Comment tracer des données résumées dans un ggplot2 dans r
Une caractéristique très pratique de ggplot2
Sommaire
Le résumé statistique pour cela est de compter les observations. Statisticiens se réfèrent à ce processus binning, et la stat de défaut pour geom_bar () est stat_bin ().
De manière analogue à la façon dont chaque geom a une stat de défaut associée, chaque stat a également un geom par défaut.
Donc, cela soulève la question: Comment décidez-vous si vous souhaitez utiliser un geom ou une stat? En théorie, il n'a pas d'importance si vous choisissez le geom ou la stat premier. Dans la pratique, cependant, il est souvent intuitive de commencer avec un type de tracé première - en d'autres termes, spécifier un geom. Si vous souhaitez ensuite ajouter une autre couche de résumé statistique, utiliser une stat.
Dans ce terrain, vous avez utilisé les mêmes données d'abord créer un nuage de points avec geom_point () puis vous avez ajouté une ligne lisse avec stat_smooth ().
Jetez un oeil à quelques exemples pratiques d'utilisation stat fonctions.
| Stat | Description | Par défaut Geom |
|---|---|---|
| stat_bin () | Compte le nombre d'observations dans les bacs. | geom_bar () |
| stat_smooth () | Crée une ligne lisse. | geom_line () |
| stat_sum () | Ajoute valeurs. | geom_point () |
| stat_identity () | Aucun résumé. Emplacements données est. | geom_point () |
| stat_boxplot () | Résume les données pour une parcelle boîte et moustaches. | geom_boxplot () |
| Comment bin données ggplot2 |
Vous avez déjà vu comment utiliser stat_bin () pour résumer vos données dans des bacs, parce que cela est la stat de défaut de geom_bar (). Cela signifie que les deux lignes de code suivantes produisent parcelles identiques:
> Ggplot (tremblements de terre, AES (x = profondeur)) + geom_bar (binwidth = 50)> ggplot (tremblements de terre, AES (x = profondeur)) + stat_bin (binwidth = 50)
Comment lisser les données R dans ggplot2
La ggplot2 forfait rend également très facile de créer des lignes de régression à travers vos données. Vous utilisez le stat_smooth () fonction pour créer ce type de ligne.
La chose intéressante à propos stat_smooth () est que cela rend l'utilisation de la régression locale par défaut. R dispose de plusieurs fonctions qui peuvent le faire, mais ggplot2 utilise le loess () fonction de régression locale. Cela signifie que si vous voulez créer un modèle de régression linéaire que vous avez à dire stat_smooth () d'utiliser une fonction lisse différente. Vous faites cela avec le méthode argument.
Pour illustrer l'utilisation d'un plus lisse, commencez par créer un nuage de chômage dans la Longley ensemble de données:
> Ggplot (Longley, AES (x = Année, y = Employé)) + geom_point ()
Ensuite, ajouter un plus lisse. Cela est aussi simple que d'ajouter stat_smooth () à votre ligne de code.
> Ggplot (Longley, AES (x = Année, y = Personnes occupées)) ++ geom_point () + () stat_smooth
Enfin, dites- stat_smooth à utiliser un modèle de régression linéaire. Vous faites cela en ajoutant l'argument method = "LM".
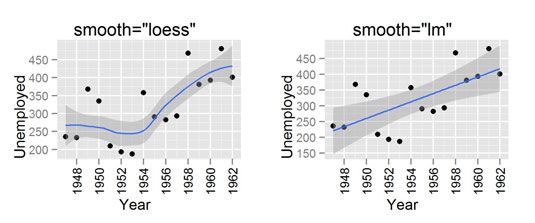
> Ggplot (Longley, AES (x = Année, y = Personnes occupées)) ++ geom_point () + stat_smooth (method = "LM")
Comment dire ggplot2 laisser vos données unsummarized
Parfois, vous ne voulez pas ggplot2 pour résumer vos données dans le complot. Cela se produit généralement lorsque vos données est déjà pré-résumé ou lorsque chaque ligne de votre bloc de données doit être tracée séparément. Dans ces cas, vous voulez dire ggplot2 de ne rien faire du tout, et la stat de le faire est stat_identity ().
