Réplication de blocs de données dans le système de fichiers Hadoop distribué
Distributed File System Hadoop (HDFS) est conçu pour stocker des données sur peu coûteux et plus fiable, le matériel. Peu coûteux a une jolie bague à elle, mais elle soulève des préoccupations quant à la fiabilité du système dans son ensemble, en particulier pour assurer la haute disponibilité des données.
Planifier à l'avance pour un désastre, les cerveaux derrière HDFS ont pris la décision de mettre en place le système de sorte qu'il serait stocker trois (count 'em - trois) copies de chaque bloc de données.
HDFS suppose que chaque disque et chaque noeud esclave est intrinsèquement peu fiable, de sorte que, clairement, il faut prendre soin dans le choix où les trois copies des blocs de données sont stockés.
La figure montre comment les blocs de données à partir du fichier précédemment sont rayé dans le cluster Hadoop - ce qui signifie qu'ils sont répartis uniformément entre les nœuds esclaves de sorte qu'une copie du bloc sera toujours disponible indépendamment de pannes disque, noeud, ou en rack.
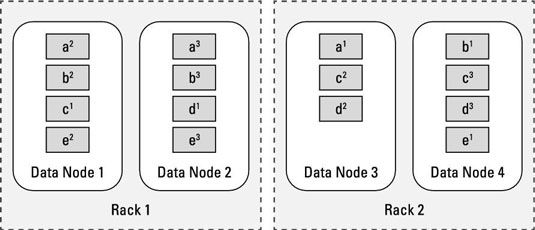
Le fichier a montré cinq blocs de données, étiquetées A, B, C, D, et E. Si vous jetez un oeil de plus près, vous pouvez voir ce groupe particulier est constitué de deux racks avec deux nœuds chacun, et que les trois exemplaires de chaque bloc de données ont été réparties entre les différents nœuds esclaves.
Chaque composant du cluster Hadoop est considéré comme un point de défaillance potentiel, alors quand HDFS stocke les répliques des blocs originaux à travers le cluster Hadoop, il essaie de faire en sorte que les répliques de blocs sont stockés dans différents points de défaillance.
Par exemple, jetez un oeil au bloc A. Au moment où il avait besoin d'être stocké, nœud Esclave 3 a été choisi, et le premier exemplaire du bloc A, il a été stocké. Pour de multiples systèmes en rack, HDFS détermine alors que les deux copies restantes du bloc A doivent être stockés dans un rack différent. Donc, la deuxième copie du bloc A est stocké sur le noeud Esclave 1.
La copie finale peut être stocké sur le même rack que le deuxième exemplaire, mais pas sur le même noeud esclave, il est stocké sur le noeud Esclave 2.
-
 3 configurations de cluster Hadoop
3 configurations de cluster Hadoop -
 Mises à jour de points de reprise dans Hadoop système de fichiers distribué
Mises à jour de points de reprise dans Hadoop système de fichiers distribué -
") Les blocs de données dans le système de fichiers distribué Hadoop (HDFS)
Les blocs de données dans le système de fichiers distribué Hadoop (HDFS) -
 Traitement distribué Hadoop MapReduce avec
Traitement distribué Hadoop MapReduce avec -
 fédération") Hadoop système de fichiers distribué (HDFS) fédération
Hadoop système de fichiers distribué (HDFS) fédération -
 haute disponibilité") Hadoop système de fichiers distribué (HDFS) haute disponibilité
Hadoop système de fichiers distribué (HDFS) haute disponibilité
Un principe de base de Hadoop est mise à l'échelle avec des nœuds esclaves supplémentaires pour répondre à l'augmentation de stockage de données et les exigences de traitement des minéraux. Dans un modèle de scale-out, vous devez examiner…
Le système de fichiers distribués Hadoop est un résilient approche polyvalente, cluster à la gestion des fichiers dans un environnement grand de données. HDFS est pas la destination finale pour les fichiers. Au contraire, il est un service de…
Hadoop est conçu pour être déployé sur une grande grappe d'ordinateurs en réseau, avec des nœuds maîtres (qui accueillent les services qui contrôlent le stockage et le traitement de Hadoop) et nœuds esclaves (où les données sont stockées…
La façon HDFS a été mis en place, il se décompose très gros fichiers dans de grands blocs (par exemple, mesure 128 Mo), et stocke trois exemplaires de ces blocs sur les différents nœuds du cluster. HDFS n'a pas connaissance du contenu de ces…
Le NameNode agit comme le carnet d'adresses pour le système de fichiers distribués Hadoop (HDFS) parce qu'il sait non seulement ce qui bloque constituent des fichiers individuels, mais aussi où chacun de ces blocs et leurs répliques sont…
Hadoop, un framework logiciel open-source, utilise HDFS (le système de fichiers distribués Hadoop) et MapReduce pour analyser les données de grandes sur des groupes de produits de base sur le matériel qui est, dans un environnement de calcul…
HDFS est l'une des deux principales composantes de l'Hadoop Structures à l'autre est le paradigme de calcul connu comme MapReduce. UN système de fichiers distribué est un système de fichier qui gère le stockage dans un cluster en réseau des…
Les nœuds maîtres dans les clusters Hadoop distribués abritent les différents services de stockage et de gestion de traitement, décrits dans cette liste, pour l'ensemble du cluster Hadoop. La redondance est essentiel pour éviter les points de…
Comme pour tout système distribué, le réseautage peut faire ou défaire un cluster Hadoop: Ne pas “ aller pas cher ”. Une grande partie de bavardage a lieu entre les nœuds maîtres et nœuds esclaves dans un cluster Hadoop qui est…
Dimensionnement tout système de traitement de données est autant une science car elle est un art. Avec Hadoop, vous considérez les mêmes informations que vous le feriez avec une base de données relationnelle, par exemple. Plus important encore,…
Comme la mort et les impôts, les pannes de disque (et assez de temps donné, même les échecs nœud ou rack), sont inévitables dans le système Hadoop Distributed File (HDFS). Dans l'exemple montré, même si un seul rack devait échouer, le…
Dans un cluster Hadoop, chaque noeud de données (également connue en tant que nœud esclave) Exécute un processus de fond nommée DataNode. Ce processus d'arrière-plan (également connu en tant que démon) Garde la trace des tranches de données…
Dans un univers Hadoop, nœuds esclaves sont où les données Hadoop est stockée et où le traitement de données a lieu. Les services suivants permettent nœuds esclaves pour stocker et traiter les données:NodeManager: Coordonne les ressources…
Chaque nœud esclave dans un autre négociateur des ressources (FIL) a un démon Node Manager, qui agit comme un esclave pour le gestionnaire de ressources. Comme avec le TaskTracker, chaque nœud esclave dispose d'un service qu'il lie au service de…