Prenez HBase pour un essai
Ici, vous trouverez comment télécharger et déployer HBase en mode autonome. Il est incroyablement simple à installer HBase et commencer à utiliser la technologie. Il suffit de garder à l'esprit que HBase est généralement déployée sur un cluster de serveurs des produits de base, mais vous pouvez également facilement déployer HBase dans une configuration autonome à la place, à des fins d'apprentissage ou de démonstration.
Comme Hadoop, HBase supporte Linux principalement, mais vous pouvoir utiliser Windows dans des environnements non-production si vous d'abord télécharger Cygwin. Cygwin donne aux utilisateurs de Microsoft Windows un shell Unix avec toutes ses commandes et utilitaires. Donc, si vous suivez le guide de démarrage rapide, vous aurez envie de télécharger la dernière version HBase.
Vous aurez à choisir où installer HBase. Il se trouve, cependant, que si vous voulez que les choses fonctionnent en mode autonome, vous devrez éditer quelques fichiers avant de pouvoir réellement commencer HBase. Le premier fichier est indiqué dans la liste suivante. Les modifications que vous aurez envie de faire apparaissent en gras pour faire ressortir:
hbase.rootdir file: /// home / BiAdmin / ma-HBase locale / HBase-données hbase.cluster.distributed vrai hbase.zookeeper.property.clientPort 2222 Propriété de la config zoo.cfg de ZooKeeper. Le port où les clients se connecteront.hbase.zookeeper.property.dataDir / home / BiAdmin / ma-local-HBase / Zookeeper hbase.zookeeper.quorum BIVM
Vous spécifiez un répertoire dans le système de fichiers local pour stocker les données HBase. Dans les environnements de production, cette propriété serait pointer vers les HDFS pour le magasin de données. Par souci d'illustration, mode pseudo-distribué fera HBase pour démarrer une instance RegionServer, une instance MasterServer, et un processus Zookeeper.
En outre, vous devez spécifier le répertoire où Zookeeper va stocker ses données () et une liste de serveurs sur lesquels Zookeeper sera exécuté pour former un quorum (). Pour autonome, vous indiquez que le serveur de Zookeeper unique.
Premiers pas avec HBase en mode autonome est très simple en partie parce que HBase gère Zookeeper pour vous. Vous pouvez télécharger une Zookeeper presse distinct et pointer HBase à elle, mais pour les installations autonomes, vous trouverez beaucoup plus facile de laisser HBase gérer Zookeeper pour vous.
Pour cristalliser la décision de laisser HBase gérer Zookeeper pour vous, voici comment définir une variable d'environnement dans un autre fichier HBase. La liste suivante montre ce qui doit être ajouté:
# Parlez HBase si elle doit gérer sa propre instance de Zookeeper ou not.export HBASE_MANAGES_ZK = true # La mise en œuvre de Java à utiliser. Java 1.6 required.export JAVA_HOME = / opt / IBM / BigInsights / JDK
Vous devez vous assurer que vous pointez votre JDK choisi. Enfin, vous devez indiquer le nom de votre système Linux dans un autre fichier. (Dans un environnement de production totalement distribuée, ce fichier aurait une ligne par ligne liste de tous les serveurs sur lesquels HBase pouvez commencer le processus de RegionServer sur.)
Vous pouvez maintenant démarrer HBase et tester votre installation. Pour commencer HBase, utilisez le script, tels qu'énoncés dans la liste suivante.
$ Cd $ INSTALL_DIR / HBase-0.94.7 / bin $ ./start-hbase.shbivm: à partir gardien de zoo, l'exploitation forestière à /home/biadmin/my-local-hbase/hbase-0.94.7/bin/../logs/ HBase maître-BiAdmin-gardien de zoo-bivm.outstarting, journalisation /home/biadmin/my-local-hbase/hbase-0.94.7/bin/../logs/hbase-biadmin-master-bivm.outlocalhost: regionserver départ, journalisation /home/biadmin/my-local-hbase/hbase-0.94.7/bin/../logs/hbase-biadmin-regionserver-bivm.out
Notez que la première ligne dispose d'une commande cd (changement de répertoire) qui vous pousse à une variable d'environnement. Vous devez définir cette variable à votre répertoire d'installation réelle pour HBase ou tapez le chemin d'accès complet.
Ensuite, utilisez l'outil JConsole, fourni avec Java, pour effectuer une vérification rapide sur ce processus sont en cours après la fin du script. Vous pouvez démarrer l'outil JConsole en tapant la commande suivante: $ JAVA_HOME / bin / jconsole.
