Rejoindre des tables avec ruche
Vous savez probablement déjà que les experts en modélisation de base de données relationnelle et la conception passent généralement beaucoup de leur temps à la conception des bases de données normalisées, ou schémas. Base de données normalisation est une technique qui protège contre la perte de données, la redondance et d'autres anomalies comme des données est mis à jour et récupéré.
Les experts suivent un certain nombre de règles pour arriver à une base de données normalisée, mais Règle 1 est que vous devez vous retrouver avec un groupe de tables. (Une grande table de stocker toutes vos données est pas normal -. Pun intended) Il ya des exceptions, en fonction du cas d'utilisation, mais la législation de nombreux tableaux sont généralement suivis de près, en particulier pour les bases de données qui prennent en charge les opérations ou traitement analytique (business intelligence, par example).
Lorsque vous commencez à interroger et analyser vos données, tables sont jointes sur la base des relations définies entre eux en utilisant SQL - ce qui signifie que les disques sont finalement occupé sur votre serveur lorsque vous démarrez la jointure de tables, et les disques occupés aboutissent généralement à des temps de réponse utilisateur plus lents . Cependant, les bonnes nouvelles sont que les SGBDR et EDW sont accordés pour faire rejoint aussi vite que possible.
Qu'est-ce que tout cela a à voir avec des jointures dans la ruche? Eh bien, rappelez-vous que le système d'exploitation sous-jacent de la ruche est Hadoop (surprise!): MapReduce est le moteur de joindre des tables, et le système de fichiers Hadoop (HDFS) est le stockage sous-jacent. Il est tout de bonnes nouvelles pour l'utilisateur qui veut créer, gérer et analyser de grandes tables avec Hive.
Le potentiel pour déverrouiller l'information qui est caché dans les structures massives de données est passionnant. Cependant, se joint à la ruche ne sont généralement pas fonctionner aussi bien comme ils le font dans le monde SGBDR / EDW, afin que les utilisateurs pour la première fois sont souvent surpris par le “ pokiness ” de la réponse du système.
Rappelez-vous que MapReduce et HDFS sont optimisés pour un débit avec de grandes analyses de données et que, dans ce monde, latences - temps de réponse de l'utilisateur, en d'autres termes - sont généralement élevés. Hive est conçu pour le traitement analytique lot de style, pas pour le traitement des transactions en ligne rapide. Les utilisateurs qui veulent la meilleure performance possible avec SQL sur Hadoop ont des solutions disponibles.
Gardez cette dynamique à l'esprit quand vous commencez à joindre des tables avec Hive. A noter également que les architectes de la ruche dénormaliser habituellement leurs bases de données dans une certaine mesure, afin d'avoir moins de tables plus grandes est monnaie courante. Voilà pourquoi les types de données complexes tels que STRUCTs et RÉSEAUs sont prévus. Vous pouvez utiliser ces types de données complexes à emballer beaucoup plus de données dans un seul tableau.
Car la table Hive lit et écrit via HDFS impliquent généralement très grands blocs de données, plus les données, vous pouvez gérer tout dans un tableau, meilleure est la performance globale.
Disque et l'accès au réseau est beaucoup plus lent que l'accès de la mémoire, afin de minimiser HDFS lit et écrit autant que possible.
Avec cette information de fond dans l'esprit, vous pouvez aborder de décision joint à la ruche. Heureusement, la communauté du développement ruche était réaliste et comprendre que les utilisateurs veulent et ont besoin pour joindre des tables avec HiveQL. Cette connaissance devient particulièrement important avec EDW augmentation. Les cas d'utilisation tels que “ queryable ” archives exigent souvent rejoint pour l'analyse des données.
Voici une ruche rejoindre exemple en utilisant des tables de données de vol. La liste vous montre comment créer et d'afficher une myflightinfo2007 table et un myflightinfo2008 table de la plus grande FlightInfo2007 et FlightInfo2008 tables. Le plan tout au long était d'utiliser le CTAS créé myflightinfo2007 et myflightinfo2008 tableaux pour illustrer la façon dont vous pouvez effectuer des jointures dans la ruche.
La figure montre le résultat d'une jointure interne avec le myflightinfo2007 et myflightinfo2008 tables en utilisant le client SQuirreL SQL.
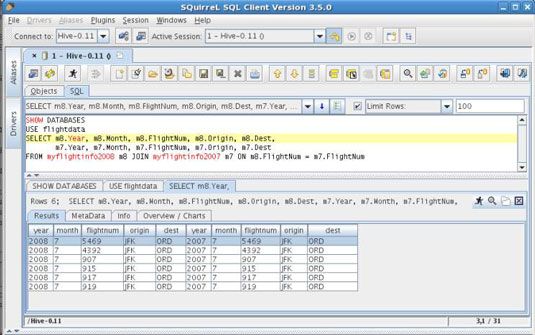
Supports Hive équi-jointures, un type spécifique de joindre qui utilise uniquement des comparaisons d'égalité dans le prédicat de jointure. (ON m8.FlightNum = m7.FlightNum est un exemple d'une équi-jointure) Autres comparateurs tels que Less Than (du lt;.) ne sont pas pris en charge. Cette restriction est seulement en raison de limitations sur le moteur de MapReduce sous-jacent. En outre, vous ne pouvez pas utiliser OU dans le SUR clause.
