Comment utiliser MapReduce pour Big Data
MapReduce est un cadre logiciel qui est idéal pour les grandes données, car il permet aux développeurs d'écrire des programmes qui peuvent traiter des quantités massives de données non structurées en parallèle sur un groupe distribué de processeurs.
Sommaire
La fonction de la carte pour Big Data
La carte fonction a été une partie de nombreux langages de programmation fonctionnels pendant des années. Plan a été rénovée en tant que technologie de base pour les listes de traitement des éléments de données.
Les opérateurs dans les langages fonctionnels ne modifient pas la structure de la de données qu'ils créent de nouvelles structures de données que leur production. Les données d'origine lui-même est non modifiée ainsi. Ainsi, vous pouvez utiliser la fonction de carte en toute impunité parce qu'il ne nuira pas à vos données stockées précieux.
Un autre avantage de la programmation fonctionnelle est de ne pas avoir à gérer expressément le mouvement ou le débit des données. Ceci dégage le programmateur à partir de la gestion explicite de la sortie de données et de placement. Enfin, l'ordre des opérations sur les données ne sont pas prescrits.
Une façon d'accomplir la solution est d'identifier les données d'entrée et de créer une liste:
mylist = ("tous les comtés des États-Unis qui ont participé à la plus récente élection générale»)Créer la fonction combien de gens en utilisant la fonction de carte. Cette sélectionne uniquement les comtés avec plus de 50.000 personnes:
carte howManyPeople (myList) = [howManyPeople «comté 1" - howManyPeople «comté 2" - howManyPeople «comté 3" - howManyPeople «comté 4" -. . . ]
Maintenant produire une nouvelle liste de sortie de tous les comtés ayant une population supérieure à 50 000:
(non, comté 1- Oui, comté 2- non, comté 3- Oui, comté 4-?, comté NNN)
La fonction exécute sans apporter de modifications à la liste originale. En outre, vous pouvez voir ce que chaque élément de la liste de sortie correspond à un élément correspondant de la liste d'entrée, avec un Oui ou non ci-jointe. Si le comté a satisfait à l'exigence de plus de 50.000 personnes, la fonction de carte identifie avec un Oui. Dans le cas contraire, un non est indiqué.
Ajoutez la fonction de réduire pour les Big Data
Comme la fonction de la carte, réduire a été une caractéristique des langages de programmation fonctionnels pendant de nombreuses années. La fonction de réduire prend la sortie d'une fonction de carte et “ réduit ” la liste de quelque façon le programmeur désire.
La première étape que la fonction exige de réduire consiste à placer une valeur dans ce qu'on appelle un accumulateur, qui détient une valeur initiale. Après le stockage d'une valeur de départ dans l'accumulateur, la fonction réduire traite ensuite chaque élément de la liste et effectue l'opération dont vous avez besoin dans la liste.
À la fin de la liste, la fonction de réduire retourne une valeur basée sur l'opération que vous vouliez effectuer sur la liste de sortie.
Supposons que vous devez identifier les comtés où la majorité des voix étaient pour le candidat démocrate. Rappelez-vous que votre combien de gens fonction de la carte regardé chaque élément de la liste d'entrée et a créé une liste de sortie des comtés avec plus de 50.000 personnes (Oui) Et les comtés avec moins de 50.000 personnes (non).
Après invoquant le combien de gens fonction de la carte, on se retrouve avec la liste de sortie suivante:
(non, comté 1- Oui, comté 2- non, comté 3- Oui, comté 4-?, comté NNN)
Ceci est maintenant l'entrée pour votre fonction réduire. Voici à quoi il ressemble:
countylist = (non, comté 1- Oui, comté 2- non, comté 3- Oui, comté 4-?, comté NNN) réduire isDemocrat (countylist)
Le réduire les processus de la fonction de chaque élément de la liste et retourne une liste de tous les comtés ayant une population supérieure à 50 000, où la majorité a voté démocrate.
Mettre la carte grand de données et de réduire ensemble
Parfois, la production d'une liste de sortie est juste assez. De même, effectuant parfois des opérations sur chaque élément d'une liste est assez. Le plus souvent, vous voulez regarder à travers de grandes quantités de données d'entrée, sélectionner certains éléments des données, puis calculer quelque chose de valeur à partir des éléments pertinents de données.
Vous ne voulez pas changer cette liste d'entrée de sorte que vous pouvez l'utiliser de différentes manières avec de nouvelles hypothèses et de nouvelles données.
Applications de conception des développeurs de logiciels basés sur des algorithmes. Un algorithme est rien de plus qu'une série de mesures qui doivent se produire dans le service à un objectif global. Il peut sembler un peu comme ceci:
Commencez avec un grand nombre ou des données ou des dossiers.
Itérer sur les données.
Utilisez la fonction de la carte pour en extraire quelque chose d'intéressant et de créer une liste de sortie.
Organiser la liste de sortie pour optimiser pour un traitement ultérieur.
Utilisez la fonction de réduire de calculer un ensemble de résultats.
