Nœuds esclaves dans les clusters Hadoop
Dans un univers Hadoop, nœuds esclaves sont où les données Hadoop est stockée et où le traitement de données a lieu. Les services suivants permettent nœuds esclaves pour stocker et traiter les données:
NodeManager: Coordonne les ressources pour un nœud et rapports esclave individuelle revenir à la Resource Manager.
ApplicationMaster: Suit la progression de toutes les tâches en cours d'exécution sur le cluster Hadoop pour une application spécifique. Pour chaque demande de client, le gestionnaire de ressources déploie une instance du service de ApplicationMaster dans un conteneur sur un nœud esclave. (Rappelez-vous que tout nœud exécutant le service NodeManager est visible à l'Resource Manager.)
Conteneurs: Une collection de toutes les ressources nécessaires pour exécuter les tâches individuelles pour une application. Quand une application est en cours d'exécution sur le cluster, les horaires Resource Manager les tâches de l'application à exécuter que des services de conteneurs sur les nœuds esclaves de la grappe.
TaskTracker: Gère le plan individuel et de réduire les tâches d'exécution sur un noeud esclave pour Hadoop 1 grappes. Dans Hadoop 2, ce service est obsolète et a été remplacée par les services de fil.
DataNode: Un service de HDFS qui permet à l'NameNode à des blocs de magasins sur le nœud esclave.
RegionServer: Stocke les données pour le système HBase. Dans Hadoop 2, HBase utilise Hoya, qui permet instances RegionServer être exploités dans des conteneurs.
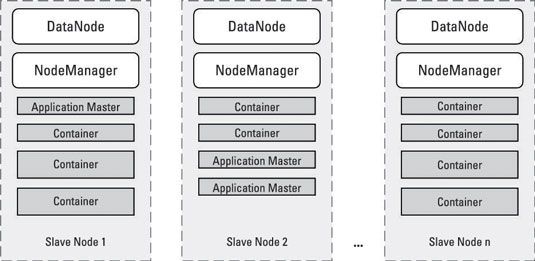
Ici, chaque nœud esclave est toujours en cours d'exécution d'une instance de DataNode (qui permet HDFS pour stocker et récupérer des blocs de données sur le nœud de l'esclave) et une instance NodeManager (qui permet au Resource Manager pour assigner des tâches d'application pour le noeud esclave pour le traitement). Les processus de conteneur sont des tâches individuelles pour des applications qui sont exécutés sur le cluster.
Chaque application en cours d'exécution a une tâche de ApplicationMaster dédié, qui gère également dans un récipient, et suit l'exécution de toutes les tâches d'exécution sur le cluster jusqu'à ce que l'application est terminée.
Avec Hadoop HBase sur 2, le modèle de conteneur est toujours suivi, comme vous pouvez le voir:
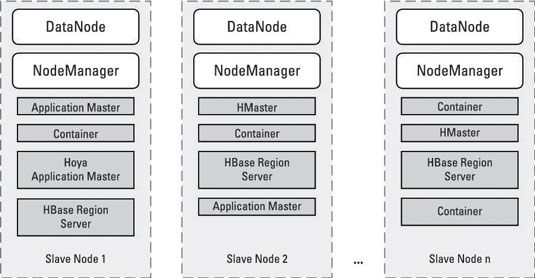
HBase sur Hadoop 2 est initiée par la Hoya demande Maître, qui demande des conteneurs pour les services de HMaster. (Vous avez besoin de services de HMaster multiples pour la redondance.) La Hoya demande Maître demande aussi des ressources pour RegionServers, qui exécutent également dans des conteneurs spéciaux.
La figure suivante montre les services déployés sur des nœuds Hadoop 1 esclaves.
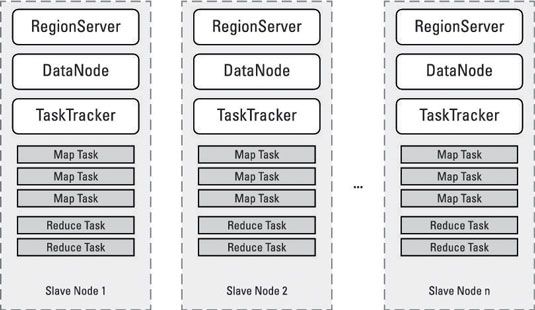
Pour Hadoop 1, chaque noeud esclave est toujours en cours d'exécution d'une instance de DataNode (qui permet HDFS pour stocker et récupérer des blocs de données sur le nœud esclave) et une instance TaskTracker (qui permet l'JobTracker attribuer carte et réduire les tâches au noeud esclave pour le traitement) .
