Gardez une trace de blocs de données avec NameNode dans HDFS
Le NameNode agit comme le carnet d'adresses pour le système de fichiers distribués Hadoop (HDFS) parce qu'il sait non seulement ce qui bloque constituent des fichiers individuels, mais aussi où chacun de ces blocs et leurs répliques sont stockées. Quand un utilisateur stocke un fichier dans HDFS, le fichier est divisé en blocs de données, et de trois exemplaires de ces blocs de données sont stockées dans des nœuds esclaves à travers le cluster Hadoop.
Sommaire
Cela fait beaucoup de blocs de données pour garder la trace. Comme on pouvait s'y attendre, savoir où les corps sont enterrés rend le NameNode un composant extrêmement important dans un cluster Hadoop. Si le NameNode est indisponible, les applications ne peuvent pas accéder aux données stockées dans HDFS.
Si vous jetez un oeil à la figure suivante, vous pouvez voir le démon NameNode fonctionnant sur un serveur de nœud maître. Toutes les informations de cartographie portant sur les blocs de données et leurs fichiers correspondants sont stockées dans un fichier nommé.
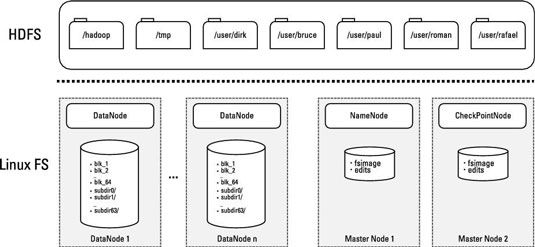
HDFS est un système de fichiers journalisé, ce qui signifie que toutes les modifications des données sont consignées dans un journal d'édition qui suit les événements depuis la dernière point de contrôle - la dernière fois que le journal d'édition a été fusionné avec. Dans HDFS, le journal d'édition est maintenue dans un fichier nommé qui est stocké sur le NameNode.
NameNode démarrage et d'exploitation
Pour comprendre comment le NameNode fonctionne, il est utile de jeter un oeil à la façon dont il démarre. Parce que le but de l'NameNode est d'informer les applications du nombre de blocs de données dont ils ont besoin pour traiter et de garder une trace de l'endroit exact où ils sont stockés, il a besoin de tous les mappings emplacements de bloc et bloc-à-fichier qui sont disponibles dans RAM.
Ce sont les étapes de la NameNode prend. Pour charger toutes les informations que le NameNode besoin après son démarrage, il arrive ceci:
Le NameNode charge le fichier en mémoire.
Le NameNode charge le fichier et re-joue les changements journalisés de mettre à jour les métadonnées de bloc qui est déjà en mémoire.
Les démons de DataNode envoyer les rapports de blocs de NameNode.
Pour chaque nœud esclave, il ya un rapport de bloc qui répertorie tous les blocs de données qui y sont stockées et décrit l'état de santé de chacun.
Après le processus de démarrage est terminé, le NameNode a une image complète de toutes les données stockées dans HDFS, et il est prêt à recevoir les demandes des clients Hadoop d'application.
Comme les fichiers de données sont ajoutés et supprimés en fonction des demandes des clients, les modifications sont enregistrées dans les volumes de disque de l'esclave nœuds, des mises à jour de journal sont apportées au fichier, et les modifications sont répercutées dans les emplacements de blocs et les métadonnées stockées dans la mémoire de l'NameNode.
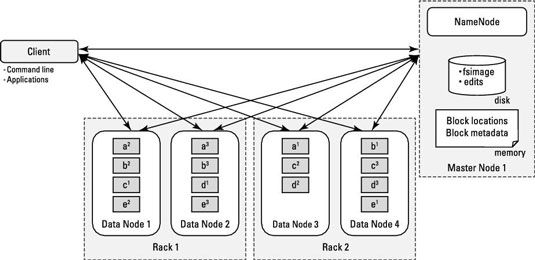
Tout au long de la vie de la grappe, les démons de DataNode envoyer les battements de coeur NameNode (un signal rapide) tous les trois secondes, indiquant qu'ils sont actifs. (Cette valeur par défaut est configurable.) Tous les six heures (à nouveau, un défaut configurable), les DataNodes envoyer le NameNode un rapport bloc indiquant quels blocs de fichiers sont sur leurs nœuds. De cette façon, l'NameNode a toujours une vue actuelle des ressources disponibles dans le cluster.
