Construire un code personnalisé avec l'API Java for XML Binding (JAXB)
Vous pouvez construire un code personnalisé avec JAXB
Sommaire
Lorsque vous écrivez SAX DOM ou un code, vous créez un programme de traitement de XML. Votre programme lit un document, et utilise le document à faire un travail utile - à commencer par quelque chose inoffensive comme startElement public void ou node.getNodeName (). De toute façon, votre programme ne fait aucune hypothèse sur ce qui est à l'intérieur du document. Le document a une racine élément, certains éléments de l'enfant, et voilà tout. Toutes les hypothèses spéciales que vous faites sur ce document rétrécissent effectivement l'utilité du code.
Code polyvalent contre le code personnalisé
Considérons le code dans Listes 1 et 2. Le listing 1, balaie cinq noeuds dans un arbre du document. Ces cinq nœuds doivent être disposés d'une certaine façon, ou bien le programme plante. (La liste veut un commentaire et un noeud racine, avec au moins deux enfants directement sous le noeud racine.)
Liste 1: Affichage de quelques noeuds
importation org.w3c.dom.Node-
importation org.w3c.dom.NamedNodeMap-
classe MyTreeTraverser
{
MyTreeTraverser (nœud Node)
{
System.out.println (node.getNodeName ()) -
node = node.getFirstChild () -
System.out.println (node.getNodeName ()) -
node = node.getNextSibling () -
System.out.println (node.getNodeName ()) -
node = node.getFirstChild () -
System.out.println (node.getNodeName ()) -
node = node.getNextSibling () -
System.out.println (node.getNodeName ()) -
}
}
Liste 2: Traverser l'arbre DOM
importation org.w3c.dom.Node-
importation org.w3c.dom.NamedNodeMap-
classe MyTreeTraverser
{
Noeud node-
MyTreeTraverser (nœud Node)
{
this.node = node-
afficher un nom()-
valeurAffichée () -
si (node.getNodeType () == node.ELEMENT_NODE)
displayAttributes () -
System.out.println () -
displayChildren () -
}
annuler displayName ()
{
System.out.print ("Nom:") -
System.out.println (node.getNodeName ()) -
}
annuler valeurAffichée ()
{
Chaîne nodeValue = node.getNodeValue () -
si (nodeValue! = null)
nodeValue = nodeValue.trim () -
System.out.print ("Valeur") -
System.out.println (nodeValue) -
}
displayAttributes void ()
{
NamedNodeMap attribs = node.getAttributes () -
for (int i = 0 à i lt; attribs.getLength () - i ++)
{
System.out.println () -
System.out.print ("Attribut:") -
System.out.print (attribs.item (i) .getNodeName ()) -
System.out.print ("=") -
System.out.println (attribs.item (i) .getNodeValue ()) -
}
}
displayChildren void ()
{
Noeud enfant = node.getFirstChild () -
while (enfant! = null)
{
nouvelle MyTreeTraverser (enfant) -
enfant = child.getNextSibling () -
}
}
}
Le code du listing 2 est beaucoup plus général. Ce code vérifie la structure du document car il fonctionne. Lorsque le code trouve un nœud enfant, il scanne l'enfant et cherche des petits-enfants. Si il n'y a pas des petits-enfants, le code cherche frères et sœurs. Le code peut gérer tout arbre du document - si elle a un noeud ou mille nœuds.
Ainsi, Liste 2 est plus polyvalent que Listing 1. Toutefois, cette polyvalence est livré avec inconvénients - y compris la possibilité de très haut dans le ciel. Le code du listing 2 doit analyser le document XML entier - et ensuite mettre une représentation de l'arbre du document dans la mémoire de l'ordinateur. Si le document est très grand, alors la représentation est importante: mémoire est pléthorique avec tout ce que les données temporaires, et le code du listing 2 ralentit à un rampement.
