Analyse exploratoire des données graphiques (eda) techniques
EDA est basée largement sur les techniques graphiques. Vous pouvez utiliser des techniques graphiques pour identifier les propriétés les plus importantes d'un ensemble de données. Voici quelques-unes des techniques graphiques plus largement utilisés:
Les boîtes à moustaches
Histogrammes
Tracés de normalité
Les diagrammes de dispersion
Les boîtes à moustaches
Vous utilisez les diagrammes en boîte de montrer certaines des caractéristiques les plus importantes d'un ensemble de données, telles que les suivantes:
Valeur minimale
Valeur maximale
Quartiles
Quartiles séparent un ensemble de données en quatre sections égales. Le premier quartile (Q1) Est une valeur telle que ce qui suit est vrai:
25 pour cent des observations dans un jeu de données est inférieure à la première quartile.
75 pour cent des observations sont plus grand que le premier quartile.
Le deuxième quartile (Q2) Est une valeur telle que
50 pour cent des observations dans un jeu de données est inférieure à la deuxième quartile.
50 pour cent des observations sont plus importants que le deuxième quartile.
La deuxième quartile est également connu sous le nom médiane.
Le troisième quartile (Q3) Est une valeur telle que
75 pour cent des observations dans un ensemble de données sont moins que le troisième quartile.
25 pour cent des observations sont plus grands que le troisième quartile.
Vous pouvez également utiliser des boîtes à moustaches pour identifier aberrantes. Ce sont des valeurs qui sont sensiblement différent du reste de l'ensemble de données. Les valeurs aberrantes peuvent causer des problèmes pour les tests statistiques traditionnels, il est donc important de les identifier avant d'effectuer tout type d'analyse statistique.
Histogrammes
Vous utilisez histogrammes de mieux comprendre la distribution de probabilité qu'un ensemble de données suit. Avec un histogramme, l'ensemble de données est organisé en une série de valeurs ou plages de valeurs individuelles, chacun étant représenté par une barre verticale. La hauteur de la barre indique la fréquence à une valeur ou un intervalle de valeurs se produit. Avec un histogramme, il est facile de voir comment les données sont distribuées.
Les diagrammes de dispersion
Un diagramme de dispersion est une série de points qui montrent comment deux variables sont liées les unes aux autres. Une dispersion aléatoire de points indique que les deux variables ne sont pas liés, ou que la relation entre eux est très faible. Si les points ressemblent étroitement à une ligne droite, ce qui indique que la relation entre les deux variables est d'environ linéaire.
Deux variables sont linéairement liées si elles peuvent être décrits avec l'équation Y = mX + b.
X est la variable indépendante, et Y est la variable dépendante. m est le pente, qui représente l'évolution de Y en raison d'un changement donné dans X. b est le interception, qui montre la valeur de Y quand X est égale à zéro.
La figure montre un nuage de points entre deux variables dans lequel la relation semble être linéaire.
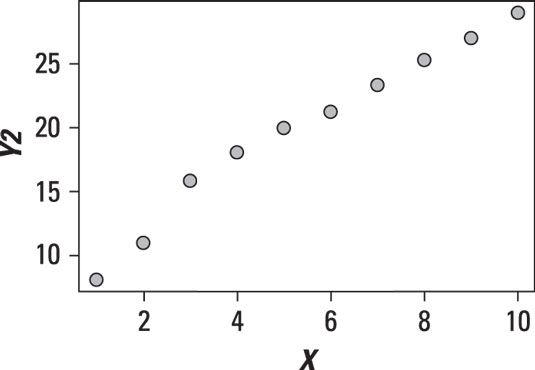
Les points sur le diagramme de dispersion forment presque une ligne droite. Il se penche un peu vers la gauche et se penche un peu sur la droite, mais il est à peu près droit. Cela montre que la relation est linéaire, avec une pente positive.
La figure suivante montre un nuage de points entre deux variables dans laquelle Y semble être en hausse plus rapide que X.
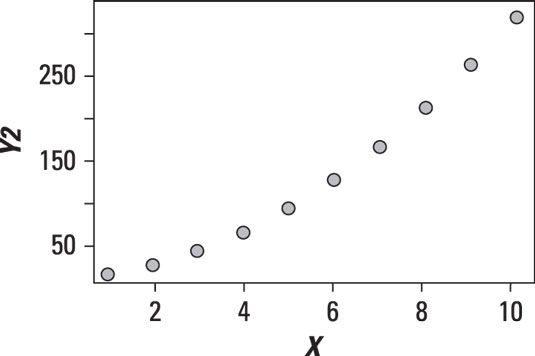
Voir la courbe? Cette relation est clairement non linéaire. Il est en effet une relation quadratique. Une relation quadratique prend la forme Y = aX2 + bX + c.
La figure suivante montre un nuage de points dans lequel il ne semble pas y avoir de relation entre X et Y.

Les variables dans le nuage de points indiqués sont sans rapport ou independent- vous pouvez voir cela en l'absence de tout motif dans les données.
En plus de montrer la relation entre deux variables, un nuage de points peut aussi montrer la présence de valeurs aberrantes. La figure suivante montre un ensemble de données avec une observation qui est sensiblement différente de celle des autres observations.
