Entrée divise dans le MapReduce Hadoop de
La façon HDFS a été mis en place, il se décompose très gros fichiers dans de grands blocs (par exemple, mesure 128 Mo), et stocke trois exemplaires de ces blocs sur les différents nœuds du cluster. HDFS n'a pas connaissance du contenu de ces fichiers.
Dans FILS, quand un travail de MapReduce est lancé, le Gestionnaire de ressources (la gestion des ressources du cluster et centre de planification des tâches) crée un démon maître d'application pour occuper le cycle de vie de l'emploi. (En Hadoop 1, l'JobTracker surveillée emplois individuels ainsi que la manipulation de planification des tâches et la gestion des ressources du cluster.)
Une des premières choses que le Maître application ne déterminent qui est des blocs de fichiers sont nécessaires pour le traitement. Le Maître application demande les détails de la NameNode sur où les répliques des blocs de données nécessaires sont stockées. En utilisant les données de localisation pour les blocs de fichiers, l'application permet Maître des requêtes au Resource Manager ont des tâches de carte traitent des blocs spécifiques sur les nœuds esclaves où ils sont stockés.
La clé d'un traitement efficace de MapReduce est que, chaque fois que possible, les données sont traitées localement - sur le nœud esclave où il est stocké.
Avant de regarder comment les blocs de données sont traitées, vous devez regarder de plus près comment Hadoop stocke les données. Dans Hadoop, les fichiers sont composés de dossiers individuels, qui sont finalement traités un par un par des tâches de mapper.
Par exemple, l'ensemble des données de l'échantillon contient des informations sur les vols achevée dans les États-Unis entre 1987 et 2008.
Pour télécharger l'ensemble des données de l'échantillon, ouvrez le navigateur Firefox à partir de la machine virtuelle, et aller à la page de dataexpo.
Vous avez un gros fichier pour chaque année, et au sein de chaque fichier, chaque ligne représente un seul vol. En d'autres termes, une ligne représente un enregistrement. Maintenant, rappelez-vous que la taille de bloc pour le cluster Hadoop est de 64 Mo, ce qui signifie que les fichiers de données de lumière sont brisées en morceaux de 64 Mo exactement.
Voyez-vous le problème? Si chaque tâche de la carte traite tous les dossiers dans un bloc de données spécifique, ce qui arrive à ces dossiers qui dépassent les limites de bloc? Blocs de fichiers sont exactement 64 Mo (ou ce que vous définissez la taille de bloc de l'être), et parce que HDFS n'a aucune conception de ce qui est à l'intérieur des blocs de fichiers, il ne peut pas évaluer quand un enregistrement peut déborder dans un autre bloc.
Pour résoudre ce problème, Hadoop utilise une représentation logique des données stockées dans des blocs de fichiers, appelés scissions d'entrée. Quand un client de l'emploi de MapReduce calcule les scissions d'entrée, il figure où le premier enregistrement entier dans un bloc commence et où le dernier enregistrement dans le bloc se termine.
Dans les cas où le dernier enregistrement dans un bloc est incomplète, la scission d'entrée comprend des informations d'emplacement pour le bloc suivant et le décalage des données nécessaires pour compléter le dossier octet.
La figure montre cette relation entre les blocs de données et les fentes d'entrée.
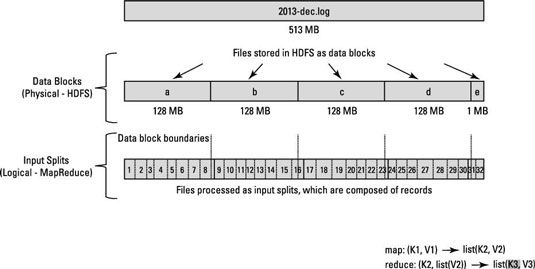
Vous pouvez configurer le démon demande de Maître (ou JobTracker, si vous êtes dans Hadoop 1) pour calculer l'entrée sépare la place du client de l'emploi, ce qui serait plus rapide pour le traitement des travaux d'un grand nombre de blocs de données.
Traitement de données MapReduce est entraîné par ce concept de scissions d'entrée. Le nombre de divisions d'entrée qui sont calculées pour une application spécifique détermine le nombre de tâches de mapper. Chacune de ces tâches de Mapper est affecté, si possible, à un nœud esclave où la scission d'entrée est stocké. Le gestionnaire de ressources (ou JobTracker, si vous êtes dans Hadoop 1) fait de son mieux pour assurer que l'entrée scissions sont traitées localement.