-
 Ggplot2 en r: comment mapper les données à des lignes, des points, des symboles et plus
Ggplot2 en r: comment mapper les données à des lignes, des points, des symboles et plus -
 Comment ajouter des facettes, des échelles, et des options dans ggplot2 dans r
Comment ajouter des facettes, des échelles, et des options dans ggplot2 dans r -
 Comment ajouter des lignes à un complot dans r
Comment ajouter des lignes à un complot dans r -
 Comment créer un graphique à barres en utilisant ggplot2 dans r
Comment créer un graphique à barres en utilisant ggplot2 dans r -
 Comment définir le mode d'affichage de données dans r
Comment définir le mode d'affichage de données dans r - Comment définir les données à utiliser dans une couche de ggplot2 dans r
UN ggplot2 geom raconte l'intrigue comment vous voulez afficher vos données dans R. Par exemple, vous utilisez geom_bar () pour faire un graphique à barres. Dans ggplot2, vous pouvez utiliser une variété de geoms prédéfinies visant à rendre…
Car ggplot2 ne fait pas partie de la distribution standard de R, vous devez télécharger le package à partir CRAN et l'installer.Le Comprehensive R Archive Network (CRAN) est un réseau de serveurs à travers le monde qui contiennent le code…
Si vous avez téléchargé et importé ggplot2 pour une utilisation dans votre installation de R, vous pouvez l'utiliser pour tracer vos données. Pour créer un nuage de points, vous utilisez le geom_point () fonction. Pour créer un graphique en…
Une fois que vous avez dit ggplot () quelles sont les données à utiliser dans la recherche, la prochaine étape est de le dire comment vos données correspond à des éléments visuels de votre parcelle. Cette mise en correspondance entre les…
Une fois les données, la cartographie, et geoms, le quatrième élément d'un ggplot2 couche en R décrit comment les données doivent être résumées. Dans ggplot2, vous vous référez à ce résumé statistique comme un stat.Une caractéristique…
Le concept de base d'un ggplot2 graphique dans R est que vous combinez différents éléments en couches. Chaque couche d'un ggplot2 graphique contient des informations sur les éléments suivants:Les données que vous voulez tracer: Pour ggplot (),…
Dans ggplot2 en R, échelles contrôlent la façon vos données mappé à votre geom. De cette façon, vos données est mappé à quelque chose que vous pouvez voir (par exemple, les lignes, les points, les couleurs, la position ou formes).La…
La modélisation de régression est le processus de trouver une fonction qui correspond approximativement à la relation entre les deux variables en deux listes de données. Pour calculer un modèle de régression pour vos données à deux variables…
Qu'est-ce que vous utilisez pour entrer des données statistiques dans la calculatrice TI-83 Plus est l'éditeur de liste STAT - relativement grande feuille de calcul qui peut accueillir jusqu'à 20 colonnes (listes de données). Et chaque liste de…
Sauvegarde de vos listes de données sur la calculatrice TI-83 Plus est la première étape dans le sens de les appeler à nouveau lorsque vous souhaitez utiliser ou de les modifier. La liste suivante vous montre comment faire:Sauvegarder les listes…
Qu'est-ce que vous utilisez pour entrer des données statistiques dans la calculatrice TI-84 Plus est l'éditeur de liste STAT - relativement grande feuille de calcul qui peut accueillir jusqu'à 20 colonnes (listes de données). Et chaque liste de…
La modélisation de régression est le processus de trouver une fonction qui correspond approximativement à la relation entre les deux variables en deux listes de données. Le tableau montre les types de modèles de régression de la calculatrice…
Supposons que vous avez utilisé un ensemble de données sur la TI-Nspire pour créer un nuage de points et d'effectuer une régression. Peut-être que vous voulez construire un deuxième nuage de points et de régression associé sur la TI-Nspire.…
Une variété de variables (26 en tout) sont stockées par TI-Nspire après une régression. Pour afficher cette liste, ajouter une page Calculatrice et appuyez sur [VAR]. En utilisant letouches, vous pouvez faire défiler cette liste et coller une…