Les tests graphiques de données aberrantes
Identification des données aberrantes est pas une question de couper-séché. Il peut y avoir désaccord sur ce qui fonctionne et ne pas être considérée comme une valeur aberrante. La définition de l'une aberration dépend de la distribution de probabilité supposée d'une population. Par exemple, si la population est vraiment normalement distribué, le graphique d'un ensemble de données doit avoir la même forme signature de cloche - si elle ne le fait pas, cela pourrait être un signe qu'il ya des valeurs aberrantes dans les données.
Vous pouvez utiliser trois techniques graphiques pour identifier les valeurs aberrantes:
Histogrammes
Les boîtes à moustaches
QQ-parcelles
Histogrammes
UN histogramme est un graphique utilisé pour représenter visuellement une distribution de probabilité d'une série de barres verticales. L'axe horizontal représente les valeurs ou les plages de valeurs pour la variable étudiée, et l'axe vertical indique les fréquences correspondantes de ces valeurs.
A titre d'exemple, l'indice 500 de Standard and Poor (SP 500) est un indice boursier qui représente les prix des 500 plus grandes actions américaines, pondérées par leur capitalisation boursière. Un stock de capitalisation boursière est égal au prix par moments d'actions le nombre d'actions en circulation.
La figure montre un histogramme des rendements journaliers pour le Standard & Poor 500 actions de l'indice de marché au cours des années 2009-2013.
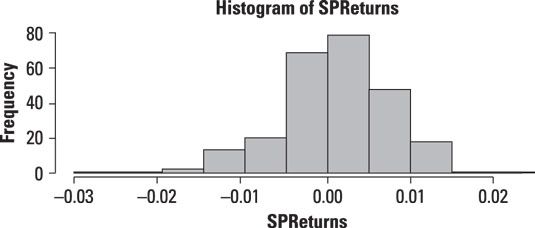
Selon cet histogramme, la plupart des rendements étaient proches de zéro au cours de cette période. Des rendements supérieurs à 0,01 (1 pour cent) ou en dessous de -0,01 (-1 pour cent) ont eu lieu relativement rarement. Toutefois, pour les déclarations qui ne se produisent en dehors de la petite plage autour de 0, l'apparition de rendements négatifs emportait sur l'apparition de rendements positifs, comme on le voit par l'extrême longueur de la queue gauche.
La forme de l'histogramme montre que la distribution des rendements à la Standard and Poor 500 durant cette période est peu probable d'être normale. Un problème est que la distribution normale est symétrique autour de sa valeur moyenne, tandis que l'histogramme montre que la distribution des rendements est asymétrie négative (qui est, il ya un déséquilibre entre les rendements négatifs et positifs, avec plus négatif que des rendements positifs).
Les boîtes à moustaches
UN boîte à moustaches montre la répartition de l'ensemble de données dans une boîte. La boîte est basée sur quartiles, qui sont comme des centiles, sauf qu'il n'y a que quatre d'entre eux. La boîte à moustaches est structuré comme suit:
Le haut de la boîte représente la le troisième quartile (ou quartile supérieur) (Q3) Des données. Ceci est équivalent à la 75ème centile.
Le fond de la boîte représente la premier quartile (ou quartile inférieur) (Q1) Des données. Ceci est équivalent à la 25ème centile.
Le milieu de la boîte (représenté par une ligne) représente le deuxième quartile (Q2) Des données (également connu sous le médiane).
Le premier quartile d'un ensemble de données est une valeur qui est supérieure à 25 pour cent des éléments de l'ensemble de données et inférieur au 75 pour cent restants. La deuxième quartile (autrement dit, la médiane) est une valeur qui est supérieure à 50 pour cent des éléments et inférieure à la 50 pour cent restants. Le troisième quartile est une valeur qui est supérieure à 75 pour cent des éléments et inférieure à la 25 pour cent restants.
La gamme interquartile (IQR) est défini comme la différence entre les troisième et premier quartiles:
IQR = Q3 - Q1
La IQR est utilisé en tant que mesure de dispersion, ou comment répartir les données sur le centre. Il peut également être utilisé pour identifier des valeurs aberrantes.
