Ibm grande sql et Hadoop
IBM a une longue histoire de collaboration avec SQL et de la technologie de base de données. En accord avec cette histoire, la solution d'IBM pour SQL sur Hadoop exploite des composants de ses technologies de base de données relationnelles qui sont portés pour fonctionner sur Hadoop.
Si vous êtes tous familiers avec le nommage produit d'IBM pour ses produits Big Data et de fonctionnalités, vous pouvez facilement deviner ce qu'ils ont appelé leur SQL sur la solution Hadoop: Big SQL. Le but de Big SQL est de fournir une interface SQL sur Hadoop qui donne aux utilisateurs autant que possible de ce qu'ils sont habitués à des interfaces SQL pour les bases de données relationnelles.
Cela signifie un large soutien de la syntaxe de requête, une performance rapide qui ne nécessite pas que les utilisateurs ayant au singe avec leurs requêtes, et la capacité de contrôler la sécurité des données.
La figure montre un déploiement partiel des BigInsights, la distribution de Hadoop IBM exécutant Big SQL.
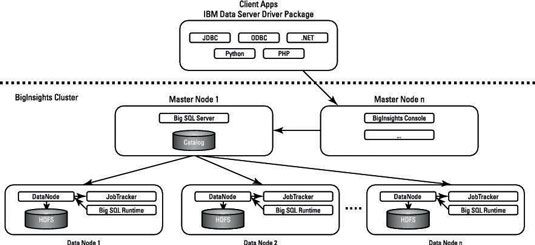
Ici, vous pouvez voir un sous-ensemble des nœuds maîtres et des noeuds de données derrière le pare-feu BigInsights. Un des noeuds de maître fonctionne le serveur SQL Big, qui comprend le compilateur et un optimiseur de SQL d'IBM. Sont également inclus sur ce nœud maître est un catalogue, où les métadonnées et des statistiques sur les données cataloguées dans HDFS sont stockées pour une utilisation par le compilateur / optimiseur.
Les paragraphes de requêtes sont envoyées aux noeuds de données applicables lorsque les données requises sont stockées, et il le Big SQL Runtime (qui est l'exécution de SQL IBM) exécute la charge de travail. Plutôt que de courir mappeur et procédés réducteurs et persister des fichiers avec des jeux de résultats intermédiaires, Big SQL utilise fonctionnant en continu démons qui passent des messages entre eux.
Il est important de noter que les données interrogées sont stockées et gérées par Hadoop. Big SQL supporte les formats de fichiers Hadoop standards - par exemple, rcfile et parquet.
Big SQL fournit la même vaste support de SQL que les produits de base de données relationnelle IBM - par exemple, la norme ANSI SQL-2011, et la compatibilité pour SQL Procedural Language d'IBM (SQL / PL). (Au moment de l'écriture, IBM a travaillé à fournir un soutien pour le dialecte SQL d'Oracle et de leur langage procédural PL / SQL.)
Avec le moteur standard SQL IBM parcouru un certain nombre d'autres capacités, notamment IBM row- et de la sécurité basée sur les colonnes (aussi connu comme grains fins de contrôle d'accès, ou FGAC), où seuls des utilisateurs spécifiques peuvent être autorisés à voir certains ensembles de des lignes de données ou colonnes.
Big SQL est livré avec le client IBM Data Server standard, qui comprend un package de pilote. Les applications classiques de base de données peuvent se connecter au cluster Hadoop BigInsights et en toute sécurité échanger des données chiffrées sur SSL.


Une multitude d'études montrent que la plupart des données dans un entrepôt de données d'entreprise est rarement interrogés. Les fournisseurs de base de données ont répondu à ces observations en mettant en œuvre leurs propres méthodes pour…
Le coût peu onéreux de stockage pour Hadoop plus la possibilité d'interroger les données Hadoop Hadoop avec SQL rend la destination de choix pour les données d'archives. Ce cas d'utilisation a un faible impact sur votre organisation parce que…
La solution à l'expansion des grappes Hadoop indéfiniment est de fédérer l'NameNode. Avant Hadoop 2 est entré en scène, les clusters Hadoop ont dû vivre avec le fait que NameNode placé des limites à la mesure dans laquelle ils pourraient…
Sqoop (SQL-à-Hadoop) est un outil grand de données qui offre la possibilité d'extraire des données à partir des données magasins non Hadoop, transformer les données en une forme utilisable par Hadoop, puis charger les données dans HDFS. Ce…
Hadoop est conçu pour être déployé sur une grande grappe d'ordinateurs en réseau, avec des nœuds maîtres (qui accueillent les services qui contrôlent le stockage et le traitement de Hadoop) et nœuds esclaves (où les données sont stockées…
La planification des tâches et de suivi pour les grandes données sont des parties intégrantes de Hadoop MapReduce et peuvent être utilisés pour gérer les ressources et les applications. Les premières versions de Hadoop faveur d'un système de…
Hadoop, un framework logiciel open-source, utilise HDFS (le système de fichiers distribués Hadoop) et MapReduce pour analyser les données de grandes sur des groupes de produits de base sur le matériel qui est, dans un environnement de calcul…
Pour permettre une meilleure compréhension des alternatives SQL-sur-Hadoop Hive, il pourrait être utile d'examiner une amorce sur le traitement massivement parallèle (MPP) des bases de données en premier.Apache Hive est posée sur le dessus du…
En 2010, EMC et VMware, les leaders du marché dans la prestation de l'informatique comme un service via le cloud computing, acquis Greenplum Corporation, les gens qui avaient obtenu gain de cause le produit MPP Greenplum Data Warehouse (DW) sur le…
Parce que de nombreux déploiements Hadoop existants ne sont toujours pas encore à l'aide de Yet Another négociateur des ressources (FIL), de prendre un coup d'oeil à la façon dont Hadoop a réussi son traitement de données avant les jours de…
Il ya des raisons impérieuses que SQL a su résister. L'industrie des TI a eu 40 ans d'expérience avec SQL, car il a d'abord été développé par IBM au début des années 1970. Avec l'augmentation de l'adoption de bases de données…
Lorsque l'on considère les capacités de Hadoop pour travailler avec des données structurées (ou de travailler avec des données de tout type, d'ailleurs), rappelez-vous les caractéristiques de base de Hadoop: Hadoop est, d'abord et avant tout,…
Hadoop est plus que MapReduce et HDFS (Distributed File System Hadoop): Il est également une famille de projets connexes (un écosystème, vraiment) pour le calcul distribué et le traitement de données à grande échelle. La plupart (mais pas…
Hive est, une couche d'entreposage des données orientée lots construit sur les éléments de base de Hadoop (HDFS et MapReduce) et est très utile dans les grandes données. Il fournit aux utilisateurs qui connaissent SQL avec une mise en œuvre…