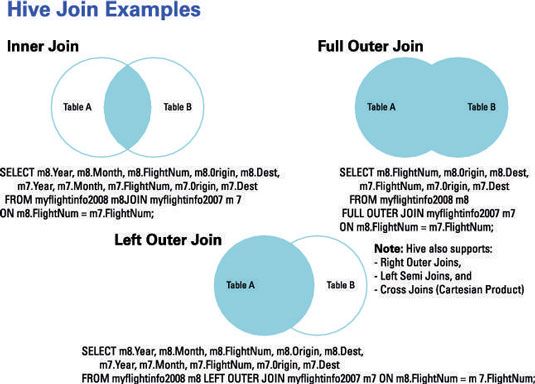
La figure illustre l'exemple précédent de la jointure interne et deux autres types Hive rejoindre. Notez que vous pouvez confirmer les résultats d'une jointure interne en examinant le contenu de la myflight2007 et myflight2008 tables.
La figure suivante illustre comment une jointure interne œuvres en utilisant un diagramme de Venn, au cas où vous n'êtes pas familier avec la technique. L'idée de base est que une jointure interne renvoie les enregistrements qui correspondent entre deux tables. Donc, une jointure interne est un outil d'analyse parfaite pour déterminer quels sont les mêmes vols de JFK (New York) à ORD (Chicago) en Juillet 2007 et Juillet 2008.
Optimisation de la ruche se joint est un sujet brûlant dans la communauté Hive. Pour plus d'informations sur les techniques d'optimisation en cours, voir la page d'optimisation d'inscription sur le wiki Hive.

Ici, vous importez la totalité de la base de données directement à partir de l'ordre de service MySQL dans la ruche et exécutez une requête HiveQL contre la base de données nouvellement importée sur Hadoop. La liste suivante vous montre…
Création d'un index est une pratique courante avec les bases de données relationnelles quand vous voulez accélérer l'accès à une colonne ou un ensemble de colonnes dans votre base de données. Sans index, le système de base de données doit…
La communauté Apache Hive vivante et active en permanence ajouters déjà à un vaste ensemble de fonctionnalités, ce qui rend la couverture exhaustive encore plus difficile. La liste qui suit résume quelques caractéristiques principales HiveQL…
Pour permettre une meilleure compréhension des alternatives SQL-sur-Hadoop Hive, il pourrait être utile d'examiner une amorce sur le traitement massivement parallèle (MPP) des bases de données en premier.Apache Hive est posée sur le dessus du…
Apache Hive est incontestablement interface d'interrogation de données la plus répandue dans la communauté Hadoop. À l'origine, les objectifs de conception pour la ruche étaient pas pour assurer la compatibilité de SQL complète et de haute…
SQuirreL SQL est un outil open source qui agit comme un client Hive. Vous pouvez télécharger ce client SQL universelle à partir du site SourceForge. Il fournit une interface utilisateur de ruche et simplifie les tâches de l'interrogation de…
Lorsque l'on considère les capacités de Hadoop pour travailler avec des données structurées (ou de travailler avec des données de tout type, d'ailleurs), rappelez-vous les caractéristiques de base de Hadoop: Hadoop est, d'abord et avant tout,…
Hadoop est plus que MapReduce et HDFS (Distributed File System Hadoop): Il est également une famille de projets connexes (un écosystème, vraiment) pour le calcul distribué et le traitement de données à grande échelle. La plupart (mais pas…
Comme vous examinez les éléments de Apache Hive montrées, vous pouvez voir au bas cette ruche se trouve au sommet du système Hadoop Distributed File (HDFS) et les systèmes de MapReduce.Dans le cas de MapReduce, les figureshows deux composants…
Hive est, une couche d'entreposage des données orientée lots construit sur les éléments de base de Hadoop (HDFS et MapReduce) et est très utile dans les grandes données. Il fournit aux utilisateurs qui connaissent SQL avec une mise en œuvre…
Vous pouvez utiliser un INSCRIPTION SELECT interroger de combiner des informations de plus d'une table MySQL. Avec JOIN, les tables sont combinés côte à côte, et les informations sont extraites des deux tables.Les tables sont combinés par…
MySQL est un système de gestion de bases de données relationnelles (SGBDR). Votre serveur MySQL peut gérer plusieurs bases de données en même temps. En fait, beaucoup de gens pourraient avoir différentes bases de données gérées par un seul…
SQL propose différents types de jointures, y compris le nom-colonne JOIN et intérieure, pour vous aider à accomplir votre tâche spécifique. Voici quelques exemples pour vous guider dans votre voyage de SQL.Nom-colonne rejoindreLa nom-colonne…
SQL prend en charge un certain nombre de types de jointures. Le meilleur de choisir dans une situation donnée dépend du résultat que vous essayez d'atteindre. Voici quelques détails pour vous aider à choisir celui qui vous avez besoin.CROSS…