Pour une boîte à moustaches, il ya des lignes ci-dessus et en dessous de la boîte. La ligne du haut représente la valeur maximale dans un ensemble de données, à l'exclusion des valeurs aberrantes. La ligne du bas représente la valeur minimale dans un ensemble de données, toujours en excluant les valeurs aberrantes. Les différents points indiqués ci-dessus et en dessous de ces lignes sont les valeurs aberrantes dans l'ensemble de données.
Lorsque vous utilisez une boîte à moustaches, une valeur aberrante est définie comme suit:
Si un point de données est inférieur à Q1 - 1,5 (IQR), il est considéré comme une valeur aberrante.
Si un point de données est au-dessus Q3 + 1,5 (IQR), il est considéré comme une valeur aberrante.
La figure suivante montre une boîte à moustaches des rendements quotidiens à l'indice boursier S & P 500 au cours des années 2009-2013.
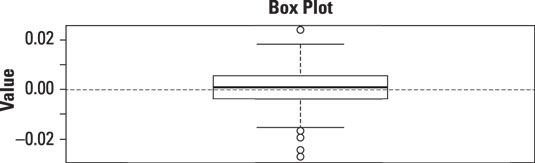
La boîte à moustaches montre qu'il existe une valeur aberrante qui est significativement plus grande que le reste des rendements dans l'ensemble de données. Il ya aussi quatre valeurs aberrantes qui sont nettement plus petit que le reste des rendements dans l'ensemble de données. L'existence de ces valeurs aberrantes montre que le jeu de données ne peut pas être distribué normalement.
QQ-parcelles
Vous pouvez tracer des données échantillon ayant un QQ-plot (courte pour complot quantile-quantile). Cette parcelle compare les quantiles de données de l'échantillon avec les quantiles d'une distribution de probabilité spécifiée, comme la normale.
Quantiles sont utilisés pour diviser un ensemble de données en groupes de taille égale fonction de la valeur d'une variable numérique particulier. Il existe plusieurs types de quantiles, dont les suivants:
Percentiles diviser un ensemble de données en 100 groupes égaux, chacun correspondant à un pourcentage du total. Par exemple, si un groupe de 1.000 étudiants prend un examen standardisé, et 200 d'entre eux reçoivent un score inférieur à 300, puis 300 serait le 20e percentile de cet ensemble de données. Cela indique que 20 pour cent des élèves ont obtenu en dessous de 300, tandis que les 80 pour cent restants marqué supérieure à 300.
Déciles diviser un ensemble de données en dix groupes égaux, chacun représentant 10 pour cent du total. Par exemple, la quatrième décile correspond au 40e percentile.
Quartiles diviser un ensemble de données en quatre groupes égaux, chacun représentant 25 pour cent du total. Par exemple, le troisième quartile correspond au 75e percentile.
La figure suivante montre un QQ-plot des rendements quotidiens de la SP 500 indice boursier du marché 2009-2013, par rapport à la distribution normale:
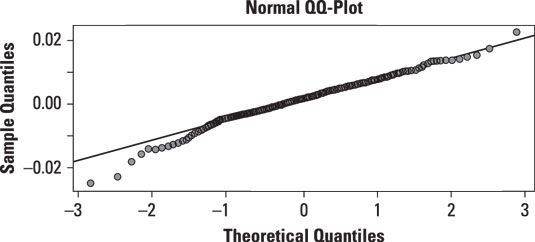
La ligne continue sur le graphique représente les quantiles de la distribution normale. 0 représente la signification par conséquent, la moitié des valeurs sont inférieures à 0, et la moitié sont au-dessus. Environ 95 pour cent des valeurs sont en dessous de 2 (2 représente deux écarts-types au-dessus de la moyenne), alors que 5 pour cent des valeurs sont en dessous de -2 (-2 représente deux écarts-types en dessous de la moyenne). Si les déclarations de SP ont été distribuées normalement, leurs quantiles devraient se trouver sur la ligne.
Les points sur le graphique sont les observations réelles dans le SP 500 données. Pour les quantiles normaux qui sont supérieures à 2 (qui est, deux écarts-types au-dessus de la moyenne), le SP 500 retours sont au-dessus de la ligne, ce qui indique que la queue droite est trop "gras" pour être cohérent avec la distribution normale. Pour quantiles normaux qui sont en dessous de -1 (qui est, un écart-type en dessous de la moyenne), le SP 500 rendements sont en dessous de la ligne, ce qui indique que la queue gauche est aussi trop gros pour être compatibles avec la distribution normale.