Les avantages de la personnalisation
Imaginez que vous essayez de conduire à Faneuil Hall à Boston, Massachusetts. Il n'a pas d'importance où vous commencez FROM- le voyage sera toujours déroutant et difficile. Quoi qu'il en soit, vous devez planifier votre itinéraire. Vous pouvez vous perdre dans les environs de Revere ou Cambridge ou au centre-ville de Boston. En fonction de vos ressources, vous avez deux options:
- Vous pouvez vous arrêter à une station d'essence et acheter une carte. Si vous le faites, alors vous pouvez ne jamais obtenir de Faneuil Hall. Après tout, vous devez trouver où vous êtes sur la carte, rechercher des itinéraires alternatifs, choisir un itinéraire, puis (le ciel vous aider) essayer de suivre la route sans se perdre à nouveau.
- Vous pouvez dire à votre, parler système GPS cher que vous voulez vous rendre à Faneuil Hall. Le système va tracer un itinéraire personnalisé et vous guider, tour à tour, à partir de quelque lieu que vous êtes malheureux pour l'itinéraire optimal qui mène de là à Faneuil Hall. La route est tellement personnalisé que la voix de GPS dit (par exemple), "Il n'y a pas de signe à cette intersection, tourner à gauche, mais de toute façon." Plus tard, la voix dit: «Il ya deux signes à cette intersection, et les signes contredisent. Mais de toute façon, tourner à droite."
Utilisation de la carte papier prend plus de travail (plus de temps, d'effort, de la dextérité et de patience) que d'utiliser le GPS parlant. Pourquoi? Parce que la carte papier ne soit pas adapté à votre BESIONS spécifique en vigueur, il dit: «Voici l'ensemble de la région métropolitaine de Boston. Faneuil Hall est là quelque part. Tu comprendre ce qu'il faut faire ensuite. "
Un système de mesure est (comme on pouvait s'y attendre) plus facile à utiliser que celui qui est pas adapté à votre situation immédiate. Ainsi, le code de traitement XML du listing 2 fait une énorme ressource-avalant arbre DOM dans l'espace de la mémoire de votre ordinateur ("Voici l'arbre - tu comprendre ce qu'il faut faire ensuite. . .. ") Parce que le code est pas personnalisé Le code fonctionne pour tout vieux document - pas seulement celui que vous avez sous la main - et avale toujours les ressources pour le faire.
L'essence de JAXB
L'idée derrière JAXB est de créer la classe sur mesure pour répondre à vos besoins actuels. Vous prenez la description d'un document XML, le lancer à travers un programme spécial appelé compilateur de schéma, et obtenir une nouvelle classe de la marque appelé classe générée. Cette classe générée est simplifié à travailler avec notamment des documents XML.
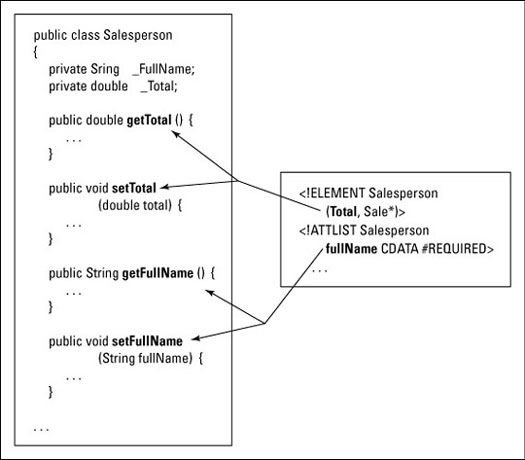
Par exemple, si vos documents XML ont éléments nommés total, alors la classe générée peut avoir des méthodes setTotal et GetTotal. Si l'élément du document a un attribut fullName, puis la classe générée peut avoir des méthodes setFullName et getFullName. (Voir Figure 1.)
La connexion entre une partie d'un document XML et une partie d'une classe Java est appelée contraignant. Avec toutes ces liaisons, une instance de la classe représente un seul document XML.
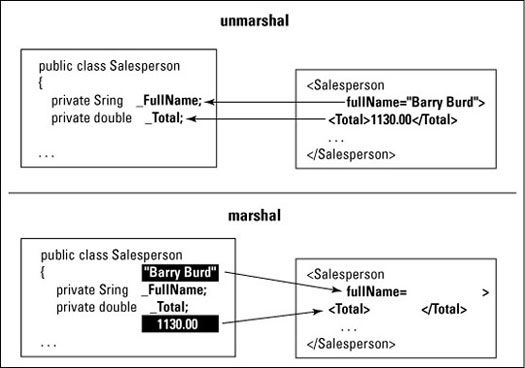
Alors, comment voulez vous connectez un objet avec un document XML? Eh bien, la classe générée a méthodes nommées unmarshal et le maréchal. (Voir Figure 2.)
