L'architecture de la ruche apache
Comme vous examinez les éléments de Apache Hive montrées, vous pouvez voir au bas cette ruche se trouve au sommet du système Hadoop Distributed File (HDFS) et les systèmes de MapReduce.
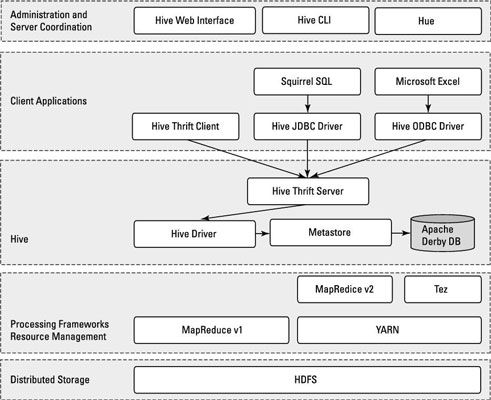
Dans le cas de MapReduce, les figureshows deux composants Hadoop Hadoop 1 et 2. Avec Hadoop 1, les requêtes de la ruche sont converties en code MapReduce et exécutés en utilisant l'infrastructure MapReduce v1 (MRv1), comme le JobTracker et TaskTracker.
Avec Hadoop 2, FILS a découplé la gestion des ressources et la planification du cadre de MapReduce. Requêtes Hive peuvent encore être convertis au code MapReduce et exécutés, maintenant avec MapReduce v2 (MRv2) et l'infrastructure de fil.
Il ya un nouveau cadre en cours de développement appelé Apache Tez, qui est conçu pour améliorer les performances pour les requêtes Hive lot de style et de soutenir les petites interactive (aussi connu comme temps réel) Requêtes. Au moment de la rédaction, le projet Apache Tez est encore en incubation, et ne dispose pas encore d'une version prête pour la production.
Si elle vous aide à visualiser la façon dont tous les morceaux vont ensemble, penser aux systèmes de HDFS et MapReduce comme étant des parties du système d'exploitation Apache Hadoop, avec Hive - ainsi que d'autres composants, tels que HBase - comme des fonctions ou des applications de plus haut niveau. (Vous pouvez voir émerger un thème commun: HDFS fournit le stockage, et MapReduce fournit la capacité de traitement parallèle pour des fonctions de niveau supérieur au sein de l'écosystème Hadoop.)
Gravir le schéma, vous trouverez le pilote Hive, qui compile, optimise, et exécute le HiveQL. Le pilote ruche peut choisir d'exécuter des instructions et commandes HiveQL localement ou frayer un travail de MapReduce, en fonction de la tâche à accomplir. The Hive magasins du pilote des métadonnées de table dans le Metastore et sa base de données.
Vous avez probablement une certaine familiarité avec SQL et le modèle de base de données relationnelle du monde de SGBDR. UN table ou rapport est composée de colonnes verticales et de rangées horizontales. Cellules où sont stockés les lignes et les colonnes croisent. Si vous n'êtes pas familier avec SQL et le modèle de base de données relationnelle, vous pouvez trouver des sources d'apprentissage utiles en utilisant votre moteur de recherche préféré.
Par défaut, la ruche comprend l'Apache Derby SGBDR configuré avec le Metastore dans ce qu'on appelle le mode intégré. Mode intégré signifie que le pilote Hive, l'Metastore et Apache Derby sont tous en cours d'exécution dans une machine virtuelle Java (JVM).
Cette configuration est très bien à des fins d'apprentissage, mais le mode intégré peut soutenir une seule séance Hive, de sorte qu'il est normalement pas utilisé dans les environnements de production multi-utilisateurs. Deux autres modes existent - local et éloigné - qui peuvent mieux soutenir plusieurs sessions Hive dans des environnements de production. En outre, vous pouvez configurer tous les SGBDR qui est conforme à la Java Database Connectivity (JDBC) Application Programming Interface (API) Suite. (Exemples ici incluent MySQL et DB2.)
La clé de support d'application est le Hive Thrift Server, qui permet à un riche ensemble de clients pour accéder au sous-système de la ruche. L'open source client SQuirreL SQL est inclus à titre d'exemple. Le point principal est que toute application compatible JDBC peut accéder à la ruche via le pilote JDBC fourni.
La même constatation vaut pour les clients compatibles avec Open Database Connectivity (ODBC) - par exemple, unixODBC et l'utilitaire isql, qui sont généralement livré avec Linux, permettent d'accéder à la ruche des clients Linux distants.