Dans l'ensemble, la distribution des rendements à la SP 500 semble être une distribution à queue grasse, ce qui signifie que les résultats extrêmes sont beaucoup plus susceptibles que ce serait le cas avec la distribution normale.
-
 Box parcelles: technique graphique pour les données statistiques
Box parcelles: technique graphique pour les données statistiques -
 Eda techniques pour tester des hypothèses
Eda techniques pour tester des hypothèses -
 techniques") Analyse exploratoire des données graphiques (eda) techniques
Analyse exploratoire des données graphiques (eda) techniques -
 Histogrammes: technique graphique pour les données statistiques
Histogrammes: technique graphique pour les données statistiques -
 Combien de propagation est là dans les données?
Combien de propagation est là dans les données? -
 Test d'hypothèse pour des données aberrantes
Test d'hypothèse pour des données aberrantes
Dans l'analyse des données, le rapport entre la moyenne et de la médiane peut être utilisée pour déterminer si une distribution est faussée. L'histogramme montre que la plupart des rendements sont proches de la moyenne, qui est 0,000632…
UN parcelle quantile-quantile (également connu en tant que QQ-plot) Est une autre façon, vous pouvez déterminer si un ensemble de données correspond à une distribution de probabilité spécifié. QQ-parcelles sont souvent utilisées pour…
En plus de la moyenne et de la variation, vous pouvez aussi jeter un oeil à les quantiles à R. A quantile, ou centile, vous indique combien de vos données est inférieure à une certaine valeur. Le quantile 50 pour cent, par exemple, est la même…
Mparticipants arché - les analystes financiers, les gestionnaires de risques, les gestionnaires de portefeuille, les commerçants et les économistes - doivent être capables de mesurer avec précision et de modéliser le risque et le rendement des…
Soyez conscient des parts de toute statistique descriptive vous calculez (par exemple, des dollars, des pieds ou miles par gallon). Quelques statistiques descriptives sont dans les mêmes unités que les données, et certains ne sont pas. Résoudre…
Vous pouvez utiliser votre calculatrice TI-84 Plus pour construire une boîte à moustaches pour vos données. Appuyez sur [2] [Y =] [2] pour l'accès Plot2. Suivez les étapes 1 à 9 pour la construction d'un histogramme. À l'étape 5,…
Pour obtenir une mesure de la variation sur la base du résumé de cinq nombre d'un échantillon statistique, vous pouvez trouver ce qu'on appelle la gamme interquartile, ou IQR.Le but du résumé de cinq nombre est de donner des statistiques…
Quartiles diviser un ensemble de données en quatre parties égales, chacun composé de 25 pour cent des valeurs triées dans l'ensemble de données. Quartiles sont liés à percentiles comme ceci:Premier quartile (Q1) = 25e centileDeuxième…
UN boîte à moustaches est un graphique unidimensionnel des données numériques basées sur le résumé en cinq nombres. Ce résumé comprend les statistiques suivantes: la valeur minimale, le 25e percentile (connu sous le nom Q1), La médiane, le…
Avant de tracer un graphique de données statistiques sur votre TI-84 Plus, appuyez sur [2] [ZOOM] et, si nécessaire, mettre en évidence CoordOn dans la deuxième ligne du menu Format et ExprOn dans la dernière ligne. Cela vous permet de voir le…
Si un ensemble de données statistiques a une distribution normale, il est coutumier de normaliser toutes les données pour obtenir des scores classiques connues comme z-valeurs ou z-scores. La distribution de z-valeurs prend une distribution…
Plusieurs types de graphiques différents peuvent être utiles pour l'analyse des données. Ceux-ci comprennent des parcelles à tiges et à feuilles, nuages de points, des boîtes à moustaches, histogrammes, quantile-quantile (QQ), des…
Parfois, vous voulez montrer comment une variable varie d'un groupe de sujets à l'autre. Par exemple, les niveaux de certaines enzymes sanguins varient entre les différentes races. Deux types de graphiques sont couramment utilisés à cette fin:…
Comme mettre deux personnes dos-à-dos pour voir qui est plus grand, Six Sigma utilisations boîtes à moustaches (ou juste boîtes à moustaches) de comparer directement les deux ou plusieurs distributions de variation. Lorsque vous avez besoin de…