Comment créer un modèle d'apprentissage supervisé par régression logistique
Après vous construisez votre premier modèle prédictif de classification pour l'analyse des données, la création de plus de modèles comme il est une tâche très simples en scikit
Sommaire
Comment charger vos données
Cette liste de code va charger le iris ensemble de données dans votre session:
>>> From sklearn.datasets importer load_iris >>> iris = load_iris ()
Comment créer une instance du classificateur
Les deux lignes de code suivantes créent une instance de classificateur. La première ligne importe la bibliothèque de régression logistique. La deuxième ligne crée une instance de l'algorithme de régression logistique.
>>> De sklearn importation linear_model >>> logClassifier linear_model.LogisticRegression = (C = 1, random_state = 111)
Notez le paramètre (paramètre de régularisation) dans le constructeur. La paramètre de régularisation est utilisé pour prévenir surajustement. Le paramètre est pas strictement nécessaire (le constructeur ne fonctionne bien sans elle, car il sera par défaut à C = 1). Création d'un classificateur de régression logistique utilisant C = 150 crée une meilleure parcelle de la surface de la décision. Vous pouvez voir les deux parcelles ci-dessous.
Comment faire pour exécuter les données de formation
Vous aurez besoin de partager l'ensemble de données en apprentissage et de test avant que vous pouvez créer une instance du classificateur de régression logistique. Le code suivant accomplir cette tâche:
>>> From sklearn importation cross_validation >>> X_train, X_test, y_train, y_test = cross_validation.train_test_split (iris.data, iris.target, test_size = 0,10, random_state = 111) >>> logClassifier.fit (X_train, y_train)
Ligne 1 importe la bibliothèque qui vous permet de diviser l'ensemble de données en deux parties.
Ligne 2 appelle la fonction de la bibliothèque qui divise l'ensemble de données en deux parties et affecte les ensembles de données désormais divisées à deux paires de variables.
Ligne 3 prend l'exemple du classificateur de régression logistique vous venez de créer et appelle la s'adapter méthode pour former le modèle avec l'ensemble de données de formation.
Comment visualiser le classificateur
En regardant la surface de décision sur le terrain, il semble que quelques réglages doit être fait. Si vous regardez vers le milieu de la parcelle, vous pouvez voir que la plupart des points de données appartenant à la zone médiane (versicolor) sont couchés dans la région sur le côté droit (Virginica).
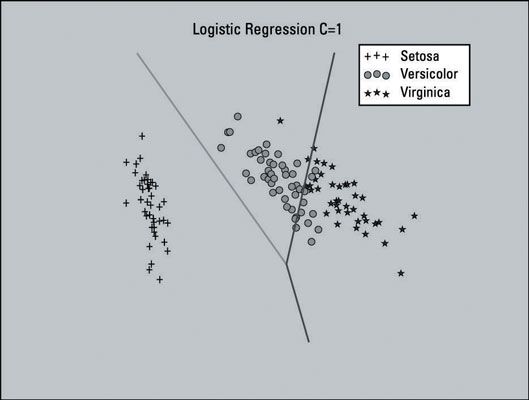
Cette image montre la surface de décision avec une valeur de C de 150. Il semble visuellement mieux, afin de choisir d'utiliser ce paramètre pour votre modèle de régression logistique semble approprié.

Comment faire pour exécuter les données de test
Dans le code suivant, la première ligne alimente l'ensemble de données de test pour le modèle et la troisième ligne affiche la sortie:
>>> LogClassifier.predict prédite = (X_test) >>> predictedarray ([0, 0, 2, 2, 1, 0, 0, 2, 2, 1, 2, 0, 2, 2, 2])
Comment évaluer le modèle
Vous pouvez traverser-de référencer la sortie de la prédiction contre le y_test tableau. En conséquence, vous pouvez voir qu'il prédit correctement tous les points de données de test. Voici le code:
>>> De métriques d'importation sklearn >>> predictedarray ([0, 0, 2, 2, 1, 0, 0, 2, 2, 1, 2, 0, 2, 2, 2]) >>> y_testarray ([ 0, 0, 2, 2, 1, 0, 0, 2, 2, 1, 2, 0, 2, 2, 2]) >>> metrics.accuracy_score (y_test, prévue) 1,0 1,0 # 100 pour cent de précision est> >> prédit == y_testarray ([Vrai, vrai, vrai, vrai, vrai, vrai, vrai, vrai, vrai, vrai, vrai, vrai, vrai, vrai, vrai], dtype = bool)
Alors, comment le modèle de régression logistique avec le paramètre C = 150 comparer à cela? Eh bien, vous ne pouvez pas battre de 100 pour cent. Voici le code pour créer et évaluer le classificateur logistique avec C = 150:
>>> LogClassifier_2 = linear_model.LogisticRegression (C = 150, random_state = 111) >>> logClassifier_2.fit (X_train, y_train) >>> prédit = logClassifier_2.predict (X_test) >>> metrics.accuracy_score (y_test, prédit) 0,93333333333333335 >>> metrics.confusion_matrix (y_test, prédit) Array ([[5, 0, 0], [0, 2, 0], [0, 1, 7]])
Nous nous attendions à mieux, mais il était en fait pire. Il y avait une erreur dans les prédictions. Le résultat est le même que celui du modèle Support Vector Machine (SVM).