En outre, si vous utilisez Microsoft Excel, vous serez heureux de savoir que vous pouvez accéder à la ruche après avoir installé le pilote ODBC Microsoft sur votre système client. Enfin, si vous avez besoin d'accéder à la ruche dans les langages de programmation autres que Java (PHP ou Python, par exemple), Apache Thrift est la réponse. Apache Thrift clients se connectent via le Hive Hive Thrift Server, tout comme les clients JDBC et ODBC font.
Pour continuer avec l'architecture dessin Hive, noter que la ruche comprend un Command Line Interface (CLI), où vous pouvez utiliser une fenêtre de terminal Linux pour émettre des requêtes et des commandes d'administration directement au chauffeur Hive. Si une approche graphique est plus votre vitesse, il ya aussi une interface web à portée de main afin que vous puissiez accéder à vos tables et les données Hive gérées via votre navigateur préféré.
Il est une autre technologie de navigateur web connu sous Hue qui fournit une interface utilisateur graphique (GUI) pour Apache Hive. Certains utilisateurs Hadoop tiens à avoir une interface graphique à leur disposition au lieu d'une interface de ligne de commande (CLI). Avec Hive, Hue soutient d'autres technologies clés Hadoop ainsi comme HDFS, MapReduce / FILS, HBase, Zookeeper, oozie, Pig, et Sqoop. Vous aimerez le nom pour Apache Hive l'interface graphique de Hue - elle est appelée cire d'abeille.


Sqoop (SQL-à-Hadoop) est un outil grand de données qui offre la possibilité d'extraire des données à partir des données magasins non Hadoop, transformer les données en une forme utilisable par Hadoop, puis charger les données dans HDFS. Ce…
Il n'y a pas de meilleure façon de voir ce qui est ce que l'installation du logiciel ruche et lui donner un essai. Comme avec d'autres technologies dans l'écosystème Hadoop, il ne faut pas longtemps pour commencer.Si vous avez le temps et la…
Ici, vous importez la totalité de la base de données directement à partir de l'ordre de service MySQL dans la ruche et exécutez une requête HiveQL contre la base de données nouvellement importée sur Hadoop. La liste suivante vous montre…
Vous savez probablement déjà que les experts en modélisation de base de données relationnelle et la conception passent généralement beaucoup de leur temps à la conception des bases de données normalisées, ou schémas. Base de données…
La communauté Apache Hive vivante et active en permanence ajouters déjà à un vaste ensemble de fonctionnalités, ce qui rend la couverture exhaustive encore plus difficile. La liste qui suit résume quelques caractéristiques principales HiveQL…
Pour permettre une meilleure compréhension des alternatives SQL-sur-Hadoop Hive, il pourrait être utile d'examiner une amorce sur le traitement massivement parallèle (MPP) des bases de données en premier.Apache Hive est posée sur le dessus du…
En 2010, EMC et VMware, les leaders du marché dans la prestation de l'informatique comme un service via le cloud computing, acquis Greenplum Corporation, les gens qui avaient obtenu gain de cause le produit MPP Greenplum Data Warehouse (DW) sur le…
Le flux de processus de fils ressemble beaucoup comme un cadre de l'exécution du lot. Vous pourriez vous demander, “? Qu'est-il arrivé à cette idée de flexibilité pour les différents modes d'applications ” Eh bien, le seul cadre de…
Apache Hive est incontestablement interface d'interrogation de données la plus répandue dans la communauté Hadoop. À l'origine, les objectifs de conception pour la ruche étaient pas pour assurer la compatibilité de SQL complète et de haute…
SQuirreL SQL est un outil open source qui agit comme un client Hive. Vous pouvez télécharger ce client SQL universelle à partir du site SourceForge. Il fournit une interface utilisateur de ruche et simplifie les tâches de l'interrogation de…
Lorsque l'on considère les capacités de Hadoop pour travailler avec des données structurées (ou de travailler avec des données de tout type, d'ailleurs), rappelez-vous les caractéristiques de base de Hadoop: Hadoop est, d'abord et avant tout,…
Hadoop est plus que MapReduce et HDFS (Distributed File System Hadoop): Il est également une famille de projets connexes (un écosystème, vraiment) pour le calcul distribué et le traitement de données à grande échelle. La plupart (mais pas…
HBase est écrit en Java, un langage élégant pour la construction de technologies distribuées comme HBase, mais le visage il - pas tout le monde qui veut prendre avantage des innovations Hbase est un développeur Java. Voilà pourquoi il ya un…
Hive est, une couche d'entreposage des données orientée lots construit sur les éléments de base de Hadoop (HDFS et MapReduce) et est très utile dans les grandes données. Il fournit aux utilisateurs qui connaissent SQL avec une mise en œuvre…