-
 Mises à jour de points de reprise dans Hadoop système de fichiers distribué
Mises à jour de points de reprise dans Hadoop système de fichiers distribué -
") Les blocs de données dans le système de fichiers distribué Hadoop (HDFS)
Les blocs de données dans le système de fichiers distribué Hadoop (HDFS) -
 Traitement distribué Hadoop MapReduce avec
Traitement distribué Hadoop MapReduce avec -
 fédération") Hadoop système de fichiers distribué (HDFS) fédération
Hadoop système de fichiers distribué (HDFS) fédération -
 haute disponibilité") Hadoop système de fichiers distribué (HDFS) haute disponibilité
Hadoop système de fichiers distribué (HDFS) haute disponibilité -
 pour les grands projets de données") Système de fichiers distribué Hadoop (HDFS des) pour les grands projets de données
Système de fichiers distribué Hadoop (HDFS des) pour les grands projets de données
Pour voir comment le JobTracker et TaskTracker travaillent ensemble pour mener une action de MapReduce, jetez un oeil à l'exécution d'une application de MapReduce. La figure montre les interactions, et la liste d'étape suivante énonce le…
Pour montrer comment les différents fils (Yet Another Négociateur ressources) composants fonctionnent ensemble, vous pouvez marcher à travers l'exécution d'une application. Pour les besoins du raisonnement, il peut être une application de…
Le NameNode agit comme le carnet d'adresses pour le système de fichiers distribués Hadoop (HDFS) parce qu'il sait non seulement ce qui bloque constituent des fichiers individuels, mais aussi où chacun de ces blocs et leurs répliques sont…
La planification des tâches et de suivi pour les grandes données sont des parties intégrantes de Hadoop MapReduce et peuvent être utilisés pour gérer les ressources et les applications. Les premières versions de Hadoop faveur d'un système de…
Hadoop, un framework logiciel open-source, utilise HDFS (le système de fichiers distribués Hadoop) et MapReduce pour analyser les données de grandes sur des groupes de produits de base sur le matériel qui est, dans un environnement de calcul…
Les nœuds maîtres dans les clusters Hadoop distribués abritent les différents services de stockage et de gestion de traitement, décrits dans cette liste, pour l'ensemble du cluster Hadoop. La redondance est essentiel pour éviter les points de…
Distributed File System Hadoop (HDFS) est conçu pour stocker des données sur peu coûteux et plus fiable, le matériel. Peu coûteux a une jolie bague à elle, mais elle soulève des préoccupations quant à la fiabilité du système dans son…
Parce que de nombreux déploiements Hadoop existants ne sont toujours pas encore à l'aide de Yet Another négociateur des ressources (FIL), de prendre un coup d'oeil à la façon dont Hadoop a réussi son traitement de données avant les jours de…
Comme la mort et les impôts, les pannes de disque (et assez de temps donné, même les échecs nœud ou rack), sont inévitables dans le système Hadoop Distributed File (HDFS). Dans l'exemple montré, même si un seul rack devait échouer, le…
Dans un cluster Hadoop, chaque noeud de données (également connue en tant que nœud esclave) Exécute un processus de fond nommée DataNode. Ce processus d'arrière-plan (également connu en tant que démon) Garde la trace des tranches de données…
Dans un univers Hadoop, nœuds esclaves sont où les données Hadoop est stockée et où le traitement de données a lieu. Les services suivants permettent nœuds esclaves pour stocker et traiter les données:NodeManager: Coordonne les ressources…
Contrairement à d'autres FIL (Yet Another Négociateur ressources) des composants, aucun composant dans Hadoop 1 correspond directement à la maîtrise de l'application. En substance, ce travail est que la JobTracker fait pour chaque application,…
La composante de base de fil (Yet Another négociateur des ressources) est le gestionnaire de ressources, qui régit toutes les ressources de traitement de données dans le cluster Hadoop. Autrement dit, le gestionnaire de ressources est un…
Chaque nœud esclave dans un autre négociateur des ressources (FIL) a un démon Node Manager, qui agit comme un esclave pour le gestionnaire de ressources. Comme avec le TaskTracker, chaque nœud esclave dispose d'un service qu'il lie au service de…