L'écosystème Hadoop Apache
Hadoop est plus que MapReduce et HDFS (Distributed File System Hadoop): Il est également une famille de projets connexes (un écosystème, vraiment) pour le calcul distribué et le traitement de données à grande échelle. La plupart (mais pas tous) de ces projets sont hébergés par l'Apache Software Foundation. Le tableau répertorie certains de ces projets.
| nom du projet | Description |
|---|---|
| Ambari | Un ensemble intégré d'outils d'administration Hadoop forinstalling, le suivi et le maintien d'un cluster Hadoop. Alsoincluded sont des outils pour ajouter ou supprimer des nœuds esclaves. |
| Avro | Un cadre pour la sérialisation efficace (un oftransformation nature) des données dans un format binaire compact |
| Flume | Un service de flux de données pour le déplacement de volumes importants de LogData dans Hadoop |
| HBase | Une base de données de colonne distribué qui utilise HDFS pour itsunderlying stockage. Avec HBase, vous pouvez stocker des données dans des tableaux extremelylarge avec des structures de colonnes variables. |
| HCatalog | Un service pour fournir une vue relationnel de données stockées inHadoop, y compris une approche standard pour les données tabulaires |
| Hive | Un entrepôt de données distribuée pour les données qui sont stockées dans HDFS-fournit également un langage de requête qui est basé sur SQL (HiveQL) |
| Teinte | Une interface d'administration Hadoop avec des outils de l'interface graphique pratiques forbrowsing fichiers, émission de requêtes Hive et Pig, et le développement de Oozieworkflows |
| Cornac | Une bibliothèque de l'apprentissage machine algorithmes statistiques qui wereimplemented dans MapReduce et peut fonctionner en mode natif sur Hadoop |
| Oozie | Un outil de gestion de flux de travail qui peut gérer l'ordonnancement andchaining ensemble des applications Hadoop |
| Cochon | Une plate-forme pour l'analyse de très grands ensembles de données qui runson HDFS et avec une couche de l'infrastructure constituée d'un compilerthat produit des séquences de programmes MapReduce et un layerconsisting de langue de la langue de requête nommée Pig Latin |
| Sqoop | Un outil pour déplacer efficacement de grandes quantités de bases de données et de betweenrelational HDFS |
| ZooKeeper | Une interface simple pour la coordination centralisée des services (tels que nommage, la configuration et la synchronisation) utilisé applications bydistributed |
L'écosystème Hadoop et ses distributions commerciales continuent d'évoluer, avec les technologies et les outils nouveaux ou améliorés émergents tout le temps.
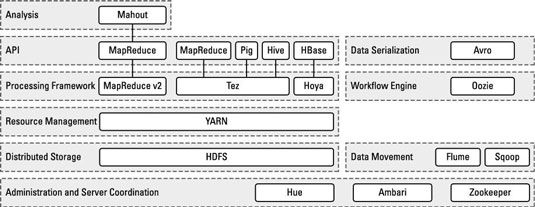
La figure montre les divers projets de l'écosystème Hadoop et comment ils se rapportent à un autre:

La solution à l'expansion des grappes Hadoop indéfiniment est de fédérer l'NameNode. Avant Hadoop 2 est entré en scène, les clusters Hadoop ont dû vivre avec le fait que NameNode placé des limites à la mesure dans laquelle ils pourraient…
Sqoop (SQL-à-Hadoop) est un outil grand de données qui offre la possibilité d'extraire des données à partir des données magasins non Hadoop, transformer les données en une forme utilisable par Hadoop, puis charger les données dans HDFS. Ce…
Hadoop est conçu pour être déployé sur une grande grappe d'ordinateurs en réseau, avec des nœuds maîtres (qui accueillent les services qui contrôlent le stockage et le traitement de Hadoop) et nœuds esclaves (où les données sont stockées…
IBM a une longue histoire de collaboration avec SQL et de la technologie de base de données. En accord avec cette histoire, la solution d'IBM pour SQL sur Hadoop exploite des composants de ses technologies de base de données relationnelles qui…
Avant vous pouvez exécuter votre premier script de cochon dans Hadoop, vous devez avoir une poignée sur la façon dont les programmes de porc peuvent être fournis avec le serveur de porc.Pig dispose de deux modes pour l'exécution de scripts:Mode…
Hadoop, un framework logiciel open-source, utilise HDFS (le système de fichiers distribués Hadoop) et MapReduce pour analyser les données de grandes sur des groupes de produits de base sur le matériel qui est, dans un environnement de calcul…
Pour permettre une meilleure compréhension des alternatives SQL-sur-Hadoop Hive, il pourrait être utile d'examiner une amorce sur le traitement massivement parallèle (MPP) des bases de données en premier.Apache Hive est posée sur le dessus du…
Pig latin est la langue pour les programmes de porc. Pig traduit le script Pig Latin en emplois MapReduce qu'il peut être exécuté dans clusters Hadoop. En venant avec Pig Latin, l'équipe de développement a suivi trois principes clés de la…
En 2010, EMC et VMware, les leaders du marché dans la prestation de l'informatique comme un service via le cloud computing, acquis Greenplum Corporation, les gens qui avaient obtenu gain de cause le produit MPP Greenplum Data Warehouse (DW) sur le…
Parce que de nombreux déploiements Hadoop existants ne sont toujours pas encore à l'aide de Yet Another négociateur des ressources (FIL), de prendre un coup d'oeil à la façon dont Hadoop a réussi son traitement de données avant les jours de…
Il ya des raisons impérieuses que SQL a su résister. L'industrie des TI a eu 40 ans d'expérience avec SQL, car il a d'abord été développé par IBM au début des années 1970. Avec l'augmentation de l'adoption de bases de données…
Lorsque l'on considère les capacités de Hadoop pour travailler avec des données structurées (ou de travailler avec des données de tout type, d'ailleurs), rappelez-vous les caractéristiques de base de Hadoop: Hadoop est, d'abord et avant tout,…
L'organisation des services de données et des outils, couche 3 de la grosse pile de données, la capture, valider et assembler différents éléments de données dans de grandes collections contextuellement pertinents. Parce que Big Data est…
Hive est, une couche d'entreposage des données orientée lots construit sur les éléments de base de Hadoop (HDFS et MapReduce) et est très utile dans les grandes données. Il fournit aux utilisateurs qui connaissent SQL avec une mise en œuvre…