Bases de données de traitement massivement parallèle
Pour permettre une meilleure compréhension des alternatives SQL-sur-Hadoop Hive, il pourrait être utile d'examiner une amorce sur le traitement massivement parallèle (MPP) des bases de données en premier.
Apache Hive est posée sur le dessus du système Hadoop Distributed File (HDFS) et le système de MapReduce et présente une interface de programmation SQL-like à vos données (HiveQL, pour être précis). Cette combinaison de technologies Hadoop déployé sur un cluster est similaire aux bases de données de MPP qui ont existé pendant un certain temps sur le marché informatique.
MPP bases de données fournissent une interface SQL et un système de gestion de base de données relationnelles (SGBDR) fonctionnant sur une grappe de serveurs en réseau entre elles par une interconnexion à haute vitesse. La figure montre les composants d'un SGBDR qui sont généralement inclus dans les solutions SQL-sur-Hadoop.
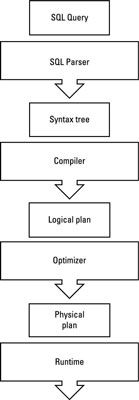
Systèmes de données relationnelles ont considérablement évolué à un point où les meilleures pratiques ont émergé parmi la plupart des offres en termes d'une infrastructure optimale d'exécution des requêtes. La figure montre cela en termes de flux d'une requête comme il est traité par un moteur de SGBDR.
Premièrement, le texte de la requête est analysée et comprise. Puis l'arbre de syntaxe de la requête est compilée dans un plan d'exécution logique, qui est ensuite optimisée pour former le plan d'exécution physique final, qui est ensuite exécuté par le runtime. Pour la plupart des solutions SQL-sur-Hadoop, vous voyez des composants similaires déployés dans Hadoop.
MPP grappes sont généralement désignés comme ayant une architecture partagée-Rien, parce que chaque système a son propre processeur, la mémoire et le disque. Cependant, à travers les logiciels de base de données à haute vitesse et des interconnexions, les fonctions du système dans son ensemble et peuvent évoluer que de nouveaux serveurs sont ajoutés à la grappe. L'ensemble du système est explicitement réglé pour fournir une réponse de requête rapide, interactif.
MPP bases de données sont souvent plus flexible, évolutive et rentable que les SGBDR traditionnels, hébergés sur un grand serveur multiprocesseur.

Pour faire une longue histoire courte, Hive fournit Hadoop avec un pont vers le monde de SGBDR et fournit un dialecte SQL connu comme Hive Query Language (HiveQL), qui peut être utilisé pour effectuer des tâches de type SQL. Voilà les grandes…
Un des premiers cas d'utilisation de Hadoop dans l'entreprise était comme un moteur de transformation programmatique utilisé pour prétraiter les données à destination d'un entrepôt de données. Essentiellement, ce cas d'utilisation exploite la…
La solution à l'expansion des grappes Hadoop indéfiniment est de fédérer l'NameNode. Avant Hadoop 2 est entré en scène, les clusters Hadoop ont dû vivre avec le fait que NameNode placé des limites à la mesure dans laquelle ils pourraient…
IBM a une longue histoire de collaboration avec SQL et de la technologie de base de données. En accord avec cette histoire, la solution d'IBM pour SQL sur Hadoop exploite des composants de ses technologies de base de données relationnelles qui…
Avant vous pouvez exécuter votre premier script de cochon dans Hadoop, vous devez avoir une poignée sur la façon dont les programmes de porc peuvent être fournis avec le serveur de porc.Pig dispose de deux modes pour l'exécution de scripts:Mode…
Hadoop, un framework logiciel open-source, utilise HDFS (le système de fichiers distribués Hadoop) et MapReduce pour analyser les données de grandes sur des groupes de produits de base sur le matériel qui est, dans un environnement de calcul…
Pig latin est la langue pour les programmes de porc. Pig traduit le script Pig Latin en emplois MapReduce qu'il peut être exécuté dans clusters Hadoop. En venant avec Pig Latin, l'équipe de développement a suivi trois principes clés de la…
En 2010, EMC et VMware, les leaders du marché dans la prestation de l'informatique comme un service via le cloud computing, acquis Greenplum Corporation, les gens qui avaient obtenu gain de cause le produit MPP Greenplum Data Warehouse (DW) sur le…
Parce que de nombreux déploiements Hadoop existants ne sont toujours pas encore à l'aide de Yet Another négociateur des ressources (FIL), de prendre un coup d'oeil à la façon dont Hadoop a réussi son traitement de données avant les jours de…
Il ya des raisons impérieuses que SQL a su résister. L'industrie des TI a eu 40 ans d'expérience avec SQL, car il a d'abord été développé par IBM au début des années 1970. Avec l'augmentation de l'adoption de bases de données…
Lorsque l'on considère les capacités de Hadoop pour travailler avec des données structurées (ou de travailler avec des données de tout type, d'ailleurs), rappelez-vous les caractéristiques de base de Hadoop: Hadoop est, d'abord et avant tout,…
Hadoop est plus que MapReduce et HDFS (Distributed File System Hadoop): Il est également une famille de projets connexes (un écosystème, vraiment) pour le calcul distribué et le traitement de données à grande échelle. La plupart (mais pas…
Comme vous examinez les éléments de Apache Hive montrées, vous pouvez voir au bas cette ruche se trouve au sommet du système Hadoop Distributed File (HDFS) et les systèmes de MapReduce.Dans le cas de MapReduce, les figureshows deux composants…
Bases de données non relationnelles ne reposent pas sur la table / modèle clé endémique de SGBDR (systèmes de gestion de base de données relationnelle). En bref, les données de spécialité dans le grand monde de données exige de la…