Voici la liste complète du code pour créer et évaluer un modèle de classification de régression logistique avec les paramètres par défaut:
>>> From sklearn.datasets importer load_iris >>> from sklearn importation linear_model >>> from sklearn importation cross_validation >>> de mesures d'importation sklearn >>> iris = load_iris () >>> X_train, X_test, y_train, y_test = cross_validation .train_test_split (iris.data, iris.target, test_size = 0,10, random_state = 111) >>> logClassifier = linear_model.LogisticRegression (, random_state = 111) >>> logClassifier.fit (X_train, y_train) >>> prédit = logClassifier .predict (X_test) >>> predictedarray ([0, 0, 2, 2, 1, 0, 0, 2, 2, 1, 2, 0, 2, 2, 2]) >>> y_testarray ([0, 0, 2, 2, 1, 0, 0, 2, 2, 1, 2, 0, 2, 2, 2]) >>> metrics.accuracy_score (y_test, prédit) 1,0 1,0 # 100 pour cent de précision est >>> prédit == y_testarray ([Vrai, vrai, vrai, vrai, vrai, vrai, vrai, vrai, vrai, vrai, vrai, vrai, vrai, vrai, vrai], dtype = bool)
-
 Notions de base de modèles de classification pour les prédictions analytiques
Notions de base de modèles de classification pour les prédictions analytiques - Comment créer et exécuter un modèle d'apprentissage non supervisé de faire des prédictions avec k-means
-
 Comment créer un modèle d'apprentissage sans surveillance avec dbscan
Comment créer un modèle d'apprentissage sans surveillance avec dbscan - Comment évaluer un modèle d'apprentissage sans surveillance avec des k-means
-
 Comment expliquer les résultats d'une classification des r analyse prédictive modèle
Comment expliquer les résultats d'une classification des r analyse prédictive modèle - Comment expliquer les résultats analytiques prédictifs de régression r
Pour l'analyse prédictive, vous devez charger les données de vos algorithmes à utiliser. Chargement du jeu de données dans Iris scikit est aussi simple que la délivrance d'un couple de lignes de code, car scikit a déjà créé une fonction…
Pour faire des prédictions analytiques avec de nouvelles données, vous utilisez simplement la fonction avec une liste des valeurs d'attribut sept. Le code suivant fait ce travail:> NewPrediction lt; - prédire (modèle,
liste (cylindres =…
L'apprentissage supervisé est une tâche d'apprentissage qui apprend à la machine à partir de données d'analyse de prédiction qui ont été marqués. Une façon de penser à propos de l'apprentissage supervisé est que l'étiquetage des…
Avant que vous pouvez nourrir le classificateur Support Vector Machine (SVM) avec les données qui ont été chargés pour l'analyse prédictive, vous devez diviser l'ensemble de données complet en un ensemble de formation et un ensemble de…
L'ensemble de données Iris est pas facile à tracer pour l'analyse prédictive dans sa forme originale, parce que vous ne pouvez pas tracer les quatre coordonnées (des fonctions) de l'ensemble de données sur un écran en deux dimensions. Par…
L'ensemble de données Iris est pas facile à tracer pour l'analyse prédictive dans sa forme originale. Par conséquent, vous devez réduire le nombre de dimensions en appliquant une algorithme de réduction de dimensionnalité qui fonctionne sur…
Les trois opérateurs logiques qui peuvent être utilisées pour créer ce qu'on appelle expressions conditionnelles composées en C ++ sont présentés dans le tableau suivant.Les opérateurs logiquesOpérateurSignificationET- vrai si la gauche; et…
Les programmes de C doivent prendre des décisions. Un programme qui ne peuvent pas prendre des décisions est d'une utilité limitée. Invariablement, un programme d'ordinateur en arrive au point où il doit comprendre des situations telles que…
Java a deux opérateurs pour effectuer des opérations logiques Et: et . Les deux combiner deux expressions booléennes et retour vrai seulement si les deux expressions sont vrai.Voici un exemple qui utilise la base et opérateur ():if ((salesClass…
UN opérateur logique (parfois appelé “ des opérateurs booléens ”) dans la programmation Java est un opérateur qui retourne un résultat booléen qui est basé sur le résultat booléen d'un ou deux autres expressions.Parfois, des…
Il semble que tout le monde utilise Twitter pour faire connaître aujourd'hui ses sentiments. Bien sûr, le problème est que personne ne sait vraiment les points communs de ces sentiments - qui est, si quelqu'un pouvait tirer toute sorte de…
Une application très utile de sous-ensembles de données est de trouver et supprimer les valeurs en double. R comporte une fonction utile, dupliqué (), qui trouve des valeurs dupliquées et renvoie un vecteur logique qui vous indique si la valeur…
Vecteurs, des listes et des trames de données jouent un rôle important dans la représentation de données en R, afin d'être en mesure de préciser succinctement et correctement un sous-ensemble de vos données est importante.Il existe trois…
La modélisation de régression est le processus de trouver une fonction qui correspond approximativement à la relation entre les deux variables en deux listes de données. Le tableau montre les types de modèles de régression de la calculatrice…