Courir workflows oozie dans Hadoop
Avant d'exécuter vos flux de oozie, toutes ses composantes doivent exister au sein d'une structure de répertoire spécifié. Plus précisément, le flux de travail lui-même devrait avoir son propre répertoire dédié, où workflow.xml est dans le répertoire racine, et les bibliothèques de code existe dans le sous-répertoire nommé lib. Le répertoire de flux de travail et tous ses fichiers doivent exister dans HDFS pour qu'il soit exécuté.
Si vous utilisez l'interface de ligne de commande oozie de travailler avec divers emplois, veillez à définir la variable d'environnement de OOZIE_URL. (Cela se fait facilement à partir d'une ligne de commande dans un terminal Linux.) Vous pouvez vous épargner beaucoup de dactylographie parce que l'URL du serveur oozie sera maintenant automatiquement inclus avec vos demandes.
Voici un exemple de commande, on pourrait utiliser pour définir la variable à partir de la ligne de commande de l'environnement de OOZIE_URL:
l'exportation OOZIE_URL = "http: // localhost: 8080 / oozie"
Pour exécuter une charge de travail de oozie partir de l'interface de ligne de commande oozie, exécutez une commande comme celle-ci, tout en assurant que le fichier est job.properties accessible localement - qui signifie que le compte que vous utilisez peut le voir, ce qui signifie qu'il doit être sur le même système où tu fuis oozie commandes:
$ Job de oozie -config sampleWorkload / job.properties -run
Après vous soumettez un travail, la charge de travail est stocké dans la base de données objet oozie.
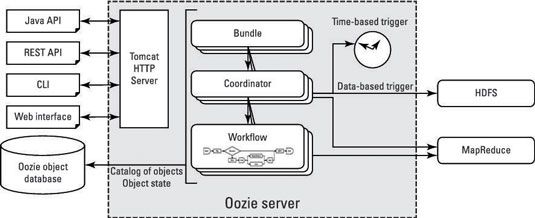
Lors de la présentation, oozie retourne un identifiant pour vous permettre de surveiller et d'administrer votre flux de travail - emploi: 0000001-00000001234567-oozie-W, par exemple.
Pour vérifier l'état de ce travail, vous souhaitez exécuter la commande
travail de oozie -info 0000001-00000001234567-oozie-W



Si vous êtes à l'aise de travailler avec VM et Linux, vous pouvez installer Bigtop sur un autre VM que ce qui est recommandé. Si vous êtes vraiment audacieux et avoir le matériel, allez-y et essayez d'installer Bigtop sur un cluster de machines…
Hadoop est plus que MapReduce et HDFS (Distributed File System Hadoop): Il est également une famille de projets connexes (un écosystème, vraiment) pour le calcul distribué et le traitement de données à grande échelle. La plupart (mais pas…
Comme vous examinez les éléments de Apache Hive montrées, vous pouvez voir au bas cette ruche se trouve au sommet du système Hadoop Distributed File (HDFS) et les systèmes de MapReduce.Dans le cas de MapReduce, les figureshows deux composants…
Si vous travaillez dans le terminal sur votre Mac, vous devez connaître les commandes UNIX le plus important: ceux qui travaillent avec des répertoires, ceux qui travaillent avec des fichiers et des commandes diverses, mais couramment…
Open-source Linux est une alternative populaire à Microsoft Windows, et si vous choisissez d'utiliser cette faible coût ou système d'exploitation libre, vous devez savoir certaines commandes Linux de base pour rendre votre système en douceur.…
bash Linux a plus de 50 commandes intégrées, y compris les commandes les plus courantes telles que CD et pwd, ainsi que de nombreux autres qui sont rarement utilisés. Vous pouvez utiliser ces commandes intégrées dans toute bash script ou à…
L'examen de certification Linux + CompTIA couvre le sujet de GNU et commandes Unix. Le tableau montre les sous-thèmes, les poids, les descriptions et les principaux domaines de connaissances pour ce sujet.Breakout de domaine…
Le Linux faire utilitaire fonctionne par la lecture et l'interprétation d'une makefile. Typiquement, vous exécutez faire en tapant simplement la commande suivante à l'invite du shell:faireLorsqu'il est exécuté de cette manière, GNU faire…
Vous pouvez utiliser les fonctionnalités de bash lors de l'écriture des programmes Linux appelé scripts shell - collections de commandes shell stockées dans un fichier tâche orientée. Vous définissez des variables dans bash tout comme vous…
L'examen Essentials Linux couvre le sujet de l'utilisation de la ligne de commande pour obtenir de l'aide. Le tableau montre les sous-thèmes, le poids, la description et principaux domaines de connaissances pour ce sujet.Breakout de…
Avec juste un peu de travail, vous pouvez configurer une archive de sorte qu'un programme Java peut être exécuté directement. Tout ce que vous avez à faire est de créer un fichier manifeste avant de créer l'archive. Ensuite, lorsque vous…
Malheureusement, vous ne pouvez pas exécuter des programmes de ervlet Javas sur toute vieil ordinateur. Tout d'abord, vous devez installer un programme spécial appelé moteur de servlet pour transformer votre ordinateur en un serveur qui est…
Par défaut, R conserve la trace de toutes les commandes que vous utilisez dans une session. Ce suivi peut être utile si vous avez besoin de réutiliser une commande que vous avez utilisé plus tôt ou si vous voulez garder une trace du travail que…
Vous pouvez rejoindre les commandes Linux ensemble pour faire vos propres scripts pour votre Raspberry Pi. Vous pouvez le faire pour deux raisons. On est si vous avez une longue commande d'une ligne avec beaucoup de commutateurs que vous tapez…