Les données structurées dans un environnement grand de données
Le terme données structurées
Sommaire
Sources de grande données structurées
Bien que cela puisse sembler affaires comme d'habitude, dans la réalité, les données structurées prend un nouveau rôle dans le monde des grands volumes de données. L'évolution de la technologie offre des nouvelles sources de données structurées produites - souvent en temps réel et dans des volumes importants. Les sources de données sont divisés en deux catégories:
Par ordinateur ou produite par une machine: Paramètres machine généré se réfère généralement à des données qui sont créées par une machine sans intervention humaine.
Human généré: Ce sont des données que les humains, en interaction avec les ordinateurs, l'approvisionnement.
Certains experts font valoir qu'une troisième catégorie existe qui est un hybride entre la machine et l'homme. Mais ici, nous sommes préoccupés par les deux premières catégories.
Données structurées générées par une machine peuvent inclure les éléments suivants:
Les données du capteur: Les exemples incluent la radio balises fréquence d'identité, les compteurs intelligents, les dispositifs médicaux et les données du système de positionnement global. Les entreprises sont intéressés à cette gestion de la chaîne d'approvisionnement et de contrôle de l'inventaire.
données de journal web: Lorsque les serveurs, applications, réseaux, etc. fonctionnent, ils capturent toutes sortes de données sur leur activité. Cela peut représenter d'énormes volumes de données qui peuvent être utiles, par exemple, pour faire face à des accords de niveau de service ou de prédire les brèches de sécurité.
Point de vente des données: Lorsque le caissier glisse le code à barres d'un produit que vous achetez, toutes les données associées au produit est généré.
Données financières: Beaucoup de systèmes financiers sont programmatic- maintenant ils sont exploités sur la base de règles prédéfinies qui automatisent les processus. Stock de données de transaction est un bon exemple de cela. Il contient des données structurées telles que le symbole de l'entreprise et la valeur du dollar. Certaines de ces données est générée par machine, et une partie est générée humaine.
Exemples de données produits par les humains structurés pourraient être les suivantes:
Des données d'entrée: Ceci est tout morceau de données une entrée de puissance humaine dans un ordinateur, telles que le nom, l'âge, le revenu, les réponses de l'enquête non-forme libre, et ainsi de suite. Ces données peuvent être utiles pour comprendre le comportement de base de client.
Cliquez flux de données: Les données sont générées chaque fois que vous cliquez sur un lien sur un site web. Ces données peuvent être analysées afin de déterminer le comportement des clients et les habitudes d'achat.
Les données relatives au jeu: Chaque mouvement que vous faites dans un jeu peut être enregistré. Cela peut être utile pour comprendre comment les utilisateurs finaux se déplacent à travers un portefeuille de jeux.
Lorsque combiné avec des millions d'autres utilisateurs qui soumettent les mêmes informations, la taille est astronomique. En outre, beaucoup de ces données a une composante en temps réel à ce que peut être utile pour comprendre les tendances qui ont le potentiel de prédire les résultats.
La ligne de fond est que ce genre d'information peut être puissant et peut être utilisé à de nombreuses fins.
Le rôle des bases de données relationnelles dans Big Data
La persistance des données se réfère à la façon dont une base de données conserve les versions de lui-même lorsqu'il est modifié. Le grand-père de magasins de données persistantes est la système de gestion de base de données relationnelle. À ses débuts, l'industrie informatique a utilisé ce sont maintenant considérées comme des techniques primitives pour la persistance des données.
Le modèle relationnel a été inventé par Edgar Codd, un scientifique d'IBM, dans les années 1970 et a été utilisé par IBM, Oracle, Microsoft, et d'autres. Il est encore dans l'utilisation large aujourd'hui et joue un rôle important dans l'évolution de grands volumes de données. Comprendre la base de données relationnelle est important parce que d'autres types de bases de données sont utilisés avec de grandes données.
Dans un modèle relationnel, les données sont stockées dans une table. Cette base de données contiendra une schéma - qui est une représentation structurelle de ce qui est dans la base de données. Par exemple, dans une base de données relationnelle, le schéma définit les tables, les champs dans les tables, et les relations entre les deux.