Nœuds esclaves ont un nombre fixe de carte fentes et de réduire les fentes pour l'exécution du plan et de limiter les tâches respectivement. Si votre cluster fonctionne HBase, un certain nombre de vos nœuds esclaves devra lancer un service de RegionServer. Le plus de données que vous stockez dans HBase, les cas plus de RegionServer vous aurez besoin.
Les critères de matériels pour les nœuds esclaves sont assez différentes de celles pour le maître nodes- en fait, les critères ne correspondent pas à ceux trouvés dans les architectures de référence du matériel traditionnels pour les serveurs de données. Une grande partie du buzz autour de Hadoop est due à l'utilisation de matériel de base dans les critères de conception des clusters Hadoop, mais gardez à l'esprit que marchandise le matériel ne fait pas référence à du matériel de consommation de qualité.
Nœuds esclaves Hadoop nécessitent encore du matériel de classe entreprise, mais à l'extrémité inférieure du spectre des coûts, en particulier pour le stockage.



 fédération")
 haute disponibilité")
Hadoop est conçu pour être déployé sur une grande grappe d'ordinateurs en réseau, avec des nœuds maîtres (qui accueillent les services qui contrôlent le stockage et le traitement de Hadoop) et nœuds esclaves (où les données sont stockées…
Pour voir comment le JobTracker et TaskTracker travaillent ensemble pour mener une action de MapReduce, jetez un oeil à l'exécution d'une application de MapReduce. La figure montre les interactions, et la liste d'étape suivante énonce le…
Pour montrer comment les différents fils (Yet Another Négociateur ressources) composants fonctionnent ensemble, vous pouvez marcher à travers l'exécution d'une application. Pour les besoins du raisonnement, il peut être une application de…
La façon HDFS a été mis en place, il se décompose très gros fichiers dans de grands blocs (par exemple, mesure 128 Mo), et stocke trois exemplaires de ces blocs sur les différents nœuds du cluster. HDFS n'a pas connaissance du contenu de ces…
Le NameNode agit comme le carnet d'adresses pour le système de fichiers distribués Hadoop (HDFS) parce qu'il sait non seulement ce qui bloque constituent des fichiers individuels, mais aussi où chacun de ces blocs et leurs répliques sont…
La planification des tâches et de suivi pour les grandes données sont des parties intégrantes de Hadoop MapReduce et peuvent être utilisés pour gérer les ressources et les applications. Les premières versions de Hadoop faveur d'un système de…
Les nœuds maîtres dans les clusters Hadoop distribués abritent les différents services de stockage et de gestion de traitement, décrits dans cette liste, pour l'ensemble du cluster Hadoop. La redondance est essentiel pour éviter les points de…
Distributed File System Hadoop (HDFS) est conçu pour stocker des données sur peu coûteux et plus fiable, le matériel. Peu coûteux a une jolie bague à elle, mais elle soulève des préoccupations quant à la fiabilité du système dans son…
Parce que de nombreux déploiements Hadoop existants ne sont toujours pas encore à l'aide de Yet Another négociateur des ressources (FIL), de prendre un coup d'oeil à la façon dont Hadoop a réussi son traitement de données avant les jours de…
Comme la mort et les impôts, les pannes de disque (et assez de temps donné, même les échecs nœud ou rack), sont inévitables dans le système Hadoop Distributed File (HDFS). Dans l'exemple montré, même si un seul rack devait échouer, le…
Dans un cluster Hadoop, chaque noeud de données (également connue en tant que nœud esclave) Exécute un processus de fond nommée DataNode. Ce processus d'arrière-plan (également connu en tant que démon) Garde la trace des tranches de données…
Contrairement à d'autres FIL (Yet Another Négociateur ressources) des composants, aucun composant dans Hadoop 1 correspond directement à la maîtrise de l'application. En substance, ce travail est que la JobTracker fait pour chaque application,…
La composante de base de fil (Yet Another négociateur des ressources) est le gestionnaire de ressources, qui régit toutes les ressources de traitement de données dans le cluster Hadoop. Autrement dit, le gestionnaire de ressources est un…
Chaque nœud esclave dans un autre négociateur des ressources (FIL) a un démon Node Manager, qui agit comme un esclave pour le gestionnaire de ressources. Comme avec le TaskTracker, chaque nœud esclave dispose d'un service qu'il lie au service de…