Comment créer un modèle d'apprentissage sans surveillance avec dbscan
Dbscan (Densité-Basé regroupement spatial des applications avec bruit) est un algorithme de clustering populaire utilisé comme une alternative à K-Means dans l'analyse prédictive. Il ne nécessite pas que vous entrez le nombre de grappes afin d'exécuter. Mais en échange, vous devez régler deux autres paramètres.
Sommaire
La mise en œuvre de scikit-learn fournit une valeur par défaut pour les EPS et les paramètres de min_samples, mais vous attend généralement de régler ceux-ci. Le paramètre eps est la distance maximale entre deux points de données à prendre en considération dans le même quartier. Le paramètre min_samples est le montant minimum de points de données dans un quartier à être considéré comme un cluster.
Un avantage que dbscan a plus de K-means est que dbscan ne se limite pas à un certain nombre de groupes lors de l'initialisation. L'algorithme détermine un certain nombre de grappes sur la base de la densité d'une région.
Gardez à l'esprit, cependant, que l'algorithme dépend des EPS et les paramètres de min_samples de comprendre ce que la densité de chaque groupe devrait être. L'idée est que ces deux paramètres sont beaucoup plus faciles à choisir pour certains problèmes de clustering.
Dans la pratique, vous devriez tester avec plusieurs algorithmes de clustering.
Parce que l'algorithme dbscan a un concept intégré de bruit, il est communément utilisé pour détecter les valeurs aberrantes dans les données - par exemple, une activité frauduleuse des cartes de crédit, e-commerce, ou réclamations d'assurance.
Comment faire pour exécuter l'ensemble de données complet
Vous aurez besoin de charger l'ensemble de données Iris dans votre session Python. Voici la procédure:
Ouvrez une nouvelle session de shell interactif Python.
Utilisez une nouvelle session de Python afin que la mémoire est clair et vous avez une ardoise propre pour travailler avec.
Collez le code suivant dans l'invite et observer la sortie:
>>> From sklearn.datasets importer load_iris >>> iris = load_iris ()
Après l'exécution de ces deux déclarations, vous ne devriez pas voir tous les messages générés par l'interpréteur. Les iris variables doivent contenir toutes les données du fichier de iris.csv.
Créer une instance de dbscan. Tapez le code suivant dans l'interpréteur:
>>> From sklearn.cluster importation dbscan >>> dbscan = dbscan (random_state = 111)
La première ligne de code importe la bibliothèque dbscan dans la session pour vous d'utiliser. La deuxième ligne crée une instance de dbscan avec des valeurs par défaut pour les EPS et min_samples.
Vérifiez les paramètres qui ont été utilisés en tapant le code suivant dans l'interprète:
>>> DbscanDBSCAN (EPS = 0,5, = métriques «euclidienne», min_samples = 5, random_state = 111)
Monter les données Iris dans l'algorithme de clustering dbscan en tapant le code suivant dans l'interprète:
>>> Dbscan.fit (iris.data)
Pour vérifier le résultat, tapez le code suivant dans l'interprète:
>>> Dbscan.labels_array ([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0. , 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., -1., 0., 0., 0., 0., 0., 0., 0., 0., 1, 1. 1. 1. 1. 1. 1., -1, 1, 1, -.... 1, 1., 1., 1. 1. 1. 1. 1. -1., 1., 1., 1. 1. 1. 1. 1. 1. 1. 1., 1 ., 1., 1. 1. 1. 1. 1. 1. -1., 1., 1., 1., 1., 1., -1., 1., 1 ., 1., 1., -1., 1., 1., 1., 1., 1., 1., -1., -1., 1., -1., -1., 1 ., 1. 1. 1. 1. 1. 1. -1., -1., 1., 1., 1., -1., 1., 1., 1., 1., 1., 1., 1., 1., -1., 1., 1., -1., -1., 1., 1., 1., 1., 1., 1. , 1. 1. 1. 1. 1. 1. 1. 1.])
Si vous regardez de très près, vous verrez que dbscan produit trois groupes (-1, 0 et 1).
Comment visualiser les grappes
Sortons un nuage de points de la sortie dbscan. Tapez le code suivant:
>>> From sklearn.decomposition importation PCA >>> pca = PCA (n_components = 2) .fit (iris.data) >>> pca_2d = pca.transform (iris.data) >>> for i in range (0, pca_2d.shape [0]): >>> si dbscan.labels_ [i] == 0: >>> c1 = pl.scatter (pca_2d [i, 0], pca_2d [i, 1], c = 'r' , marqueur = '+') >>> Elif dbscan.labels_ [i] == 1: >>> c2 = pl.scatter (pca_2d [i, 0], pca_2d [i, 1], c = 'g', marqueur = 'o') >>> Elif dbscan.labels_ [i] == -1: >>> c3 = pl.scatter (pca_2d [i, 0], pca_2d [i, 1], c = 'b', marqueur = '*') >>> pl.legend ([C1, C2, C3], ['Cluster 1 »,« Cluster 2', 'bruit']) >>> pl.title ('dbscan trouve 2 clusters et bruit) >>> pl.show ()Voici le diagramme de dispersion qui est la sortie de ce code:
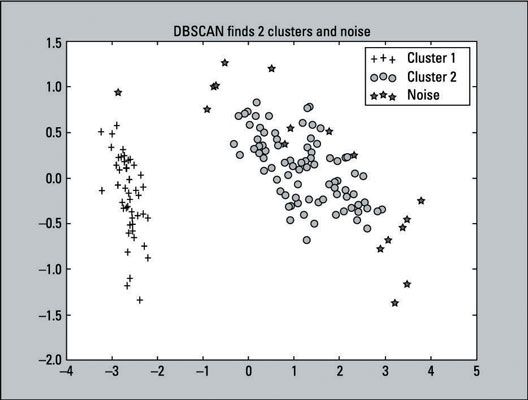
Vous pouvez voir que dbscan produit trois groupes. Notez, cependant, que le chiffre ressemble étroitement à une solution à deux-cluster: Il montre que 17 cas de l'étiquette - 1. Cela est parce qu'il est un deux-cluster Solution- le troisième groupe (-1) est le bruit (les valeurs aberrantes). Vous pouvez augmenter le paramètre de distance (EPS) de la valeur par défaut de 0,5 à 0,9, et il deviendra une solution à deux-cluster avec aucun bruit.