L'écriture de données
Pour créer de nouveaux fichiers dans HDFS, le processus suivant devra avoir lieu:
Le client envoie une demande à la NameNode pour créer un nouveau fichier.
Le NameNode détermine combien de blocs sont nécessaires, et le client bénéficie d'une bail pour la création de ces nouveaux blocs de fichiers dans le cluster. Dans le cadre de ce bail, le client dispose d'un délai pour compléter la tâche de création. (Ce délai garantit que l'espace de stockage ne sont pas prises par les applications clientes qui ont échoué.)
Le client écrit ensuite les premières copies des blocs de fichiers aux nœuds esclaves utilisant le bail attribué par le NameNode.
Le NameNode gère les demandes d'écriture et détermine où les blocs de fichiers et leurs répliques doivent être écrites, équilibrage disponibilité et les performances. La première copie d'un bloc de fichier est écrit dans une crémaillère, et les deuxième et troisième copies sont écrites sur un support différent de la première copie, mais dans différents noeuds esclaves dans le même rack. Cette disposition réduit le trafic réseau tout en garantissant qu'aucune des blocs de données sont sur le même point de défaillance.
Comme chaque bloc est écrit à HDFS, un processus spécial écrit les répliques restants aux autres nœuds esclaves identifiés par le NameNode.
Après les démons DataNode reconnaissent le fichier répliques de blocs ont été créés, l'application client ferme le dossier et informe le NameNode, qui ferme alors le bail ouvert.
Lecture des données
Pour lire des fichiers HDFS, le processus suivant devra avoir lieu:
Le client envoie une demande à la NameNode pour un fichier.
Le NameNode détermine quels blocs sont impliqués et choisit, sur la base de la proximité d'ensemble des blocs les uns aux autres et pour le client, le chemin d'accès le plus efficace.
Le client accède ensuite les blocs en utilisant les adresses indiquées par le NameNode.
Équilibrer les données dans le cluster Hadoop
Au fil du temps, avec des combinaisons de modèles de données ingestion inégales (où certains nœuds esclaves pourraient avoir plus de données écrites sur eux) ou défaillances de nœuds, les données sont susceptibles de devenir inégalement répartis entre les racks et nœuds esclaves dans votre cluster Hadoop.
Cette répartition inégale peut avoir un impact négatif sur la performance parce que la demande sur les nœuds esclaves individuels deviendra nœuds unbalanced- avec peu de données ne sera pas entièrement utilisé- et les nœuds avec de nombreux blocs seront surexploitées. (Note: La surexploitation et la sous-utilisation sont basées sur l'activité du disque, et non sur le processeur ou la RAM.)
HDFS inclut un utilitaire d'équilibrage de redistribuer blocs de nœuds esclaves galvaudé à ceux sous-utilisés tout en maintenant la politique de placer des blocs sur les différents nœuds et racks esclaves. Hadoop administrateurs devraient vérifier régulièrement la santé HDFS, et si les données devient inégalement répartis, ils devraient appeler l'utilitaire d'équilibrage.
NameNode conception de serveur maître
En raison de sa nature essentielle à la mission, le serveur maître exécutant le démon NameNode doit exigences matérielles nettement différentes de celles d'un nœud esclave. Plus important encore, les composants de niveau entreprise doivent être utilisés pour réduire au minimum la probabilité d'une panne. En outre, vous aurez besoin d'assez de RAM pour charger en mémoire toutes les données de métadonnées et l'emplacement de tous les blocs de données stockées dans HDFS.
