Hadoop système de fichiers distribué (HDFS) fédération
La solution à l'expansion des grappes Hadoop indéfiniment est de fédérer l'NameNode. Avant Hadoop 2 est entré en scène, les clusters Hadoop ont dû vivre avec le fait que NameNode placé des limites à la mesure dans laquelle ils pourraient évoluer. Peu de groupes ont pu évoluer au-delà de 3000 ou de 4000 nœuds.
La nécessité de NameNode de tenir des registres pour chaque bloc de données stockées dans le cluster avéré être le plus important facteur limitant une plus grande croissance de la grappe. Lorsque vous avez trop de blocs, il devient de plus en plus difficile pour le NameNode à l'échelle comme le cluster Hadoop échelles sur.
Plus précisément, vous devez définir HDFS de sorte que vous disposez de plusieurs instances de NameNode exécutant sur leurs propres nœuds, dédiés maître et puis faisant de chaque NameNode responsable que pour les blocs de fichiers dans son propre espace de nom.
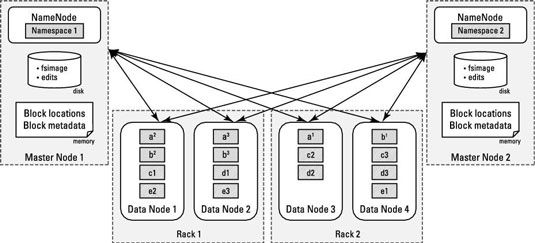
La figure montre des modèles de réplication de blocs de données dans HDFS. Vous pouvez voir un cluster Hadoop avec deux NameNodes servir un seul cluster. Les nœuds esclaves tous contiennent des blocs de deux espaces de noms.
-
 3 configurations de cluster Hadoop
3 configurations de cluster Hadoop -
 Mises à jour de points de reprise dans Hadoop système de fichiers distribué
Mises à jour de points de reprise dans Hadoop système de fichiers distribué -
") Les blocs de données dans le système de fichiers distribué Hadoop (HDFS)
Les blocs de données dans le système de fichiers distribué Hadoop (HDFS) -
 Traitement distribué Hadoop MapReduce avec
Traitement distribué Hadoop MapReduce avec -
 Nœuds de pointe dans des clusters Hadoop
Nœuds de pointe dans des clusters Hadoop - Les facteurs qui augmentent l'échelle d'analyse statistique dans Hadoop
Souvent dans l'enfance de Hadoop, une grande quantité de discussion a été centrée sur la représentation de la NameNode d'un point de défaillance unique. Hadoop, dans l'ensemble, a toujours eu une architecture robuste et tolérants aux pannes,…
Le système de fichiers distribués Hadoop est un résilient approche polyvalente, cluster à la gestion des fichiers dans un environnement grand de données. HDFS est pas la destination finale pour les fichiers. Au contraire, il est un service de…
Hadoop est conçu pour être déployé sur une grande grappe d'ordinateurs en réseau, avec des nœuds maîtres (qui accueillent les services qui contrôlent le stockage et le traitement de Hadoop) et nœuds esclaves (où les données sont stockées…
La façon HDFS a été mis en place, il se décompose très gros fichiers dans de grands blocs (par exemple, mesure 128 Mo), et stocke trois exemplaires de ces blocs sur les différents nœuds du cluster. HDFS n'a pas connaissance du contenu de ces…
Le NameNode agit comme le carnet d'adresses pour le système de fichiers distribués Hadoop (HDFS) parce qu'il sait non seulement ce qui bloque constituent des fichiers individuels, mais aussi où chacun de ces blocs et leurs répliques sont…
HDFS est l'une des deux principales composantes de l'Hadoop Structures à l'autre est le paradigme de calcul connu comme MapReduce. UN système de fichiers distribué est un système de fichier qui gère le stockage dans un cluster en réseau des…
Les nœuds maîtres dans les clusters Hadoop distribués abritent les différents services de stockage et de gestion de traitement, décrits dans cette liste, pour l'ensemble du cluster Hadoop. La redondance est essentiel pour éviter les points de…
Comme pour tout système distribué, le réseautage peut faire ou défaire un cluster Hadoop: Ne pas “ aller pas cher ”. Une grande partie de bavardage a lieu entre les nœuds maîtres et nœuds esclaves dans un cluster Hadoop qui est…
Distributed File System Hadoop (HDFS) est conçu pour stocker des données sur peu coûteux et plus fiable, le matériel. Peu coûteux a une jolie bague à elle, mais elle soulève des préoccupations quant à la fiabilité du système dans son…
Comme la mort et les impôts, les pannes de disque (et assez de temps donné, même les échecs nœud ou rack), sont inévitables dans le système Hadoop Distributed File (HDFS). Dans l'exemple montré, même si un seul rack devait échouer, le…
Dans un cluster Hadoop, chaque noeud de données (également connue en tant que nœud esclave) Exécute un processus de fond nommée DataNode. Ce processus d'arrière-plan (également connu en tant que démon) Garde la trace des tranches de données…
Dans un univers Hadoop, nœuds esclaves sont où les données Hadoop est stockée et où le traitement de données a lieu. Les services suivants permettent nœuds esclaves pour stocker et traiter les données:NodeManager: Coordonne les ressources…
Hadoop est plus que MapReduce et HDFS (Distributed File System Hadoop): Il est également une famille de projets connexes (un écosystème, vraiment) pour le calcul distribué et le traitement de données à grande échelle. La plupart (mais pas…
La dfsadmin outils sont un ensemble spécifique d'outils conçus pour vous aider à extirper des informations sur votre système Hadoop Distributed File (HDFS). Comme un bonus supplémentaire, vous pouvez les utiliser pour effectuer des opérations…