Le paramètre de distance est la distance maximale est une observation à la grappe la plus proche. La plus grande est la valeur du paramètre de la distance, les grappes sont moins trouvé parce grappes éventuellement se fondent dans d'autres clusters. Les étiquettes sont dispersés autour de -1 Cluster 1 et 2 Cluster en quelques endroits:
Près des bords de Cluster 2 (classes Versicolor et virginica)
Proche du centre du Cluster 2 (Versicolor et Virginica classes)
Le graphique montre seulement une représentation en deux dimensions des données. La distance peut également être mesurée dans des dimensions supérieures.
Un exemple ci-dessus Cluster 1 (la classe Setosa)
Comment évaluer le modèle
Dans cet exemple, dbscan n'a pas produit le résultat idéal avec des paramètres par défaut pour l'ensemble de données d'iris. Sa performance était assez cohérente avec d'autres algorithmes de clustering qui finissent avec une solution à deux-cluster.
L'ensemble de données Iris ne prend pas parti des fonctionnalités les plus puissantes de dbscan - détection de bruit et la capacité de découvrir des grappes de formes arbitraires. Cependant, dbscan est un algorithme de clustering très populaire et de la recherche se fait encore sur l'amélioration de sa performance.
-
 Notions de base de K-moyens et des modèles de clustering dbscan pour l'analyse prédictive
Notions de base de K-moyens et des modèles de clustering dbscan pour l'analyse prédictive - Comment regrouper par plus proches voisins dans l'analyse prédictive
- Comment créer et exécuter un modèle d'apprentissage non supervisé de faire des prédictions avec k-means
-
 Comment créer un modèle d'apprentissage supervisé par régression logistique
Comment créer un modèle d'apprentissage supervisé par régression logistique - Comment évaluer un modèle d'apprentissage sans surveillance avec des k-means
- Comment charger des données dans un modèle d'apprentissage svm supervisé
Quand vous apprenez un nouveau langage de programmation, il est de coutume d'écrire le “ Bonjour tout le monde ” programme. Pour l'apprentissage automatique et l'analyse prédictive, la création d'un modèle de classer l'ensemble de…
L'apprentissage supervisé est une tâche d'apprentissage qui apprend à la machine à partir de données d'analyse de prédiction qui ont été marqués. Une façon de penser à propos de l'apprentissage supervisé est que l'étiquetage des…
Avant que vous pouvez nourrir le classificateur Support Vector Machine (SVM) avec les données qui ont été chargés pour l'analyse prédictive, vous devez diviser l'ensemble de données complet en un ensemble de formation et un ensemble de…
K est une entrée à l'algorithme prédictif pour analyse- il représente le nombre de groupes que l'algorithme doit extraire à partir d'un ensemble de données, exprimée algébriquement comme k. Un algorithme K-means divise un ensemble de…
Un outil open-source qui est uniquement utile dans l'analyse prédictive est Apache Mahout. Cette bibliothèque d'apprentissage comprend des versions à grande échelle de la classification, la classification, filtrage collaboratif, et d'autres…
L'ensemble de données Iris est pas facile à tracer pour l'analyse prédictive dans sa forme originale, parce que vous ne pouvez pas tracer les quatre coordonnées (des fonctions) de l'ensemble de données sur un écran en deux dimensions. Par…
L'ensemble de données Iris est pas facile à tracer pour l'analyse prédictive dans sa forme originale. Par conséquent, vous devez réduire le nombre de dimensions en appliquant une algorithme de réduction de dimensionnalité qui fonctionne sur…
Visualisation des résultats de votre analyse prédictive aide vraiment les parties prenantes à comprendre les prochaines étapes. Voici quelques façons d'utiliser des techniques de visualisation de rapporter les résultats de vos modèles pour…
Avant de configurer votre Oracle Real Application Clusters 12c (RAC), enquêter sur le logiciel dont il a besoin pour fonctionner correctement. Considérez les domaines des logiciels suivants.Système d'exploitation et Oracle 12c Real Application…
Une tâche que vous pouvez souvent faire dans une feuille de calcul que vous pouvez aussi le faire en R calcule ligne ou de colonne totaux. La meilleure façon de le faire est d'utiliser les fonctions (rowSums) et colSums ().De même, utiliser les…
La quantité dans laquelle deux variables de données varient ensemble peut être décrite par le Coefficient de corrélation. Dans R, vous obtenez les corrélations entre un ensemble de variables très facilement en utilisant le cor () fonction. Il…
Une application très utile de sous-ensembles de données est de trouver et supprimer les valeurs en double. R comporte une fonction utile, dupliqué (), qui trouve des valeurs dupliquées et renvoie un vecteur logique qui vous indique si la valeur…
Maintenant que vous avez examiné les règles pour la création de sous-ensembles, vous pouvez l'essayer avec quelques trames de données dans R. Vous avez juste à rappeler que une trame de données est un objet bidimensionnel et contient des…
Vecteurs, des listes et des trames de données jouent un rôle important dans la représentation de données en R, afin d'être en mesure de préciser succinctement et correctement un sous-ensemble de vos données est importante.Il existe trois…