Comment expliquer les résultats d'une classification des r analyse prédictive modèle
Une autre tâche de l'analyse prédictive est de classer les nouvelles données en prédisant quelle classe un élément de cible de données appartient, étant donné un ensemble de variables indépendantes. Vous pouvez, par exemple, de classer un client par type - par exemple, en tant que client de grande valeur, un client régulier, ou un client qui est prêt à passer à un concurrent - en utilisant un arbre de décision.
Pour voir quelques informations utiles sur le modèle de classification R, tapez le code suivant:
> Résumé (modèle) Longueur Classe Mode1 BinaryTreeS4
La Classe colonne vous dit que vous avez créé un arbre de décision. Pour voir comment les scissions sont déterminés, vous pouvez simplement taper le nom de la variable dans laquelle vous avez attribué le modèle, dans ce cas, modèle, comme ça:
> ModelConditional arbre de l'inférence avec 6 terminaux nodesResponse: seedTypeInputs: surface, le périmètre, la compacité, longueur, largeur, asymétrie, length2Number d'observations: 1471) région lt; = 16.2- critère = 1, statistique = 123,4232) zone lt; = 13.37- critère = 1, statistique = 63,5493) length2 lt; = 4.914- critère = 1, statistique = 22,2514) * poids = 113) length2> 4,9145) * poids = 452) zone> 13,376) length2 = 336) length2> 5,3968) * = 81) = zone 5.396- critère = 1, statistique = 16,317) * de poids de poids> 16.29) de length2; lt lt; = 5.877- critère = 0,979, statistique = 8.76410) * poids = 109) length2> 5,87711) * poids = 40
Encore mieux, vous pouvez visualiser le modèle en créant un terrain de l'arbre de décision avec ce code:> plot (modèle)
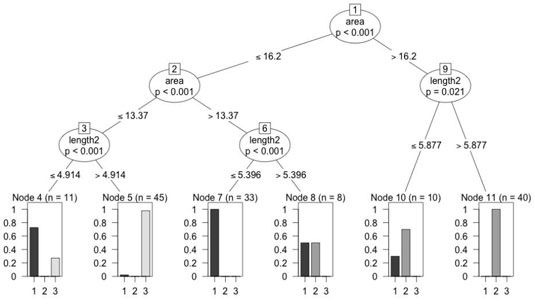
Ceci est une représentation graphique d'un arbre de décision. Vous pouvez voir que les imite globaux de forme que d'un vrai arbre. Il est fait de nœuds (les cercles et rectangles) et links ou bords (les lignes de connexion).
Le premier nœud (en partant du haut) est appelé le nœud racine et les noeuds dans la partie inférieure de l'arbre (rectangles) sont appelés noeuds terminaux. Il ya cinq nœuds de décision et six noeuds terminaux.
A chaque nœud, le modèle rend une décision fondée sur les critères dans le cercle et les liens, et choisit un chemin à parcourir. Quand le modèle atteint un noeud terminal, un verdict ou une décision finale soit prise. Dans ce cas particulier, deux attributs, le et le, sont utilisés pour décider si un type de semence donnée est dans la classe 1, 2 ou 3.
Par exemple, prenez l'observation n ° 2 de l'ensemble de données. Il a une de 4.956 et une 14,88. Vous pouvez utiliser l'arbre que vous venez de construire de décider quel type particulier de semences cette observation appartient. Voici la séquence d'étapes:
Commencez par le nœud racine, qui est le nœud 1 (le numéro est indiqué dans le petit carré en haut du cercle). Décider en fonction de l'attribut: Est ce que le n ° 2 de l'observation inférieur ou égal à (notée lt; =) 16.2? La réponse est oui, alors déplacer le long du chemin vers le noeud 2.
Au noeud 2, le modèle demande: Est-la région lt; = 13,37? La réponse est non, alors essayez le lien suivant qui vous demande: Est-la région> 13,37? La réponse est oui, alors déplacer le long du chemin vers le noeud 6. A ce noeud du modèle demande: Est ce que le length2 lt; = 5.396? Il est, et vous déplacer vers le noeud borne 7 et le verdict est que l'observation n ° 2 est de type de semences 1. Et il est, en fait, le type de semences 1.
Le modèle fait ce processus pour tous les autres observations pour prédire leurs classes.
Pour savoir si vous avez formé un bon modèle, vérifier contre les données de formation. Vous pouvez afficher les résultats dans un tableau avec le code suivant:
> Table (prévoir (modèle), rame $ seedType) 1 2 31 45 4 32 3 47 03 1 0 44
Les résultats montrent que l'erreur (ou taux d'erreur de classification) est de 11 sur 147, ou 7,48 pour cent.
Avec les résultats calculés, la prochaine étape est de lire la table.
Les prédictions correctes sont celles qui montrent le nombre de colonnes et de lignes que la même chose. Ces résultats montrent comme une ligne diagonale du haut à gauche vers en bas à droite; par exemple, [1,1], [2,2], [3,3] sont le nombre de prédictions correctes pour cette classe.
