Comment utiliser les données dans le format grand dans les parcelles de réseau dans r
Lorsque vous avez des données dans les hautes format R, vous pouvez facilement utiliser treillis graphiques pour visualiser les sous-groupes dans vos données. Par exemple, ce qui se passe lorsque vous souhaitez analyser plus d'une variable simultanément?
Considérons l'ensemble de données intégré Longley, contenant des données sur l'emploi, le chômage, et d'autres indicateurs de la population:
> Str (Longley) 'data.frame': 16 obs. de 7 variables: $ GNP.deflator: num 83 88,5 88,2 89,5 96,2 $ ... PNB: num 234 259 258 285 329 $ ... Chômeur: NUM 236 232 368 335 210 $ ... Armed.Forces NUM 159 146 162 165 310 $ ... Population: 108 109 num 110 111 112 $ ... Année: int 1947 1948 1949 1950 1951 1952 1953 1954 1955 1956 $ ... Employé: num 60,3 61,1 60,2 61,2 63,2 ...
Une façon d'analyser facilement les différentes variables d'une trame de données est d'abord de remodeler la trame de données de grand format au format haut.
Une trame de données large contient une colonne pour chaque variable. Une trame de données de haut contient toutes les mêmes informations, mais les données sont organisées de telle manière que une colonne est réservé pour identifier le nom de la variable et une seconde colonne contient les données réelles.
Un moyen facile de remodeler une trame de données de grand format au format haute est d'utiliser la fondre () en fonction de la reshape2 package. Rappelez-vous: reshape2 ne fait pas partie de la base R - il est un paquet d'add-on qui est disponible sur CRAN. Vous pouvez l'installer avec le install.packages ("reshape2") fonction.
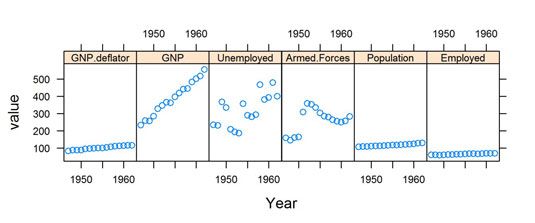
> Bibliothèque ("reshape2")> mlongley lt; - fondre (Longley, id.vars = "Année")> str (mlongley) 'data.frame': 96 obs. de 3 variables: $ Année: int 1947 1948 1949 1950 1951 1952 1953 1954 1955 1956 $ ... variables: Facteur W / 6 niveaux "GNP.deflator", ..: 1 1 1 1 1 1 1 1 1 1 .. . $ value: num 83 88,5 88,2 89,5 96,2 ...Maintenant, vous pouvez tracer la trame de données de haut mlongley et utiliser les nouvelles colonnes valeur et variable dans la formule valeur ~ Année | variable.
> Xyplot (valeur ~ Année | variables, données = mlongley, + layout = c (6, 1), + par.strip.text = liste (CEX = 0,7), + échelles = liste (CEX = 0,7) +)
Les arguments supplémentaires par.strip.text et balance contrôler la taille des caractères (caractère taux d'expansion) de la bande en haut de la carte, ainsi que l'échelle.
Lorsque vous créez des parcelles avec plusieurs groupes, assurez-vous que le complot résultant est significatif. Par exemple, l'unité de PNB (court pour Produit National brut) Est probablement des milliards de dollars. En revanche, l'unité de la population est probablement des millions de personnes. (La documentation de la Longley ensemble de données est pas claire sur ce sujet.)
Soyez très prudent lorsque vous présentez parcelles comme cela - vous ne voulez pas être accusé de création tableau indésirable (trompeuse graphiques).
-
 Osi pour CCNA couche 2: liaison de données
Osi pour CCNA couche 2: liaison de données -
 Comment contrôler l'ordre variable dans un ensemble de données
Comment contrôler l'ordre variable dans un ensemble de données - Comment ajouter des variables à une trame de données dans r
-
 Comment jeter des données à format large en r
Comment jeter des données à format large en r - Comment convertir les tables à une trame de données dans r
- Comment compter les valeurs de données uniques dans r
Vous pouvez créer une trame de données à partir d'une matrice dans R. Jetez un oeil à le nombre de paniers marqués par Granny et son amie Géraldine. Si vous créez une matrice baskets.team avec le nombre de paniers pour les deux dames, vous…
La conversion d'une matrice à une trame de données dans R ne peut pas être utilisé pour construire une trame de données avec différents types de valeurs. Si vous combinez les deux données numériques et de caractère dans une matrice, par…
Explorer treillis graphiques dans R, d'abord jeter un oeil à l'ensemble de données intégré mtcars. Cette base de données contient 32 observations de voitures et des informations sur le moteur, comme le nombre de cylindres, automatiques contre…
Base de R comporte une fonction, remodeler (), Cela fonctionne très bien pour la refonte de données. Cependant, l'auteur original de cette fonction avait à l'esprit un cas d'utilisation spécifiques pour remodeler: données dites…
Dans de nombreux cas, vous pouvez extraire des valeurs d'une trame de données dans la R en prétendant qu'il est une matrice. Mais bien que les trames de données peuvent ressembler à des matrices, ils ne sont certainement pas. Contrairement…
Chaque fonction dans R attend vos données soient dans un format spécifique. Cela ne signifie pas simplement de savoir si il est un entier, caractère, ou un facteur, mais aussi si vous fournissez un vecteur, une matrice, une trame de données, ou…
Si vous avez téléchargé et importé ggplot2 pour une utilisation dans votre installation de R, vous pouvez l'utiliser pour tracer vos données. Pour créer un nuage de points, vous utilisez le geom_point () fonction. Pour créer un graphique en…
Lorsque vous utilisez R, considérer les mots large et long comme des métaphores visuelles pour la forme de vos données. En d'autres termes, les données large a tendance à avoir plus de colonnes et de rangées de moins par rapport aux données…
Avec R à votre portée, vous pouvez rapidement façonner vos données exactement comme vous le voulez. Voilà bien parce que dans de nombreux cas de la vie réelle, vous obtenez des tas de données dans un gros fichier, et de préférence dans un…
Une tâche très commune dans l'analyse de données et de reporting est le tri des informations, que vous pouvez faire facilement dans R. Vous pouvez répondre à de nombreuses questions quotidiennes avec tableaux de classement - tables triées de…
Maintenant que vous avez examiné les règles pour la création de sous-ensembles, vous pouvez l'essayer avec quelques trames de données dans R. Vous avez juste à rappeler que une trame de données est un objet bidimensionnel et contient des…
Variables dans une trame de données dans la R toujours besoin d'avoir un nom. Pour accéder aux noms de variables, vous pouvez encore traiter une trame de données comme une matrice et utiliser la fonction colnames () comme ça:> Colnames…
Une différence importante entre une matrice et une trame de données dans R est que les trames de données sont toujours nommé observations. Alors que le rownames () retour de la fonction NUL si vous ne spécifiez pas les noms de lignes d'une…
La calculatrice TI-83 Plus peut effectuer une analyse statistique à une et à deux variables données. Pour les deux variables d'analyse de données, la variable de données pour la première liste de données est désignée par X et la variable de…