- La méthode unmarshal lit un fichier XML. La méthode obtient les valeurs du document XML, et attribue ces valeurs aux variables dans l'objet Java.
- Le procédé de conversion écrit un fichier XML. La méthode obtient les valeurs de l'objet Java, et utilise ces valeurs pour créer le document XML.
Avec de telles méthodes, vous pouvez récupérer et modifier les données dans un document XML.



Java a une classe nommée Entier, et l'ensemble Entier classe a une méthode statique appelée parseInt. Si quelqu'un vous tend une chaîne de caractères, et que vous voulez faire de cette chaîne en un int valeur, vous pouvez appeler le Entier La…
Pour faire quelque chose d'utile avec le code que vous écrivez dans Java, vous avez besoin d'un principal Procédé. Vous pouvez mettre le principal méthode dans un fichier séparé. Tout d'abord, nous allons commencer avec un “…
Bien que les interfaces sont une caractéristique très utile de Java, ils ont une limite intrinsèque: Après avoir défini une interface et ensuite construire des classes qui implémentent l'interface, il n'y a pas de moyen facile de modifier…
En Java, vous pouvez regrouper un tas de classes dans ce qu'on appelle un package. En fait, les classes API standard de Java sont divisés en environ 200 paquets. Ici, vous pouvez vérifier les paquets nommés java.util, java.lang, et java.io.Le…
Le mot-clé ce en Java se réfère à l'instance de classe actuelle. Par exemple, si une classe définit une méthode nommée Calculer, vous pouvez appeler cette méthode d'une autre méthode dans la même classe comme ceci:this.Calculate () -Bien…
La ce mot-clé fournit un moyen de se référer à l'instance actuelle de l'objet en Java. Il est souvent utilisé pour distinguer entre une variable locale ou un paramètre et un champ de classe avec le même nom. Par example:Ball public class…
Java vous donne la possibilité d'écrire un programme axé sur disque. En fait, il est parfois plus facile d'utiliser une partie de votre code de pré-existante et ajouter un peu de montage simple. Voici comment:Ajoutez les déclarations…
Dans le Listing 1, ci-dessous, vous obtenez un souffle de code Java. Comme tous les programmeurs débutants, vous êtes censé gawk humblement le code. Mais ne soyez pas intimidé. Lorsque vous obtenez le coup de lui, la programmation est assez…
Les développeurs Java ont souvent des problèmes à comprendre pourquoi une application se comporte mal en cas de problème d'accès de bloc. La ligne directrice de base est que toute variable que vous créez dans un bloc est défini uniquement…
Shadowing se réfère à la pratique de la programmation Java en utilisant deux variables avec le même nom dans les champs qui se chevauchent. Quand vous faites cela, la variable avec le champ d'application de niveau supérieur est caché parce que…
La dichotomie entre la pensée linéaire et sépare la pensée holistique (respectivement) de SAX du DOM.SAX (de Simple API for XML) traite un document XML de façon linéaire, en travaillant dans un document pièce par pièce, du début à la fin.…
La bibliothèque jQuery transforme des objets DOM dans les ganglions jQuery puissants. Le tableau suivant présente quelques-unes des méthodes du noeud jQuery les plus couramment utilisés.MéthodeDescriptionaddClass (), removeClass (), toggleClass…
Le but de toute application javascript est de gérer le contenu. Cela signifie l'ajout, la suppression et la modification du document HTML qui contient les différents éléments qui soutiennent la structure et le contenu. Ces objets donnent…
Arbres DOM HTML ressemblent à des arbres de la famille dans la relation hiérarchique entre les nœuds. En fait, les termes techniques utilisés par les programmeurs javascript pour décrire les relations entre les noeuds dans un arbre…