend la couverture exhaustive encore plus difficile. La liste qui suit résume quelques caractéristiques principales HiveQL…
Hbase magasins de données sont constitués d'une ou plusieurs tables qui sont indexées par les touches de ligne. Les données sont stockées dans des lignes avec des colonnes et rangées peut avoir plusieurs versions. Par défaut, le versioning…
Apache Hive est incontestablement interface d'interrogation de données la plus répandue dans la communauté Hadoop. À l'origine, les objectifs de conception pour la ruche étaient pas pour assurer la compatibilité de SQL complète et de haute…
SQuirreL SQL est un outil open source qui agit comme un client Hive. Vous pouvez télécharger ce client SQL universelle à partir du site SourceForge. Il fournit une interface utilisateur de ruche et simplifie les tâches de l'interrogation de…
Lorsque l'on considère les capacités de Hadoop pour travailler avec des données structurées (ou de travailler avec des données de tout type, d'ailleurs), rappelez-vous les caractéristiques de base de Hadoop: Hadoop est, d'abord et avant tout,…
Comme vous examinez les éléments de Apache Hive montrées, vous pouvez voir au bas cette ruche se trouve au sommet du système Hadoop Distributed File (HDFS) et les systèmes de MapReduce.Dans le cas de MapReduce, les figureshows deux composants…
HBase est écrit en Java, un langage élégant pour la construction de technologies distribuées comme HBase, mais le visage il - pas tout le monde qui veut prendre avantage des innovations Hbase est un développeur Java. Voilà pourquoi il ya un…
Hive est, une couche d'entreposage des données orientée lots construit sur les éléments de base de Hadoop (HDFS et MapReduce) et est très utile dans les grandes données. Il fournit aux utilisateurs qui connaissent SQL avec une mise en œuvre…
Pour construire un gabarit de trame pour les ruches, d'abord de le décomposer en ses composants individuels et suivez ces instructions sur la façon de réduire ces composants frame-jig.Lumber dans un magasin est identifié par son nominal taille,…