Zookeeper et HBase fiabilité
Zookeeper est un cluster de serveurs distribués qui fournit collectivement des services de coordination et de synchronisation fiables pour des applications en cluster. Certes, le nom “ Zookeeper ” peut sembler à première vue être un choix étrange, mais quand vous comprenez ce qu'il fait pour un cluster HBase, vous pouvez voir la logique derrière tout cela. Lorsque vous construisez et le débogage des applications distribuées “ il est un zoo là-bas, ” de sorte que vous devriez mettre Zookeeper sur votre équipe.
Hbase grappes peut être énorme et de coordonner les opérations des MasterServers, RegionServers, et les clients peuvent être une tâche ardue, mais qui est là Zookeeper entre dans l'image. Comme dans HBase, grappes Zookeeper fonctionnent généralement sur des serveurs x86 produits à faible coût.
Chaque serveur individuel x86 exécute un processus de logiciel de Zookeeper unique (ci-après dénommé un serveur Zookeeper), avec un serveur Zookeeper élu par l'ensemble comme le leader et le reste des serveurs sont des adeptes. Zookeeper ensembles sont régies par le principe d'un quorum de la majorité.
Configurations avec un serveur Zookeeper sont pris en charge à des fins de test et de développement, mais si vous voulez un cluster fiable qui peut tolérer l'échec du serveur, vous devez déployer au moins trois serveurs Zookeeper pour atteindre le quorum de la majorité.
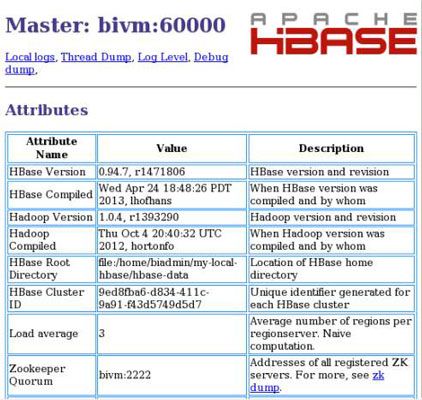
Alors, combien de serveurs Zookeeper aurez-vous besoin? Cinq est le minimum recommandé pour une utilisation en production, mais vous ne voulez vraiment pas aller avec le strict minimum. Lorsque vous décidez de planifier votre ensemble de Zookeeper, suivez cette formule simple: 2F + 1 = N où F est le nombre d'échecs vous pouvez accepter dans votre cluster Zookeeper et N est le nombre total de serveurs Zookeeper vous devez déployer.
Cinq est recommandée car un serveur peut être arrêté pour maintenance, mais le cluster Zookeeper peut encore tolérer la panne d'un serveur.
Zookeeper assure la coordination et la synchronisation avec ce qu'il appelle znodes, qui sont présentés comme une arborescence de répertoires et ressemblent aux noms de chemin de fichier que vous verriez dans un système de fichiers Unix. Znodes faire stocker des données mais pas beaucoup de parler de - actuellement moins de 1 Mo par défaut.
L'idée ici est que Zookeeper magasins znodes en mémoire et que ces znodes à base de mémoire offrent un accès à la clientèle rapide de la coordination, de l'état, et d'autres fonctions vitales requises par les applications distribuées comme HBase. Zookeeper réplique znodes travers l'ensemble si les serveurs ne parviennent pas, les données de znode est toujours disponible tant que le quorum de la majorité des serveurs est toujours en place et en cours d'exécution.
Un autre concept de préoccupations primaires Zookeeper comment znode lit (contre écritures) sont traitées. Tout serveur peut gérer Zookeeper lit d'un client, y compris le leader, mais seulement les questions de chef atomique znode écrit - écrit que soit complètement réussi ou complètement sûr.
Lorsqu'une demande znode d'écriture arrive au nœud leader, le leader diffuse la demande d'écriture pour les nœuds de suiveurs et attend pour une majorité de partisans de reconnaître znode radiation complète. Après la reconnaissance, le chef délivre le znode écriture elle-même et rend compte ensuite de l'état de la réussite pour le client.
Znodes fournissent des garanties très puissants. Lorsqu'un client Zookeeper (tel qu'un RegionServer HBase) écrit ou lit une znode, l'opération est atomique. Il réussit complètement ou complètement échoue - il ya lit pas partielle ou écrit.
