Comment détecter et prévenir les hacks de traversée de répertoire
Traversée de répertoire est une faiblesse très basique, mais il peut tourner jusqu'à intéressante - des informations sur un système Web, le rend vulnérable aux hacks - parfois sensibles. Cette attaque consiste parcourant un site et recherche d'indices sur la structure de répertoires du serveur et des fichiers sensibles qui pourraient avoir été chargés, intentionnellement ou non.
Effectuez les tests suivants pour déterminer des informations sur la structure des répertoires de votre site web.
Crawlers
Un programme d'araignée, comme le site Web de HTTrack gratuitement Copieur, peut explorer votre site à la recherche de tous les fichiers accessibles au public. Pour utiliser HTTrack, simplement charger, lui donner un nom au projet, dites HTTrack quel site (s) au miroir, et après quelques minutes, peut-être des heures, vous aurez tout ce qui est accessible au public sur le site stockée sur votre disque local dans c: Mes sites.
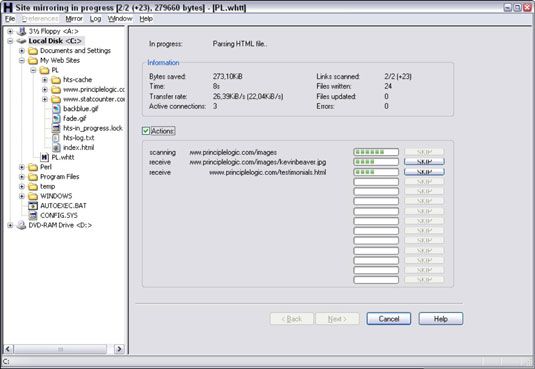
Les sites complexes révèlent souvent plus d'informations qui ne devraient pas être là, y compris les anciens fichiers de données et même des scripts d'application et le code source.
Inévitablement, lors de l'exécution des évaluations de sécurité web, il ya généralement .fermeture éclair ou .rar fichiers sur les serveurs web. Parfois, ils contiennent ordure, mais souvent ils détiennent des informations sensibles qui ne devraient pas être là pour le public d'accéder.
Regardez la sortie de votre programme de ramper pour voir quels fichiers sont disponibles. Fichiers HTML et PDF régulières sont probablement correct parce qu'ils sont plus susceptibles nécessaires pour l'utilisation du web normale. Mais il ne serait pas mal d'ouvrir chaque fichier pour vérifier qu'il appartient là et ne contient pas d'informations sensibles que vous ne voulez pas partager avec le monde.
Google peut également être utilisé pour une traversée de répertoire. En fait, les requêtes avancées de Google sont si puissants que vous pouvez les utiliser pour extirper des informations sensibles, les fichiers et les répertoires du serveur Web critiques, numéros de cartes de crédit, les webcams - fondamentalement quelque chose que Google a découvert sur votre site - sans avoir à refléter votre site et passer au crible tout manuellement. Il est déjà assis là dans le cache de Google en attente d'être vu.
Ce qui suit est un couple de requêtes avancées de Google que vous pouvez entrer directement dans le champ de recherche Google:
Mots-clés de nom d'hôte: le site - Cette requête recherche d'un mot clé vous énumérez, comme SSN, confidentiel, carte de crédit, et ainsi de suite. Un exemple serait:
Site: principlelogic.com haut-parleur
filetype: Site extension de fichier: nom d'hôte - Cette requête recherche des types de fichiers spécifiques sur un site web spécifique, comme doc, pdf, db, DBF, fermeture éclair, et plus. Ces types de fichiers peuvent contenir des informations sensibles. Un exemple serait:
filetype: pdf Site: principlelogic.com
D'autres opérateurs Google avancés sont les suivants:
allintitle recherche de mots clés dans le titre d'une page Web.
inurl recherche de mots clés dans l'URL d'une page web.
connexe Trouve les pages similaires à cette page web.
lien montre d'autres sites qui pointent vers cette page web.
Une excellente ressource pour Google hacking est Google Hacking base de données de Johnny long.
Lorsque tamisage à travers votre site avec Google, assurez-vous de chercher des informations sensibles sur vos serveurs, réseau, et l'organisation de Google Groupes, qui est l'archive Usenet. Si vous trouvez quelque chose qui n'a pas besoin d'être là, vous pouvez travailler avec Google pour avoir édité ou enlevé. Pour plus d'informations, reportez-vous à Google de page Contactez-nous.
Mesures contre traversées de répertoires
Vous pouvez employer des trois principales contre-mesures contre les fichiers ayant compromis via malveillants traversées de répertoires:
Ne pas stocker les fichiers anciens, sensibles, ou autrement non publiques sur votre serveur web. Les seuls fichiers qui doivent être dans votre / htdocs ou DocumentRoot dossier sont ceux qui sont nécessaires pour que le site fonctionne correctement. Ces fichiers ne doivent pas contenir des informations confidentielles que vous ne voulez pas le monde à voir.
Configurez votre robots.txt fichier pour empêcher les moteurs de recherche, tels que Google, de ramper les zones les plus sensibles de votre site.