JConsole révèle que les trois processus que le script prétendait commencer sont en effet en cours d'exécution - le gardien du zoo, le maître, et les processus de RegionServer.
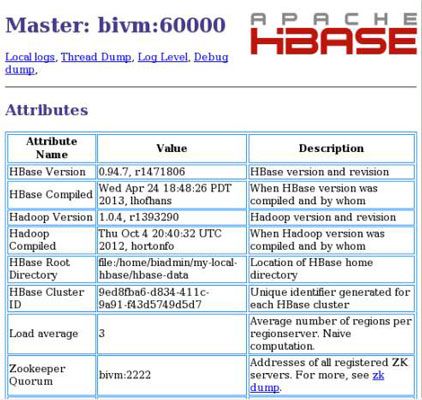
Pour mettre HBase à travers ses allures, vous interagissez avec les trois processus Hbase, en commençant par le MasterServer. Par défaut, le MasterServer rapports sur l'état du système par le biais d'une interface utilisateur du navigateur sur le numéro de port 60010. Dans l'exemple, vous pouvez confirmer que le MasterServer fonctionne correctement en entrant l'URL suivante dans un navigateur Web: http: // BIVM : 60010 /. Cela amène les informations que vous voyez ici.



HBase est une technologie puissante et flexible, mais accompagnant cette flexibilité est l'exigence pour la configuration et le réglage adéquat. Il est temps pour quelques directives générales pour la configuration des clusters Hbase. Votre…
HBase et de la technologie de base de données relationnelle (comme Oracle, DB2, MySQL et pour ne citer que quelques-uns) ne se comparent pas vraiment tout ce que bien. Malgré le cliché # 233-, il est vraiment un cas de comparer des pommes avec…
Toute installation HBase grave nécessite une configuration standard sur votre cluster et sur les nœuds individuels. Quelques exemples sont fournis ici. Prenez d'abord un regard sur la surveillance et la gestion.Outils de surveiller votre clusterSi…
Sqoop peut être utilisé pour transformer un schéma de base de données relationnelle dans un schéma HBase. Bien sûr, l'objectif principal ici est de démontrer comment Sqoop peut importer des données à partir d'un SGBDR ou entrepôt de…
Le modèle de données logique HBase est simple mais élégant, et il fournit un mécanisme de stockage de données pour organiser toutes sortes de données - de grands ensembles de données non structurées en particulier. Toutes les parties du…
RegionServers sont une chose, mais il faut aussi jeter un oeil à la façon dont les différentes régions travaillent. Dans HBase, une table est à la fois la propagation à travers un certain nombre de RegionServers ainsi comme étant composé des…
RegionServers sont les processus logiciels (souvent appelés démons) vous activez pour stocker et récupérer des données dans HBase (Base de données Hadoop). Dans les environnements de production, chaque RegionServer est déployé sur son propre…
Hbase magasins de données sont constitués d'une ou plusieurs tables qui sont indexées par les touches de ligne. Les données sont stockées dans des lignes avec des colonnes et rangées peut avoir plusieurs versions. Par défaut, le versioning…
Dans un univers Hadoop, nœuds esclaves sont où les données Hadoop est stockée et où le traitement de données a lieu. Les services suivants permettent nœuds esclaves pour stocker et traiter les données:NodeManager: Coordonne les ressources…
HBase est, une base de données qui utilise HDFS que son magasin de persistance pour les grands projets de données non relationnelles distribuée (de colonne). Elle est calquée sur Google BigTable et est capable d'accueillir de très grandes…
HBase est écrit en Java, un langage élégant pour la construction de technologies distribuées comme HBase, mais le visage il - pas tout le monde qui veut prendre avantage des innovations Hbase est un développeur Java. Voilà pourquoi il ya un…
Démarrage d'une discussion des HBase (Base de données Hadoop) en décrivant l'architecture RegionServers la place de la MasterServer peut vous surprendre. Le terme RegionServer semble impliquer que cela dépend (et est secondaire à)…
Zookeeper est un cluster de serveurs distribués qui fournit collectivement des services de coordination et de synchronisation fiables pour des applications en cluster. Certes, le nom “ Zookeeper ” peut sembler à première vue être un…
Les bases de données en colonnes peuvent être très utiles dans votre grand projet de données. Bases de données relationnelles sont orientée rangée, que les données de chaque ligne d'une table sont stockées ensemble. Dans une forme de…