-
 3 configurations de cluster Hadoop
3 configurations de cluster Hadoop -
 L'acide contre des magasins de données de base
L'acide contre des magasins de données de base -
 Mises à jour de points de reprise dans Hadoop système de fichiers distribué
Mises à jour de points de reprise dans Hadoop système de fichiers distribué -
") Les blocs de données dans le système de fichiers distribué Hadoop (HDFS)
Les blocs de données dans le système de fichiers distribué Hadoop (HDFS) -
 Traitement distribué Hadoop MapReduce avec
Traitement distribué Hadoop MapReduce avec -
 Nœuds de pointe dans des clusters Hadoop
Nœuds de pointe dans des clusters Hadoop
Tout administrateur Hadoop digne doit maîtriser un ensemble complet de commandes pour l'administration de cluster. La liste suivante récapitule les commandes les plus importantes, indiquant que la commande ne fait ainsi que la syntaxe et des…
La solution à l'expansion des grappes Hadoop indéfiniment est de fédérer l'NameNode. Avant Hadoop 2 est entré en scène, les clusters Hadoop ont dû vivre avec le fait que NameNode placé des limites à la mesure dans laquelle ils pourraient…
Souvent dans l'enfance de Hadoop, une grande quantité de discussion a été centrée sur la représentation de la NameNode d'un point de défaillance unique. Hadoop, dans l'ensemble, a toujours eu une architecture robuste et tolérants aux pannes,…
La Shell Hadoop est une famille de commandes que vous pouvez exécuter à partir de la ligne de commande de votre système d'exploitation. La coquille a deux ensembles de commandes: une pour la manipulation de fichiers (semblables dans le but et la…
Le système de fichiers distribués Hadoop est un résilient approche polyvalente, cluster à la gestion des fichiers dans un environnement grand de données. HDFS est pas la destination finale pour les fichiers. Au contraire, il est un service de…
Pour voir comment le JobTracker et TaskTracker travaillent ensemble pour mener une action de MapReduce, jetez un oeil à l'exécution d'une application de MapReduce. La figure montre les interactions, et la liste d'étape suivante énonce le…
La façon HDFS a été mis en place, il se décompose très gros fichiers dans de grands blocs (par exemple, mesure 128 Mo), et stocke trois exemplaires de ces blocs sur les différents nœuds du cluster. HDFS n'a pas connaissance du contenu de ces…
HDFS est l'une des deux principales composantes de l'Hadoop Structures à l'autre est le paradigme de calcul connu comme MapReduce. UN système de fichiers distribué est un système de fichier qui gère le stockage dans un cluster en réseau des…
Les nœuds maîtres dans les clusters Hadoop distribués abritent les différents services de stockage et de gestion de traitement, décrits dans cette liste, pour l'ensemble du cluster Hadoop. La redondance est essentiel pour éviter les points de…
Distributed File System Hadoop (HDFS) est conçu pour stocker des données sur peu coûteux et plus fiable, le matériel. Peu coûteux a une jolie bague à elle, mais elle soulève des préoccupations quant à la fiabilité du système dans son…
Comme la mort et les impôts, les pannes de disque (et assez de temps donné, même les échecs nœud ou rack), sont inévitables dans le système Hadoop Distributed File (HDFS). Dans l'exemple montré, même si un seul rack devait échouer, le…
Dans un cluster Hadoop, chaque noeud de données (également connue en tant que nœud esclave) Exécute un processus de fond nommée DataNode. Ce processus d'arrière-plan (également connu en tant que démon) Garde la trace des tranches de données…
Dans un univers Hadoop, nœuds esclaves sont où les données Hadoop est stockée et où le traitement de données a lieu. Les services suivants permettent nœuds esclaves pour stocker et traiter les données:NodeManager: Coordonne les ressources…
La dfsadmin outils sont un ensemble spécifique d'outils conçus pour vous aider à extirper des informations sur votre système Hadoop Distributed File (HDFS). Comme un bonus supplémentaire, vous pouvez les utiliser pour effectuer des opérations…