Régions en HBase
RegionServers sont une chose, mais il faut aussi jeter un oeil à la façon dont les différentes régions travaillent. Dans HBase, une table est à la fois la propagation à travers un certain nombre de RegionServers ainsi comme étant composé des différentes régions. Comme les tableaux sont divisés, les divisions deviennent régions. Régions stockent une gamme de paires clé-valeur, et chaque RegionServer gère un nombre configurable de régions.
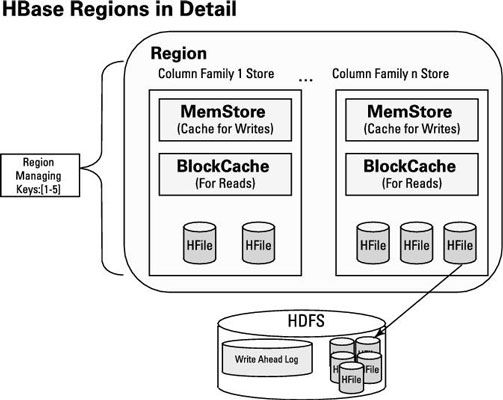
Mais qu'est-ce que les régions individuelles ressemblent? HBase est un magasin de données orientée colonne-famille, alors comment les différentes régions stocker des paires clé-valeur sur la base des familles de poteaux auxquels ils appartiennent? La figure suivante commence à répondre à ces questions et vous aide à digérer des informations plus vitales sur l'architecture de HBase.
HBase est écrit en Java - comme la grande majorité des technologies Hadoop. Java est un langage de programmation orienté objet et une technologie élégante pour le calcul distribué. Donc, comme vous continuez à en savoir plus sur HBase, rappelez-vous que tous les composants de l'architecture sont finalement des objets Java.
Tout d'abord, la figure précédente donne une assez bonne idée de ce que la région objets ressemblent vraiment, de façon générale. Il précise également que les régions de données distinctes en familles colonnes et stockent les données dans le HDFS utilisant des objets HFILE.
Lorsque les clients mettent paires clé-valeur dans le système, les clés sont traitées de sorte que les données sont stockées sur la base de la famille de la colonne paire appartient. Comme le montre la figure, chaque objet de banque de la famille de la colonne dispose d'un cache de lecture appelé le BlockCache et un cache d'écriture appelé le MemStore. Le BlockCache aide avec des performances de lecture aléatoire.
Les données sont lues dans les blocs de la HDFS et stocké dans le BlockCache. Les lectures ultérieures pour les données - ou des données stockées à proximité - sera lue à partir du disque RAM à la place, l'amélioration de la performance globale. The Write Ahead Log (WAL, pour faire court) garantit que vos écritures Hbase sont fiables. Il est l'un WAL par RegionServer.

Respectez toujours la loi de fer de l'informatique distribuée: Un échec ne fait pas exception - il est la norme, surtout quand le regroupement des centaines voire des milliers de serveurs. Google a suivi la loi de fer dans la conception et BigTable HBase emboîté le pas.
Lorsque vous écrivez ou modifier des données dans HBase, les données sont d'abord persisté à l'WAL, qui est stocké dans le HDFS, puis les données sont écrites dans le cache MemStore. A intervalles configurables, paires clé-valeur stockées dans la MemStore sont écrites HFiles dans le HDFS et ensuite entrées WAL sont effacés.
Si une panne survient après l'écriture initiale WAL mais avant l'MemStore finale écriture sur le disque, l'WAL peut être rejoué pour éviter toute perte de données.
Trois objets HFILE sont dans une famille de la colonne et deux dans l'autre. La conception de HBase est de vider les données de la famille colonnes stockés dans le MemStore une HFILE par chasse. Puis, à intervalles configurables HFiles sont combinés en grandes HFiles. Cette stratégie met en attente l'opération de compactage critique dans HBase.


Toute installation HBase grave nécessite une configuration standard sur votre cluster et sur les nœuds individuels. Quelques exemples sont fournis ici. Prenez d'abord un regard sur la surveillance et la gestion.Outils de surveiller votre clusterSi…
Sqoop peut être utilisé pour transformer un schéma de base de données relationnelle dans un schéma HBase. Bien sûr, l'objectif principal ici est de démontrer comment Sqoop peut importer des données à partir d'un SGBDR ou entrepôt de…
Le modèle de données logique HBase est simple mais élégant, et il fournit un mécanisme de stockage de données pour organiser toutes sortes de données - de grands ensembles de données non structurées en particulier. Toutes les parties du…
RegionServers sont les processus logiciels (souvent appelés démons) vous activez pour stocker et récupérer des données dans HBase (Base de données Hadoop). Dans les environnements de production, chaque RegionServer est déployé sur son propre…
Hbase magasins de données sont constitués d'une ou plusieurs tables qui sont indexées par les touches de ligne. Les données sont stockées dans des lignes avec des colonnes et rangées peut avoir plusieurs versions. Par défaut, le versioning…
Dans un univers Hadoop, nœuds esclaves sont où les données Hadoop est stockée et où le traitement de données a lieu. Les services suivants permettent nœuds esclaves pour stocker et traiter les données:NodeManager: Coordonne les ressources…
HBase est, une base de données qui utilise HDFS que son magasin de persistance pour les grands projets de données non relationnelles distribuée (de colonne). Elle est calquée sur Google BigTable et est capable d'accueillir de très grandes…
Lorsque l'on considère les capacités de Hadoop pour travailler avec des données structurées (ou de travailler avec des données de tout type, d'ailleurs), rappelez-vous les caractéristiques de base de Hadoop: Hadoop est, d'abord et avant tout,…
Ici, vous trouverez comment télécharger et déployer HBase en mode autonome. Il est incroyablement simple à installer HBase et commencer à utiliser la technologie. Il suffit de garder à l'esprit que HBase est généralement déployée sur un…
Hadoop est plus que MapReduce et HDFS (Distributed File System Hadoop): Il est également une famille de projets connexes (un écosystème, vraiment) pour le calcul distribué et le traitement de données à grande échelle. La plupart (mais pas…
HBase (Base de données Hadoop) est une implémentation Java de BigTable de Google. Google définit comme un BigTable “ clairsemée, distribué, carte triés multidimensionnelle persistante ”. Il est une définition assez concise, mais…
HBase est écrit en Java, un langage élégant pour la construction de technologies distribuées comme HBase, mais le visage il - pas tout le monde qui veut prendre avantage des innovations Hbase est un développeur Java. Voilà pourquoi il ya un…
Démarrage d'une discussion des HBase (Base de données Hadoop) en décrivant l'architecture RegionServers la place de la MasterServer peut vous surprendre. Le terme RegionServer semble impliquer que cela dépend (et est secondaire à)…
Les bases de données en colonnes peuvent être très utiles dans votre grand projet de données. Bases de données relationnelles sont orientée rangée, que les données de chaque ligne d'une table sont stockées ensemble. Dans une forme de…