Produire la sortie finale.
Les programmeurs peuvent mettre en œuvre toutes sortes d'applications utilisant cette approche, mais les exemples à ce point ont été très simple, de sorte que la valeur réelle de MapReduce peuvent ne pas être apparents. Qu'est-ce qui arrive quand vous avez de très grandes données d'entrée? Pouvez-vous utiliser le même algorithme sur des téraoctets de données? Les bonnes nouvelles est oui.
Toutes les opérations semblent indépendante. Cela est parce qu'ils sont. La vraie puissance de MapReduce est la capacité de diviser pour régner. Prenez un très grand problème et le casser en petits morceaux, plus faciles à gérer, opérer sur chaque bloc indépendamment, puis tirer tous ensemble à la fin. En outre, la fonction de la carte est commutative - en d'autres termes, l'ordre dans lequel une fonction est exécutée n'a pas d'importance.
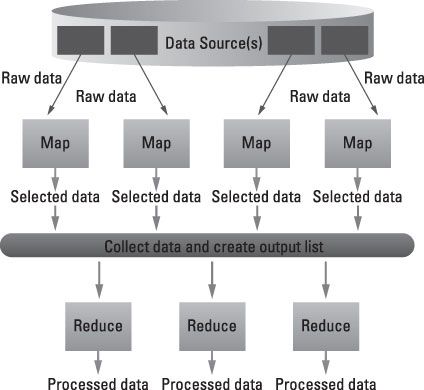
Donc MapReduce peut effectuer son travail sur des machines différentes dans un réseau. Il peut également tirer de multiples sources de données, internes ou externes. MapReduce garde la trace de son travail en créant une clé unique pour assurer que tout le traitement est liée à résoudre le même problème. Cette touche est également utilisée pour tirer toutes les sorties ensemble à la fin de toutes les tâches distribuées.




L'API MapReduce est écrit en Java, donc applications MapReduce sont basées sur Java principalement. La liste suivante indique les composants d'une application de MapReduce que vous pouvez développer:Driver (obligatoire): Ceci est la coquille de…
Hadoop, un framework logiciel open-source, utilise HDFS (le système de fichiers distribués Hadoop) et MapReduce pour analyser les données de grandes sur des groupes de produits de base sur le matériel qui est, dans un environnement de calcul…
Un algorithme complexe utilisé pour l'analyse prédictive, le réseau neuronal, est biologiquement inspiré par la structure du cerveau humain. Un réseau de neurones fournit un modèle très simple en comparaison au cerveau humain, mais il…
Hadoop est une plate-forme de logiciel libre, open-source pour l'écriture et l'exécution d'applications qui traitent une grande quantité de données pour l'analyse prédictive. Il permet un traitement parallèle distribué de grands ensembles de…
Un outil open-source qui est uniquement utile dans l'analyse prédictive est Apache Mahout. Cette bibliothèque d'apprentissage comprend des versions à grande échelle de la classification, la classification, filtrage collaboratif, et d'autres…
MapReduce est de plus en plus utile pour les gros volumes de données. Au début des années 2000, certains ingénieurs de Google sont penchés sur l'avenir et a déterminé que pendant que leurs solutions actuelles pour des applications telles que…
Quand les gens parlent de la carte et de réduire dans les grandes données, ils le font à titre d'activités au sein d'un modèle de programmation fonctionnelle. La programmation fonctionnelle est l'une des deux manières que les développeurs de…
L'organisation des services de données et des outils, couche 3 de la grosse pile de données, la capture, valider et assembler différents éléments de données dans de grandes collections contextuellement pertinents. Parce que Big Data est…
Les listes chaînées peuvent être très utiles, pour un certain nombre de raisons - mais ils prennent un certain temps pour envelopper votre esprit autour de la notion. Ce qui est pire? La liste doublement liée.Plutôt que de simplement créer un…
Tampons temporaires sont utiles pour toutes sortes de tâches. Normalement, vous les utilisez lorsque vous souhaitez conserver les données originales, mais vous avez besoin de manipuler les données d'une certaine façon. Par exemple, la création…
Chaque fonction dans R attend vos données soient dans un format spécifique. Cela ne signifie pas simplement de savoir si il est un entier, caractère, ou un facteur, mais aussi si vous fournissez un vecteur, une matrice, une trame de données, ou…
R dispose d'une suite puissante de fonctions qui vous permet d'appliquer une fonction de façon répétée sur les éléments d'une liste. La chose intéressante et cruciale à ce sujet est que cela se passe sans une boucle explicite.Parce que cela…
Vous pourriez avoir à faire un problème sur l'examen de licence de l'immobilier en utilisant les taux de péréquation, parfois appelé facteurs de péréquation, de comprendre un impôt foncier de comté (par opposition à une ville, ou le…
Si vous prévoyez d'élever des poulets, vous devez trouver un bon vétérinaire qui traite de la volaille. Ne pas attendre un oiseau tombe malade. Savoir où aller avant une situation d'urgence dans votre flocages vous économiserez un temps…