Système de fichiers distribué Hadoop (HDFS des) pour les grands projets de données
Le système de fichiers distribués Hadoop est un résilient approche polyvalente, cluster à la gestion des fichiers dans un environnement grand de données. HDFS est pas la destination finale pour les fichiers. Au contraire, il est un service de données qui offre un ensemble unique de capacités nécessaires lorsque les volumes de données et la vitesse sont élevés. Parce que les données sont écrites une fois et ensuite lu de nombreuses fois par la suite, plutôt que de les en lecture écriture constants d'autres systèmes de fichiers, HDFS est un excellent choix pour soutenir grande analyse des données.
Big NameNodes de données
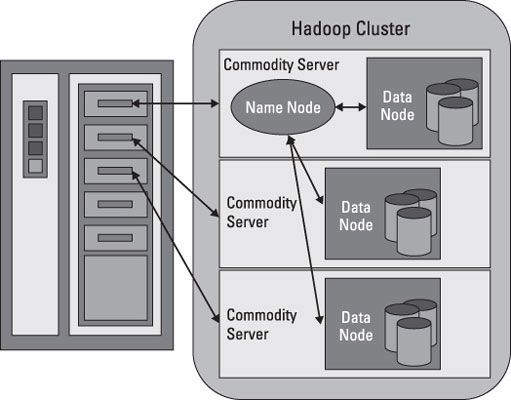
HDFS fonctionne en brisant des fichiers volumineux en plus petits blocs. Les blocs sont stockés sur des nœuds de données, et il est de la responsabilité du NameNode de savoir ce que les blocs sur lesquels noeuds de données constituent le dossier complet. Le NameNode agit également comme un “ agent de la circulation, ” la gestion de tous les accès aux fichiers.
La collection complète de tous les fichiers dans le cluster est parfois désigné comme le système de fichiers namespace. Il est le travail de l'NameNode de gérer cet espace de noms.
Même si il existe une forte relation entre la NameNode et les noeuds de données, elles opèrent dans un “ couplage lâche ” la mode. Cela permet aux éléments du cluster à se comporter de manière dynamique, l'ajout de serveurs que la demande augmente. Dans une configuration typique, vous trouvez un NameNode et éventuellement un noeud de données en cours d'exécution sur un serveur physique dans le rack. Autres serveurs fonctionnent nœuds de données seulement.
Les noeuds de données communiquent entre eux de sorte qu'ils puissent coopérer lors d'opérations de système de fichiers normales. Cela est nécessaire car les blocs pour un seul fichier sont susceptibles d'être stockées sur plusieurs nœuds de données. Depuis la NameNode est donc essentiel pour le bon fonctionnement du cluster, il peut et doit être répliquée pour se prémunir contre un point de défaillance unique.
Big noeuds de données
Nœuds de données ne sont pas intelligents, mais ils sont résilients. Dans le cluster HDFS, blocs de données sont répliquées sur plusieurs nœuds de données et l'accès est géré par le NameNode. Le mécanisme de réplication est conçu pour une efficacité optimale lorsque tous les noeuds de la grappe sont recueillies dans un rack. En fait, la NameNode utilise une “ en rack ID ” pour garder une trace des noeuds de données dans le cluster.
Nœuds de données fournissent également “ battement de coeur ” messages de détecter et d'assurer la connectivité entre le NameNode et les noeuds de données. Quand un battement de coeur est plus présente, l'NameNode annule le mappage du noeud de données du cluster et continue à fonctionner comme si rien ne se passait. Lorsque le rythme cardiaque revient, il est ajouté à la grappe de façon transparente par rapport à l'utilisateur ou à l'application.
L'intégrité des données est un élément clé. HDFS prend en charge un certain nombre de fonctions conçues pour assurer l'intégrité des données. Comme on pouvait s'y attendre, lorsque les fichiers sont divisés en blocs et ensuite distribués sur différents serveurs du cluster, toute variation dans le fonctionnement de tout élément pourrait affecter l'intégrité des données. HDFS utilise les journaux de transactions et la validation de la somme de contrôle pour assurer l'intégrité au sein du cluster.
Les journaux de transactions garder une trace de chaque opération et sont efficaces dans l'audit ou la reconstruction du système de fichier doit se produire quelque chose de fâcheux.
Validations checksum sont utilisés pour garantir le contenu des fichiers dans HDFS. Quand un client demande un fichier, il peut vérifier le contenu en examinant son contrôle. Si la somme de contrôle correspond, l'opération de fichier peut continuer. Sinon, une erreur est signalée. Fichiers de contrôle sont cachés pour aider à éviter la falsification.
Nœuds de données utilisent les disques locaux dans le serveur des produits de base pour la persistance. Tous les blocs de données sont stockés localement, principalement pour des raisons de performances. Les blocs de données sont répliquées sur plusieurs nœuds de données, de sorte que la défaillance d'un serveur peut ne pas nécessairement un fichier corrompu. Le degré de réplication, le nombre de nœuds de données, et l'espace de noms HDFS sont établis lorsque le cluster est mis en œuvre.
HDFS pour Big Data
HDFS aborde grands défis de données en brisant les fichiers dans une collection connexe de petits blocs. Ces blocs sont répartis entre les nœuds de données du cluster HDFS et sont gérés par le NameNode. Les tailles de bloc sont configurables et sont généralement de 128 mégaoctets (Mo) ou 256 Mo, ce qui signifie un fichier de 1 Go consomme huit blocs de 128 Mo pour ses besoins de stockage de base.
HDFS est élastique, de sorte que ces blocs sont répliquées dans tout le cluster en cas de défaillance d'un serveur. Comment ne HDFS garder une trace de toutes ces pièces? La réponse courte est le système de fichiers métadonnées.
