Comment lancer une application de MapReduce Hadoop en 1
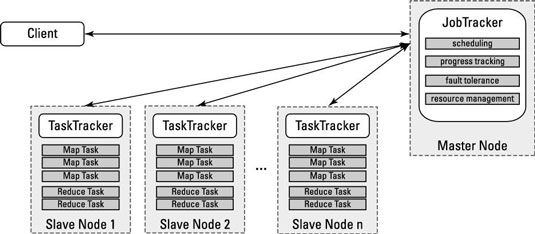
Pour voir comment le JobTracker et TaskTracker travaillent ensemble pour mener une action de MapReduce, jetez un oeil à l'exécution d'une application de MapReduce. La figure montre les interactions, et la liste d'étape suivante énonce le play-by-play:
L'application client soumet une demande de candidature à l'JobTracker.
Le JobTracker détermine le nombre de ressources de traitement sont nécessaires pour exécuter l'application entière.
Cela se fait en demandant les emplacements et les noms des fichiers et des blocs de données que l'application a besoin de la NameNode, et en calculant le nombre de tâches de carte et de réduire les tâches seront nécessaires pour traiter toutes ces données.
Le JobTracker regarde l'état des nœuds esclaves et files d'attente toutes les tâches de carte et de réduire les tâches d'exécution.
Comme fentes de traitement deviennent disponibles sur les nœuds esclaves, les tâches de carte sont déployés pour les nœuds esclaves.
Carte de tâches assignées aux blocs de données spécifiques sont assignés à nœuds où ces mêmes données sont stockées.
La tâche progrès surveille JobTracker, et dans le cas d'une défaillance de la tâche ou une défaillance de noeud, la tâche est redémarré sur le prochain emplacement disponible.
Si la même tâche échoue après quatre tentatives (qui est une valeur par défaut et peut être personnalisé), l'ensemble du travail échouera.
Après la carte tâches sont terminées, de limiter les tâches traiter le résultat provisoires ensembles des tâches de carte.
Le jeu de résultats est renvoyé à l'application cliente.
Applications plus complexes peuvent avoir plusieurs tours de map / reduce phases, où le résultat d'un tour est utilisé comme entrée pour le second tour. Cela est très courant aux charges de travail SQL-style, où il ya, par exemple, et rejoindre un groupe par les opérations.
-
 Traitement distribué Hadoop MapReduce avec
Traitement distribué Hadoop MapReduce avec - Les facteurs qui augmentent l'échelle d'analyse statistique dans Hadoop
-
 fédération") Hadoop système de fichiers distribué (HDFS) fédération
Hadoop système de fichiers distribué (HDFS) fédération -
 haute disponibilité") Hadoop système de fichiers distribué (HDFS) haute disponibilité
Hadoop système de fichiers distribué (HDFS) haute disponibilité -
 Hadoop MapReduce pour Big Data
Hadoop MapReduce pour Big Data -
 Comment lancer une application basée sur le fil-
Comment lancer une application basée sur le fil-
L'API MapReduce est écrit en Java, donc applications MapReduce sont basées sur Java principalement. La liste suivante indique les composants d'une application de MapReduce que vous pouvez développer:Driver (obligatoire): Ceci est la coquille de…
La façon HDFS a été mis en place, il se décompose très gros fichiers dans de grands blocs (par exemple, mesure 128 Mo), et stocke trois exemplaires de ces blocs sur les différents nœuds du cluster. HDFS n'a pas connaissance du contenu de ces…
Le NameNode agit comme le carnet d'adresses pour le système de fichiers distribués Hadoop (HDFS) parce qu'il sait non seulement ce qui bloque constituent des fichiers individuels, mais aussi où chacun de ces blocs et leurs répliques sont…
La planification des tâches et de suivi pour les grandes données sont des parties intégrantes de Hadoop MapReduce et peuvent être utilisés pour gérer les ressources et les applications. Les premières versions de Hadoop faveur d'un système de…
Hadoop, un framework logiciel open-source, utilise HDFS (le système de fichiers distribués Hadoop) et MapReduce pour analyser les données de grandes sur des groupes de produits de base sur le matériel qui est, dans un environnement de calcul…
Les nœuds maîtres dans les clusters Hadoop distribués abritent les différents services de stockage et de gestion de traitement, décrits dans cette liste, pour l'ensemble du cluster Hadoop. La redondance est essentiel pour éviter les points de…
Distributed File System Hadoop (HDFS) est conçu pour stocker des données sur peu coûteux et plus fiable, le matériel. Peu coûteux a une jolie bague à elle, mais elle soulève des préoccupations quant à la fiabilité du système dans son…
Parce que de nombreux déploiements Hadoop existants ne sont toujours pas encore à l'aide de Yet Another négociateur des ressources (FIL), de prendre un coup d'oeil à la façon dont Hadoop a réussi son traitement de données avant les jours de…
Dans un univers Hadoop, nœuds esclaves sont où les données Hadoop est stockée et où le traitement de données a lieu. Les services suivants permettent nœuds esclaves pour stocker et traiter les données:NodeManager: Coordonne les ressources…
Contrairement à d'autres FIL (Yet Another Négociateur ressources) des composants, aucun composant dans Hadoop 1 correspond directement à la maîtrise de l'application. En substance, ce travail est que la JobTracker fait pour chaque application,…
La composante de base de fil (Yet Another négociateur des ressources) est le gestionnaire de ressources, qui régit toutes les ressources de traitement de données dans le cluster Hadoop. Autrement dit, le gestionnaire de ressources est un…
Chaque nœud esclave dans un autre négociateur des ressources (FIL) a un démon Node Manager, qui agit comme un esclave pour le gestionnaire de ressources. Comme avec le TaskTracker, chaque nœud esclave dispose d'un service qu'il lie au service de…
Hadoop est une plate-forme de logiciel libre, open-source pour l'écriture et l'exécution d'applications qui traitent une grande quantité de données pour l'analyse prédictive. Il permet un traitement parallèle distribué de grands ensembles de…
Mis à part l'optimisation du code de l'application réelle avec MapReduce pour les grands projets de données, vous pouvez utiliser certaines techniques d'optimisation pour améliorer la fiabilité et la performance. Ils se répartissent en trois…