La zone d'atterrissage sur la base Hadoop-
Lorsque vous essayez de déchiffrer ce que l'environnement de l'analyse pourrait ressembler à l'avenir, vous tomberez sur le modèle du temps et le temps basé sur Hadoop zone d'atterrissage à nouveau. En fait, il est même plus une discussion à terme axée parce que la zone d'atterrissage est devenu la façon dont les entreprises prospectifs essaient maintenant de sauver des coûts informatiques, et de fournir une plate-forme pour l'analyse de données innovante.
Alors quelle est exactement la zone d'atterrissage? Au niveau le plus élémentaire, le zone d'atterrissage est simplement la place centrale où les données vont atterrir dans votre entreprise - extractions hebdomadaires de données provenant de bases de données opérationnelles, par exemple, ou à partir de fichiers journaux systèmes de production. Hadoop est un référentiel utile pour l'atterrissage des données, pour ces raisons:
Il peut gérer toutes sortes de données.
Il est facilement extensible.
Il est peu coûteux.
Une fois que vous atterrissez données dans Hadoop, vous avez la possibilité d'interroger, d'analyser ou de traiter les données dans une variété de façons.
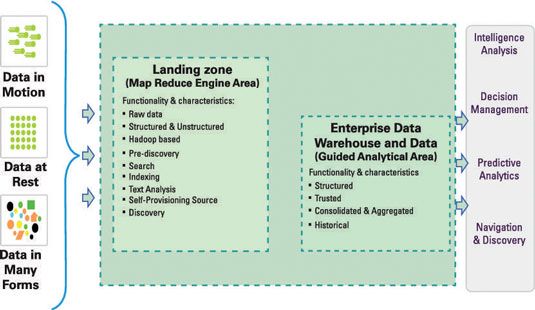
Ce schéma ne montre qu'une partie de l'histoire et est nullement complète. Après tout, vous devez savoir comment les données se déplace de la zone d'atterrissage à l'entrepôt de données, et ainsi de suite.
Le point de départ de la discussion sur la modernisation d'un entrepôt de données doit être la façon dont les organisations utilisent les entrepôts de données et les défis les départements informatiques doivent faire face avec eux.
Dans les années 1980, une fois que les organisations est devenu bon à stocker leurs informations opérationnelles dans les bases de données relationnelles (transactions de vente, par exemple, ou les statuts de la chaîne d'approvisionnement), les chefs d'entreprise ont commencé à vouloir rapports générés à partir de ces données relationnelles. Les premiers magasins relationnelles étaient les bases de données opérationnelles et ont été conçus pour Online Transaction Processing (OLTP), de sorte que les dossiers pourraient être insérées, mises à jour ou effacées aussi rapidement que possible.
Ceci est une architecture peu pratique pour un grand reporting et d'analyse échelle, de sorte Relational Online Analytical Processing (ROLAP) des bases de données ont été développés pour répondre à ce besoin. Cela a conduit à l'évolution d'un tout nouveau genre de SGBDR: un entrepôt de données, qui est une entité distincte et vit aux côtés des magasins de données opérationnelles de l'organisation.
Ce qui revient à l'aide d'outils spécialement conçus pour une plus grande efficacité: vous avez les magasins de données opérationnelles, qui sont conçus pour traiter efficacement les transactions, et des entrepôts de données, qui sont conçus pour soutenir l'analyse et les rapports répétés.
Les entrepôts de données sont sous stress croissant si, pour les raisons suivantes:
La demande accrue pour garder périodes de données plus en ligne.
La demande accrue de ressources de traitement pour transformer les données pour une utilisation dans d'autres entrepôts et magasins de données.
La demande accrue pour l'analyse innovants, qui exige que les analystes poser des questions sur les données de l'entrepôt, sur le dessus de la soumission régulière qui se fait déjà. Cela peut engager un traitement supplémentaire significative.
Dans la figure, vous pouvez voir l'entrepôt de données présenté comme la principale ressource pour les divers types d'analyse figurant sur le côté droit de la figure. Ici, vous voyez aussi le concept d'une zone d'atterrissage représenté, où Hadoop va stocker les données à partir d'une variété de sources de données entrants.
Pour activer une zone d'atterrissage Hadoop, vous aurez besoin pour vous assurer que vous pouvez écrire des données à partir des diverses sources de données à HDFS. Pour bases de données relationnelles, une bonne solution serait d'utiliser Sqoop.
Mais l'atterrissage des données est que le début.
Lorsque vous vous déplacez les données provenant de nombreuses sources dans votre zone d'atterrissage, une question que vous aurez inévitablement des est la qualité des données. Il est courant pour les entreprises d'avoir de nombreuses bases de données opérationnelles clés où les détails sont différents, par exemple, que le client pourrait être connu comme “ D. DeRoos ” dans une base de données, et “ Dirk DeRoos ” en autre.