Les données sont stockées dans les colonnes, une pour chaque attribut de chaque donnée. Les données sont également stockées dans la rangée. Le premier produit de table stocke les infos deuxième stocke des informations démographiques. Chacun a différents attributs. Chaque table peut être mis à jour avec de nouvelles données, et les données peuvent être supprimées, de lire, et mis à jour. Ceci est souvent accompli en utilisant un modèle relationnel un langage d'interrogation structuré (SQL).
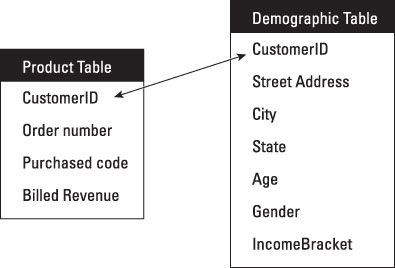
Un autre aspect du modèle relationnel utilisant SQL est que les tables peuvent être interrogés en utilisant une clé commune. La clé commune dans les tableaux est CustomerID.
Vous pouvez soumettre une requête, par exemple, pour déterminer le sexe des clients qui ont acheté un produit spécifique. Il pourrait ressembler à ceci:
Sélectionnez CustomerID, État, Sexe, produit à partir de "tableau démographique", "table de produit", où le produit = XXYY



Un entrepôt de données est, par sa nature même, un magasin physique de données distribuée. Répartition de vos actifs informationnels aide à la performance et la convivialité entre les systèmes et dans toute l'entreprise. Faire ce niveau de…
UN entrepôt de données est une maison pour vos données de grande valeur, ou actifs de données, qui provient d'autres applications de l'entreprise, tels que celui de votre entreprise utilise pour remplir les commandes des clients pour ses…
L'organisation des services de données et des outils, couche 3 de la grosse pile de données, la capture, valider et assembler différents éléments de données dans de grandes collections contextuellement pertinents. Parce que Big Data est…
Bases de données non relationnelles ne reposent pas sur la table / modèle clé endémique de SGBDR (systèmes de gestion de base de données relationnelle). En bref, les données de spécialité dans le grand monde de données exige de la…
Il ya plusieurs fournisseurs qui offrent en stockage de données produits middleware vous voudrez peut-être jeter un oeil à. Voici sept qui sont à considérer.Composite SoftwareComposite Software fournit Enterprise Information Integration (IIE)…
Comme l'informatique a emménagé dans le marché commercial, les données ont été stockées dans des fichiers plats qui ont imposé aucune structure. Aujourd'hui, Big Data nécessite des structures de données à gérer. Lorsque les entreprises…
Le marché de l'entrepôt de données a en effet commencé à changer et à évoluer avec l'avènement de grands volumes de données. Dans le passé, il était tout simplement pas rentable pour les entreprises de stocker la quantité massive de…
Beaucoup d'entreprises explorent de gros problèmes de données et à venir avec des solutions innovantes. Il est maintenant temps de prêter attention à un certain les meilleures pratiques, ou principes de base, qui vous servira ainsi que vous…
Big données nécessite une approche cohérente de la gestion de contenu Web et. Il est pas un secret que la plupart des données disponibles dans le monde d'aujourd'hui est non structurées. Paradoxalement, les entreprises ont concentré leurs…
Big données permet aux entreprises de stocker, gérer et manipuler de grandes quantités de données disparates à la bonne vitesse et au bon moment. Pour gagner les bonnes idées, Big Data est généralement décomposé par trois…
Comment allez-vous savoir comment mettre toutes vos données ensemble? Avec un grand projet de données, ce que vous voulez faire avec vos données structurées et non structurées indique pourquoi vous pouvez choisir une seule pièce de la…
MySQL est un système de gestion de bases de données relationnelles (SGBDR). Votre serveur MySQL peut gérer plusieurs bases de données en même temps. En fait, beaucoup de gens pourraient avoir différentes bases de données gérées par un seul…
Le produit Microsoft SQL Server se compose de quatre éléments principaux, trois d'entre eux acronymes sportives. Utilisez cette liste pour identifier les composants de SQL Server et de leur dire à part.Database Engine: Cette partie de SQL Server…
Pour faire une demande que MySQL ne peut comprendre, vous construisez une instruction SQL et de l'envoyer au serveur MySQL. Les mots en gras dans le tableau sont les noms de requête MySQL:DéclarationDescriptionALTER TABLE tablechangeApporte des…