Métadonnées est défini comme “ données sur les données ”.; Pensez à HDFS métadonnées comme un modèle pour fournir une description détaillée des éléments suivants:
Lorsque le fichier a été créé, consultée, modifiées, supprimées, etc.
Lorsque les blocs du fichier sont stockées dans la grappe
Qui a les droits pour afficher ou modifier le fichier
Combien de fichiers sont stockés sur le cluster
Combien de données existent nœuds dans le cluster
L'emplacement du journal de transactions de la grappe
HDFS métadonnées sont stockées dans le NameNode, et tandis que le groupe est en fonctionnement, toutes les métadonnées est chargé dans la mémoire physique du serveur NameNode. Comme on pouvait s'y attendre, plus la grappe, plus l'empreinte de métadonnées.
Que fait un serveur de bloc faire? Consultez la liste suivante:
Stocke les blocs de données dans le système de fichiers local du serveur. HDFS est disponible sur de nombreux systèmes d'exploitation différents et ont le même comportement sur Windows, Mac OS ou Linux.
Magasins les métadonnées d'un bloc dans le système de fichiers local basé sur le modèle de métadonnées dans le NameNode.
Effectue des validations périodiques de contrôle des fichiers.
Envoie des rapports réguliers à la NameNode sur ce que les blocs sont disponibles pour les opérations sur les fichiers.
Fournit des métadonnées et des données aux clients sur demande. HDFS soutient un accès direct aux noeuds de données de programmes d'application client.
Transmet les données vers d'autres noeuds de données basés sur une “ pipelining ” modèle.
Bloquer le placement sur les noeuds de données est essentielle pour la réplication des données et de soutien pour le pipelining de données. HDFS garde une réplique de chaque bloc localement. HDFS est sérieux au sujet de la réplication des données et la résilience.
-
 3 configurations de cluster Hadoop
3 configurations de cluster Hadoop -
 Mises à jour de points de reprise dans Hadoop système de fichiers distribué
Mises à jour de points de reprise dans Hadoop système de fichiers distribué -
 Clustering dans nosql
Clustering dans nosql -
") Les blocs de données dans le système de fichiers distribué Hadoop (HDFS)
Les blocs de données dans le système de fichiers distribué Hadoop (HDFS) -
 Traitement distribué Hadoop MapReduce avec
Traitement distribué Hadoop MapReduce avec -
 fédération") Hadoop système de fichiers distribué (HDFS) fédération
Hadoop système de fichiers distribué (HDFS) fédération
Souvent dans l'enfance de Hadoop, une grande quantité de discussion a été centrée sur la représentation de la NameNode d'un point de défaillance unique. Hadoop, dans l'ensemble, a toujours eu une architecture robuste et tolérants aux pannes,…
IBM a une longue histoire de collaboration avec SQL et de la technologie de base de données. En accord avec cette histoire, la solution d'IBM pour SQL sur Hadoop exploite des composants de ses technologies de base de données relationnelles qui…
Prêt à plonger dans l'importation de données avec Sqoop? Commencez par jeter un oeil à la figure, qui illustre les étapes d'une opération typique Sqoop d'importation à partir d'un SGBDR ou un système d'entrepôt de données. Rien de trop…
La façon HDFS a été mis en place, il se décompose très gros fichiers dans de grands blocs (par exemple, mesure 128 Mo), et stocke trois exemplaires de ces blocs sur les différents nœuds du cluster. HDFS n'a pas connaissance du contenu de ces…
Le NameNode agit comme le carnet d'adresses pour le système de fichiers distribués Hadoop (HDFS) parce qu'il sait non seulement ce qui bloque constituent des fichiers individuels, mais aussi où chacun de ces blocs et leurs répliques sont…
Hadoop, un framework logiciel open-source, utilise HDFS (le système de fichiers distribués Hadoop) et MapReduce pour analyser les données de grandes sur des groupes de produits de base sur le matériel qui est, dans un environnement de calcul…
HDFS est l'une des deux principales composantes de l'Hadoop Structures à l'autre est le paradigme de calcul connu comme MapReduce. UN système de fichiers distribué est un système de fichier qui gère le stockage dans un cluster en réseau des…
Les nœuds maîtres dans les clusters Hadoop distribués abritent les différents services de stockage et de gestion de traitement, décrits dans cette liste, pour l'ensemble du cluster Hadoop. La redondance est essentiel pour éviter les points de…
Distributed File System Hadoop (HDFS) est conçu pour stocker des données sur peu coûteux et plus fiable, le matériel. Peu coûteux a une jolie bague à elle, mais elle soulève des préoccupations quant à la fiabilité du système dans son…
Dimensionnement tout système de traitement de données est autant une science car elle est un art. Avec Hadoop, vous considérez les mêmes informations que vous le feriez avec une base de données relationnelle, par exemple. Plus important encore,…
Comme la mort et les impôts, les pannes de disque (et assez de temps donné, même les échecs nœud ou rack), sont inévitables dans le système Hadoop Distributed File (HDFS). Dans l'exemple montré, même si un seul rack devait échouer, le…
Dans un cluster Hadoop, chaque noeud de données (également connue en tant que nœud esclave) Exécute un processus de fond nommée DataNode. Ce processus d'arrière-plan (également connu en tant que démon) Garde la trace des tranches de données…
Dans un univers Hadoop, nœuds esclaves sont où les données Hadoop est stockée et où le traitement de données a lieu. Les services suivants permettent nœuds esclaves pour stocker et traiter les données:NodeManager: Coordonne les ressources…
La dfsadmin outils sont un ensemble spécifique d'outils conçus pour vous aider à extirper des informations sur votre système Hadoop Distributed File (HDFS). Comme un bonus supplémentaire, vous pouvez les utiliser pour effectuer des opérations…