Un autre problème de qualité réside dans les systèmes où il ya une forte dépendance sur l'entrée manuelle de données, soit des clients ou du personnel - ici, il est pas rare de trouver des prénoms et noms de famille mis autour de la désinformation ou d'une autre dans les champs de données.
Les problèmes de qualité de données sont un gros problème pour les environnements d'entrepôts de données, et voilà pourquoi beaucoup d'effort va dans nettoyage et de validation des mesures que les données provenant d'autres systèmes sont traités comme il est chargé dans l'entrepôt. Le tout se résume à confiance: Si les données vous posez des questions contre est sale, vous ne pouvez pas confiance dans les réponses dans vos rapports.
Ainsi, alors qu'il ya un énorme potentiel à avoir accès à de nombreux ensembles de données différents provenant de différentes sources dans votre zone d'atterrissage Hadoop, vous devez prendre en compte la qualité des données et combien vous pouvez faire confiance aux données.
-
 Intégrer les grandes données avec l'entrepôt de données traditionnelle
Intégrer les grandes données avec l'entrepôt de données traditionnelle -
 La modernisation de l'entrepôt de données avec Hadoop
La modernisation de l'entrepôt de données avec Hadoop -
 Les facteurs qui augmentent l'échelle d'analyse statistique dans Hadoop
Les facteurs qui augmentent l'échelle d'analyse statistique dans Hadoop -
 Hadoop comme un moteur de prétraitement des données
Hadoop comme un moteur de prétraitement des données - Hadoop comme une archive interrogeable des données de l'entrepôt froid
-
 Hadoop comme une destination de données d'archives
Hadoop comme une destination de données d'archives
Sqoop (SQL-à-Hadoop) est un outil grand de données qui offre la possibilité d'extraire des données à partir des données magasins non Hadoop, transformer les données en une forme utilisable par Hadoop, puis charger les données dans HDFS. Ce…
Pour permettre une meilleure compréhension des alternatives SQL-sur-Hadoop Hive, il pourrait être utile d'examiner une amorce sur le traitement massivement parallèle (MPP) des bases de données en premier.Apache Hive est posée sur le dessus du…
Il ya des raisons impérieuses que SQL a su résister. L'industrie des TI a eu 40 ans d'expérience avec SQL, car il a d'abord été développé par IBM au début des années 1970. Avec l'augmentation de l'adoption de bases de données…
Vous trouverez la valeur en apportant les capacités de l'entrepôt de données et de l'environnement de données grand ensemble. Vous devez créer un environnement hybride où les grandes données peuvent travailler main dans la main avec…
Un entrepôt de données a une distribution de données à grande échelle et de technologies de pointe qui peuvent intégrer diverses “ diriger l'entreprise ” systèmes, l'amélioration de la qualité globale des actifs de données à…
De nombreux experts de l'entreposage de données feraient valoir qu'une véritable data mart est un “ point de vente, n ° 148; et d'un entrepôt de données fournit son contenu, comme le montre cette figure.Dans un environnement comme celui…
Un entrepôt de données est, par sa nature même, un magasin physique de données distribuée. Répartition de vos actifs informationnels aide à la performance et la convivialité entre les systèmes et dans toute l'entreprise. Faire ce niveau de…
UN entrepôt de données est une maison pour vos données de grande valeur, ou actifs de données, qui provient d'autres applications de l'entreprise, tels que celui de votre entreprise utilise pour remplir les commandes des clients pour ses…
Une idée fausse commune que les amateurs de l'entrepôt de données de nombreux détiennent est que la seule bonne entrepôt de données est un grand entrepôt de données -un énormément grand entrepôt de données. Beaucoup de gens prennent…
Avec l'avènement de grands volumes de données, les modèles de déploiement pour la gestion des données sont en train de changer. L'entrepôt de données traditionnelle est généralement mis en œuvre sur un seul grand système au sein du centre…
Le marché de l'entrepôt de données a en effet commencé à changer et à évoluer avec l'avènement de grands volumes de données. Dans le passé, il était tout simplement pas rentable pour les entreprises de stocker la quantité massive de…
Beaucoup d'entreprises explorent de gros problèmes de données et à venir avec des solutions innovantes. Il est maintenant temps de prêter attention à un certain les meilleures pratiques, ou principes de base, qui vous servira ainsi que vous…
Le produit Microsoft SQL Server se compose de quatre éléments principaux, trois d'entre eux acronymes sportives. Utilisez cette liste pour identifier les composants de SQL Server et de leur dire à part.Database Engine: Cette partie de SQL Server…
Entreprises stocker numériquement une quantité énorme de données opérationnelles, et pour la business intelligence à la fonction, il a besoin de larges routes ouvertes entre les sources de données. Les anciens systèmes Mainframe forment…