Donc, pour le type de semences 1, le modèle prédit correctement il 45 fois, tandis que la classification incorrecte de la graine 7 fois (4 fois que le type de semences, 2 et 3 fois que le type 3). Pour le type de semences 2, le modèle prédit correctement il 47 fois, tandis que la classification incorrecte de 3 fois. Pour le type de semences 3, le modèle prédit correctement il 44 fois, tandis que de mal classer une seule fois.
Cela montre que cela est un bon modèle. Alors maintenant, vous évaluez avec les données de test. Voici le code qui utilise les données de test pour prédire et de le stocker dans une variable (testPrediction) Pour une utilisation ultérieure:
> TestPrediction lt; - prédire (modèle, newdata = testSet)
Pour évaluer comment le modèle réalisée avec les données de test, voir dans un tableau et de calculer l'erreur, pour laquelle le code ressemble à ceci:
> Table (testPrediction, testSet $ seedType) testPrediction 2 31 23 1 2 12 1 19 03 1 0 17
Les résultats montrent que l'erreur est de 5 à 64, ou 7,81 pour cent. Ceci est cohérent avec les données d'apprentissage.
-
 Notions de base de modèles de classification pour les prédictions analytiques
Notions de base de modèles de classification pour les prédictions analytiques - Notions de base de l'analyse prédictive de données de traitement classifications
- Comment catégoriser les modèles d'analyse prédictive
- Comment créer un classement de r analyse prédictive modèle
- Comment créer un modèle d'analyse prédictive avec r régression
-
 Comment créer un modèle d'apprentissage supervisé par régression logistique
Comment créer un modèle d'apprentissage supervisé par régression logistique
Comme dans le monde réel, donc avec la multiplicité des modèles d'analyse prédictive: Là où il ya l'unité, il ya la force. Plusieurs modèles peuvent être combinés de différentes manières pour faire des prédictions. Vous pouvez ensuite…
Après que vous avez choisi votre nombre de grappes pour l'analyse prédictive et avez mis en place l'algorithme pour remplir les clusters, vous avez un modèle prédictif. Vous pouvez faire des prédictions basées sur les nouvelles données…
Une fois que vous créez un modèle de régression de R pour l'analyse prédictive, vous voulez être en mesure d'expliquer les résultats de l'analyse. Pour voir quelques informations utiles sur le modèle, le type dans le code suivant:> Résumé…
L'ensemble de données que nous analysons de faire une prédiction sur le jeu de données sur les semences, qui peut être trouvé à l'apprentissage automatique référentiel UCI. Cette base de données dispose de 210 observations et 7 attributs…
Pour faire des prédictions analytiques avec de nouvelles données, vous utilisez simplement la fonction avec une liste des valeurs d'attribut sept. Le code suivant fait ce travail:> NewPrediction lt; - prédire (modèle,
liste (cylindres =…
Pour exécuter une analyse prédictive, vous devez obtenir les données sous une forme que l'algorithme peut utiliser de construire un modèle. Pour ce faire, vous avez à prendre un certain temps à comprendre les données et de connaître sa…
L'apprentissage supervisé est une tâche d'apprentissage qui apprend à la machine à partir de données d'analyse de prédiction qui ont été marqués. Une façon de penser à propos de l'apprentissage supervisé est que l'étiquetage des…
Avant que vous pouvez nourrir le classificateur Support Vector Machine (SVM) avec les données qui ont été chargés pour l'analyse prédictive, vous devez diviser l'ensemble de données complet en un ensemble de formation et un ensemble de…
UN arbre de décision est une méthode d'analyse prédictive qui peut vous aider à prendre des décisions. Supposons, par exemple, que vous avez besoin pour décider d'investir une certaine somme d'argent dans l'un des trois projets d'affaires: une…
Dans Analytics supervisées, l'entrée et la sortie préférée font partie des données de formation. Le modèle d'analyse prédictive est présenté avec les résultats corrects dans le cadre de son processus d'apprentissage. Un tel apprentissage…
Visualisation des résultats de votre analyse prédictive aide vraiment les parties prenantes à comprendre les prochaines étapes. Voici quelques façons d'utiliser des techniques de visualisation de rapporter les résultats de vos modèles pour…
L'exploration de données consiste à explorer et d'analyser de grandes quantités de données pour trouver des modèles pour les grandes données. Les techniques sont sortis des domaines de la statistique et de l'intelligence artificielle (IA),…
En Java, vous utilisez le DTree classe pour créer un composant d'arbre qui affiche les noeuds d'un arbre. Pour l'utiliser correctement, consultez les constructeurs et les méthodes de cette classe clés.ConstructeurDescriptionannuler JTree ()Crée…
La dichotomie entre la pensée linéaire et sépare la pensée holistique (respectivement) de SAX du DOM.SAX (de Simple API for XML) traite un document XML de façon linéaire, en travaillant dans un document pièce par pièce, du début à la fin.…