Modes locaux et distribués de l'exécution de scripts de porcs dans Hadoop
Avant vous pouvez exécuter votre premier script de cochon dans Hadoop, vous devez avoir une poignée sur la façon dont les programmes de porc peuvent être fournis avec le serveur de porc.
Pig dispose de deux modes pour l'exécution de scripts:
Mode local: Tous les scripts sont exécutés sur une seule machine sans nécessiter Hadoop MapReduce et HDFS. Cela peut être utile pour développer et tester la logique de porc. Si vous utilisez un petit ensemble de données au développeur ou tester votre code, puis mode local pourrait être plus rapide que de passer par l'infrastructure de MapReduce.
Mode local ne nécessite pas de Hadoop. Lorsque vous exécutez en mode local, le programme Pig exécute dans le contexte d'une machine virtuelle Java locale, et l'accès aux données se fait via le système de fichiers local d'une seule machine. Le mode local est en fait une simulation locale de MapReduce dans la classe de LocalJobRunner de Hadoop.
Mode MapReduce (également appelé mode Hadoop): Pig est exécuté sur le cluster Hadoop. Dans ce cas, le script de porc est converti en une série d'emplois MapReduce qui sont ensuite exécutés sur le cluster Hadoop.
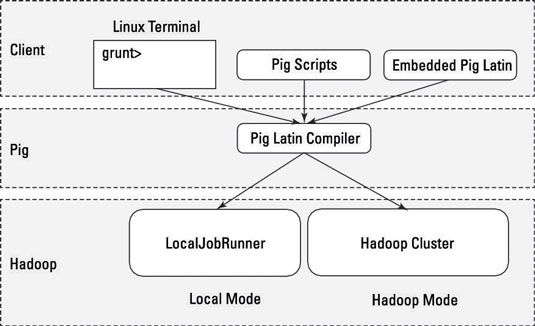
Si vous avez un téraoctet de données que vous souhaitez effectuer des opérations sur et vous souhaitez développer un programme interactif, vous pourrez bientôt trouver des choses ralentir considérablement, et vous pouvez commencer à la croissance de votre stockage. Mode local vous permet de travailler avec un sous-ensemble de vos données d'une manière plus interactive afin que vous puissiez comprendre la logique (et de travailler sur les bugs) de votre programme de porc.
Après vous avez des choses mises en place comme vous le souhaitez et vos opérations sont bien rodés, vous pouvez exécuter le script sur l'ensemble de l'utilisation du mode de MapReduce données complètes.

 fédération")
Hadoop est conçu pour être déployé sur une grande grappe d'ordinateurs en réseau, avec des nœuds maîtres (qui accueillent les services qui contrôlent le stockage et le traitement de Hadoop) et nœuds esclaves (où les données sont stockées…
Il n'y a pas de meilleure façon de voir ce qui est ce que l'installation du logiciel ruche et lui donner un essai. Comme avec d'autres technologies dans l'écosystème Hadoop, il ne faut pas longtemps pour commencer.Si vous avez le temps et la…
La façon HDFS a été mis en place, il se décompose très gros fichiers dans de grands blocs (par exemple, mesure 128 Mo), et stocke trois exemplaires de ces blocs sur les différents nœuds du cluster. HDFS n'a pas connaissance du contenu de ces…
La planification des tâches et de suivi pour les grandes données sont des parties intégrantes de Hadoop MapReduce et peuvent être utilisés pour gérer les ressources et les applications. Les premières versions de Hadoop faveur d'un système de…
Hadoop, un framework logiciel open-source, utilise HDFS (le système de fichiers distribués Hadoop) et MapReduce pour analyser les données de grandes sur des groupes de produits de base sur le matériel qui est, dans un environnement de calcul…
Pour permettre une meilleure compréhension des alternatives SQL-sur-Hadoop Hive, il pourrait être utile d'examiner une amorce sur le traitement massivement parallèle (MPP) des bases de données en premier.Apache Hive est posée sur le dessus du…
Pig latin est la langue pour les programmes de porc. Pig traduit le script Pig Latin en emplois MapReduce qu'il peut être exécuté dans clusters Hadoop. En venant avec Pig Latin, l'équipe de développement a suivi trois principes clés de la…
Le langage de programmation Pig est conçu pour gérer tout type de données jeté son chemin - structurée, semi-structurée, les données non structurées, you name it. Programmes de porcs peuvent être emballés de trois manières…
Parce que de nombreux déploiements Hadoop existants ne sont toujours pas encore à l'aide de Yet Another négociateur des ressources (FIL), de prendre un coup d'oeil à la façon dont Hadoop a réussi son traitement de données avant les jours de…
Conversion de modèles statistiques pour fonctionner en parallèle est une tâche difficile. Dans le paradigme traditionnel pour la programmation parallèle, accès à la mémoire est régulée par l'utilisation de les discussions - les…
Hadoop est un écosystème riche et évolue rapidement avec un ensemble croissant de nouvelles applications. Plutôt que d'essayer de faire face à toutes les exigences de nouvelles capacités, de porc est conçu pour être extensible via fonctions…
Hadoop est plus que MapReduce et HDFS (Distributed File System Hadoop): Il est également une famille de projets connexes (un écosystème, vraiment) pour le calcul distribué et le traitement de données à grande échelle. La plupart (mais pas…
Comme vous examinez les éléments de Apache Hive montrées, vous pouvez voir au bas cette ruche se trouve au sommet du système Hadoop Distributed File (HDFS) et les systèmes de MapReduce.Dans le cas de MapReduce, les figureshows deux composants…
Après le cluster Hadoop est installé et fonctionne, vous pouvez exécuter votre premier programme de Hadoop. Cette application est très simple, et calcule le total des miles parcourus pour tous les vols effectués en un an. L'année est définie…