Assurez-vous que votre serveur Web est correctement configuré pour permettre l'accès du public aux seuls répertoires qui sont nécessaires pour que le site fonctionne. Privilèges minimums sont la clé ici, donc donnent accès à uniquement les fichiers et les répertoires nécessaires à l'application Web pour fonctionner correctement.
Consultez la documentation de votre serveur Web pour obtenir des instructions sur le contrôle de l'accès du public. Selon la version de votre serveur Web, ces contrôles d'accès sont mis en
La httpd.conf fichier et le .htaccess fichiers pour Apache.
Internet Information Services Manager pour IIS
Les dernières versions de ces serveurs Web ont une bonne sécurité de répertoire par défaut donc, si possible, assurez-vous que vous utilisez les dernières versions.
Enfin, pensez à utiliser un pot de miel de moteur de recherche, tels que Google Hack Honeypot. Un pot de miel attire des utilisateurs malveillants afin que vous puissiez voir comment les méchants travaillent contre votre site. Ensuite, vous pouvez utiliser les connaissances acquises pour les tenir à distance.
-
 Une étude de cas dans le piratage d'applications web
Une étude de cas dans le piratage d'applications web - Script par défaut hacks dans les applications web
- Comment utiliser l'empreinte de planifier une bidouille éthique
- Comment télécharger un site Web existant dans Dreamweaver
- Accéder à des fichiers partout avec Google Drive sur votre Nexus 7
-
 Comment tirer parti de votre page Google + pour obtenir de meilleurs résultats de recherche pour votre site web
Comment tirer parti de votre page Google + pour obtenir de meilleurs résultats de recherche pour votre site web
Dans le cas où votre site a des pages de profil individuel pour chaque auteur, vous pouvez lier les noms des auteurs vers les pages de profil sur votre site web d'entreprise. Vous pouvez également indiquer à Google, sur chacune des pages de…
Lier votre entreprise Google+ page à vos annonces est un excellent moyen d'apporter plus de goûts et d'obtenir plus de personnes à la suite de la présence de votre marque sur Google+. En ajoutant une page Google+ à votre annonce, vous activez…
Vous pouvez utiliser un fichier texte robots pour bloquer une araignée moteur de recherche à partir de l'exploration de votre site Web ou une partie de votre site. Par exemple, vous pouvez avoir une version de développement de votre site Web où…
Afin de contrôler le workflow, Contribute installe un fichier dans un dossier spécifique à la racine de tout site Web vous vous connectez. Ce fichier, appelé le fichier de paramètres partagés, permet Contribuer à stocker tous les paramètres…
Après avoir téléchargé et décompresser vos fichiers Joomla, vous les téléchargez sur votre FAI. Il ya beaucoup de fournisseurs de services Internet qui peuvent fonctionner Joomla. Pour la plupart, tout FAI qui vous donne accès à PHP et…
Avec un compte Google, vous pouvez accéder à Google Outils pour les webmasters et obtenir une pléthore d'informations et d'outils pour vous donner une chance de se battre contre les sites concurrents. Google est décidément le roi et la reine…
Si votre hébergeur ne utilise Fantastico ou Softaculous, la première étape pour l'installation de Drupal est d'obtenir un exemplaire de la dernière version de Drupal et le déplacer vers votre serveur web.Télécharger le packageObtenir une…
Avec Drupal 7, vous pouvez ajouter des modules et thèmes pour votre site en téléchargeant le fichier et l'installer manuellement. Il est bon de savoir comment le faire vous-même afin de comprendre comment cela fonctionne. Installation manuelle…
Comment savez-vous comment votre site se classe dans les moteurs de recherche? Vous pouvez aller à un moteur de recherche, tapez un mot clé, et de voir ce qui se passe. Si vous n'êtes pas sur la première page, cochez la deuxième si vous n'êtes…
Vous pouvez créer un fichier sitemaps de diverses manières. Google fournit le programme Sitemap Generator, que vous pouvez installer sur votre web server-il est un script Python, donc si vous ne savez pas ce que cela signifie et ne pas avoir un…
Les moteurs de recherche obtenir des indices sur la nature d'un site à partir de son nom de domaine ainsi que des fichiers et des répertoires de la structure du site. L'ascenseur ajoutée est probablement pas très grande, mais chaque petit geste…
Vous avez probablement vu “ présentation ” services annoncés, peut-être sous la forme de spam dans votre boîte de réception, offrant de soumettre votre site Web à des centaines de moteurs de recherche. Dans la plupart des cas, ces…
Il est extrêmement difficile pour les moteurs de recherche pour trouver les vidéos de marketing sur votre site web. Le problème est que tant de lecteurs vidéo et les entreprises d'hébergement vidéo sont là qu'aucun moteur de recherche peut…
Rendre votre site visible est l'élément le plus fondamental de l'optimisation de moteur de recherche (SEO). Si les moteurs de recherche ne peuvent pas trouver vos pages Web, ou si ils peuvent les trouver, mais ils ont des liens brisés, des pages…