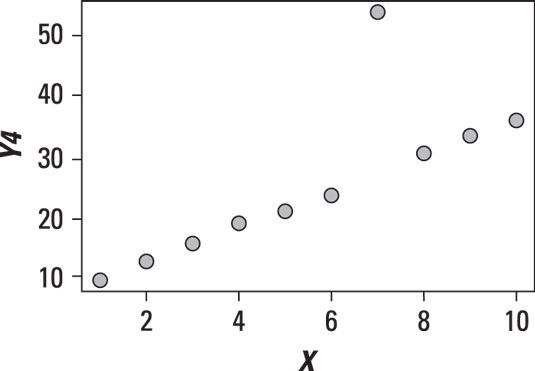
Le point de valeur aberrante doit être approfondie pour déterminer si elle est le résultat d'une erreur ou d'autres problèmes. Il est possible que la valeur aberrante devra être éliminées des données.
Tracés de normalité
Tracés de normalité sont utilisés pour voir à quel point les éléments d'un ensemble de données suivent la distribution normale. L'hypothèse de normalité est commun dans de nombreuses disciplines. Par exemple, il est souvent supposé dans la finance et l'économie que les rendements de stocks sont normalement distribués. L'hypothèse de normalité est très pratique, et de nombreux tests statistiques sont basées sur cette hypothèse.
L'application de tests statistiques qui supposent la normalité à un non-normale dataset donnerait des résultats très discutables. Par conséquent, il est important de déterminer si oui ou non les données est normalement distribué avant d'effectuer un quelconque de ces tests statistiques.
-
 Box parcelles: technique graphique pour les données statistiques
Box parcelles: technique graphique pour les données statistiques -
 Eda techniques pour tester des hypothèses
Eda techniques pour tester des hypothèses -
") L'analyse exploratoire des données (eda)
L'analyse exploratoire des données (eda) -
 Les tests graphiques de données aberrantes
Les tests graphiques de données aberrantes -
 Combien de propagation est là dans les données?
Combien de propagation est là dans les données? - Comment utiliser régressions linéaires dans l'analyse prédictive
Plusieurs tests statistiques officielles qui sont conçus pour détecter les données aberrantes. Trois d'entre elles prennent la forme de tests d'hypothèses. Un test d'hypothèse est une procédure pour déterminer si une proposition peut être…
UN parcelle quantile-quantile (également connu en tant que QQ-plot) Est une autre façon, vous pouvez déterminer si un ensemble de données correspond à une distribution de probabilité spécifié. QQ-parcelles sont souvent utilisées pour…
Contrairement à un diagramme à tiges et à feuilles, un nuage de points est destiné à montrer la relation entre deux variables. Il peut être difficile de voir si il ya une relation entre deux variables juste en regardant les données brutes,…
TI-Nspire permet la manipulation bidirectionnelle des données, ce qui signifie que vous pouvez modifier les valeurs dans les listes Application Tableur et regarder un données Statistiques mise à jour graphique automatiquement. De même, vous…
Votre travail ici est de trouver et d'interpréter les résultats d'une droite de régression et de ses éléments et de vérifier soigneusement exactement comment bien votre ligne correspond. Note: Régression suppose que vous avez trouvé qu'une…
Soyez conscient des parts de toute statistique descriptive vous calculez (par exemple, des dollars, des pieds ou miles par gallon). Quelques statistiques descriptives sont dans les mêmes unités que les données, et certains ne sont pas. Résoudre…
Pour obtenir une mesure de la variation sur la base du résumé de cinq nombre d'un échantillon statistique, vous pouvez trouver ce qu'on appelle la gamme interquartile, ou IQR.Le but du résumé de cinq nombre est de donner des statistiques…
Dans les statistiques, le coefficient de corrélation r mesure la force et la direction d'une relation linéaire entre deux variables sur un nuage. La valeur de r est toujours comprise entre 1 et -1. Pour interpréter sa valeur, voir lequel des…
Les diagrammes de dispersion sont utiles pour l'interprétation des tendances dans les données statistiques. Chaque observation (ou point) dans un nuage de points a deux coordinates- la première correspond à la première partie des données de la…
Quartiles diviser un ensemble de données en quatre parties égales, chacun composé de 25 pour cent des valeurs triées dans l'ensemble de données. Quartiles sont liés à percentiles comme ceci:Premier quartile (Q1) = 25e centileDeuxième…
UN nuage de points (également connu en tant que diagramme de dispersion) Montre la relation entre deux variables quantitatives (numériques). Ces variables peuvent être positivement corrélés, liée négativement, ou sans rapport…
Avant de tracer un graphique de données statistiques sur votre TI-84 Plus, appuyez sur [2] [ZOOM] et, si nécessaire, mettre en évidence CoordOn dans la deuxième ligne du menu Format et ExprOn dans la dernière ligne. Cela vous permet de voir le…
Avec la régression linéaire simple, vous recherchez un certain type de relation entre deux variables quantitatives (numériques) (comme GPA-lycée et au collège GPA.) Cette relation privilégiée est une relation linéaire - Celui dont les paires…
Plusieurs types de graphiques différents peuvent être utiles pour l'analyse des données. Ceux-ci comprennent des parcelles à tiges et à feuilles, nuages de points, des boîtes à moustaches, histogrammes, quantile-quantile (QQ), des…