Aucun autre client concurrent peut causer l'opération de lecture ou d'écriture à l'échec. En outre, un znode a une listes de contrôle d'accès (ACL) qui lui sont associés pour la sécurité, et il supporte les versions, l'heure et la notification aux clients quand elle change.
Zookeeper réplique znodes travers l'ensemble si les serveurs ne parviennent pas, les données de znode est toujours disponible tant que le quorum de la majorité des serveurs est toujours en place et en cours d'exécution. Cela signifie que toute znode écrit à partir de tout serveur Zookeeper doit être propagée à travers l'ensemble. Le chef Zookeeper gère cette opération.
Cette approche d'écriture de znode peut causer des adeptes de tomber derrière le leader pour de courtes périodes. Zookeeper résout ce problème potentiel en fournissant une commande de synchronisation. Les clients qui ne peuvent pas tolérer ce manque temporaire de la synchronisation au sein du cluster Zookeeper peuvent décider d'émettre une commande de synchronisation avant de lire znodes.




 haute disponibilité")
Plus grande technique de Hadoop pour traiter de grands défis de données est sa capacité à diviser et conquérir avec Zookeeper. Après le problème a été divisé, la conquête repose sur la capacité de répartie et emploient des techniques de…
HBase est une technologie puissante et flexible, mais accompagnant cette flexibilité est l'exigence pour la configuration et le réglage adéquat. Il est temps pour quelques directives générales pour la configuration des clusters Hbase. Votre…
Toute installation HBase grave nécessite une configuration standard sur votre cluster et sur les nœuds individuels. Quelques exemples sont fournis ici. Prenez d'abord un regard sur la surveillance et la gestion.Outils de surveiller votre clusterSi…
La communauté Apache Hive vivante et active en permanence ajouters déjà à un vaste ensemble de fonctionnalités, ce qui rend la couverture exhaustive encore plus difficile. La liste qui suit résume quelques caractéristiques principales HiveQL…
Capacités de lecture rapide de clé-valeur magasins découlent de leur utilisation de clés bien définis. Ces touches sont généralement hachés, qui donne un magasin clé-valeur d'une manière très prévisible de déterminer quelle partition…
Les nœuds maîtres dans les clusters Hadoop distribués abritent les différents services de stockage et de gestion de traitement, décrits dans cette liste, pour l'ensemble du cluster Hadoop. La redondance est essentiel pour éviter les points de…
RegionServers sont les processus logiciels (souvent appelés démons) vous activez pour stocker et récupérer des données dans HBase (Base de données Hadoop). Dans les environnements de production, chaque RegionServer est déployé sur son propre…
Dans un univers Hadoop, nœuds esclaves sont où les données Hadoop est stockée et où le traitement de données a lieu. Les services suivants permettent nœuds esclaves pour stocker et traiter les données:NodeManager: Coordonne les ressources…
Ici, vous trouverez comment télécharger et déployer HBase en mode autonome. Il est incroyablement simple à installer HBase et commencer à utiliser la technologie. Il suffit de garder à l'esprit que HBase est généralement déployée sur un…
Hadoop est plus que MapReduce et HDFS (Distributed File System Hadoop): Il est également une famille de projets connexes (un écosystème, vraiment) pour le calcul distribué et le traitement de données à grande échelle. La plupart (mais pas…
Démarrage d'une discussion des HBase (Base de données Hadoop) en décrivant l'architecture RegionServers la place de la MasterServer peut vous surprendre. Le terme RegionServer semble impliquer que cela dépend (et est secondaire à)…
Les bases de données en colonnes peuvent être très utiles dans votre grand projet de données. Bases de données relationnelles sont orientée rangée, que les données de chaque ligne d'une table sont stockées ensemble. Dans une forme de…
Lion Server peut jouer des rôles différents dans Open Directory: un maître, une réplique, ou un relais. Un autre rôle un serveur Mac peut avoir est de simplement connecter ou bind, à un répertoire. Lors de la planification de votre réseau,…
Selon la taille de votre déploiement SharePoint 2100, vous pouvez avoir un ou plusieurs serveurs SharePoint affectés à servir à des fins spécifiques ou des rôles, y compris ceux-ci:Serveur Web: Ce serveur (aussi connu comme un serveur Web…