Comment visualiser le classificateur dans un modèle d'apprentissage supervisé svm
L'ensemble de données Iris est pas facile à tracer pour l'analyse prédictive dans sa forme originale, parce que vous ne pouvez pas tracer les quatre coordonnées (des fonctions) de l'ensemble de données sur un écran en deux dimensions. Par conséquent, vous devez réduire les dimensions en appliquant une la réduction de la dimensionnalité algorithme pour les caractéristiques.
Dans ce cas, l'algorithme que vous allez utiliser pour faire la transformation de données (en réduisant les dimensions des caractéristiques) est appelée Analyse en Composantes Principales (ACP).
| Longueur des sépales | Sépale Largeur | Pétale Longueur | Pétale Largeur | Classe cible / Étiquette |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0,2 | Setosa (0) |
| 7.0 | 3.2 | 4.7 | 1.4 | Versicolor (1) |
| 6.3 | 3.3 | 6.0 | 2.5 | Virginica (2) |
L'algorithme PCA prend toutes les quatre caractéristiques (nombres), fait un peu de maths sur eux, et sort deux nouveaux numéros que vous pouvez utiliser pour faire de la parcelle. Pensez PCA comme suivant deux étapes générales:
Il prend en entrée un ensemble de données avec de nombreuses fonctionnalités.
Il réduit cette entrée à un plus petit ensemble de fonctions en transformant les composants de la fonctionnalité mis en ce qu'il considère comme les principaux (principaux) des composants (ou un algorithme déterminé défini par l'utilisateur).
Cette transformation de l'ensemble des fonctionnalités est également appelé extraction de caractéristiques. Le code suivant fait la réduction de dimension:
>>> From sklearn.decomposition importation PCA >>> pca = PCA (n_components = 2) .fit (X_train) >>> pca_2d = pca.transform (X_train)
Si vous avez déjà importé des bibliothèques ou des ensembles de données, il est pas nécessaire de ré-importer ou les charger dans votre session actuelle de Python. Si vous le faites, cependant, il ne devrait pas affecter votre programme.
Après vous exécutez le code, vous pouvez taper le pca_2d variable dans l'interprète et de voir qu'il émet des tableaux avec deux points au lieu de quatre. Ces deux nouveaux numéros sont des représentations mathématiques des quatre anciens numéros. Lorsque la fonction de réduction défini, vous pouvez tracer les résultats en utilisant le code suivant:
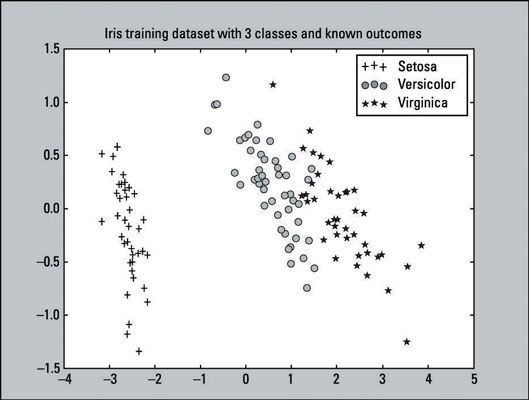
>>> Pylab d'importation comme pl >>> for i in range (0, pca_2d.shape [0]): >>> si y_train [i] == 0: >>> c1 = pl.scatter (pca_2d [i, 0], pca_2d [i, 1], c = 'r', marqueur = '+') >>> Elif y_train [i] == 1: >>> c2 = pl.scatter (pca_2d [i, 0], pca_2d [i, 1], c = 'g', marqueur = 'o') >>> Elif y_train [i] == 2: >>> c3 = pl.scatter (pca_2d [i, 0], pca_2d [i , 1], c = 'b', marqueur = '*') >>> pl.legend ([C1, C2, C3], ['Setosa »,« versicolor', 'Virginica']) >>> pl. titre ('ensemble de données de formation Iris avec 3 classes andknown résultats ») >>> pl.show ()C'est un nuage de points - une visualisation des points tracés représentant observations sur un graphique. Ce nuage de points représente notamment les résultats connus de l'ensemble de données de formation Iris. Il ya 135 points tracés (observations) de notre ensemble de données de formation. L'ensemble de données de formation se compose de
45 avantages que représentent la classe Setosa.
48 cercles qui représentent la classe versicolor.
42 étoiles qui représentent la classe Virginica.
Vous pouvez confirmer le nombre indiqué de classes en entrant le code suivant:
>>> Somme (y_train == 0) 45 >>> somme (y_train == 1) 48 >>> somme (y_train == 2) 42
De cette parcelle, vous pouvez clairement dire que la classe Setosa est linéairement séparable des deux autres classes. Alors que les classes Versicolor et Virginica ne sont pas complètement séparés par une ligne droite, ils ne sont pas de chevauchement par beaucoup. Du point de vue visuel simple, les classificateurs devraient faire assez bien.
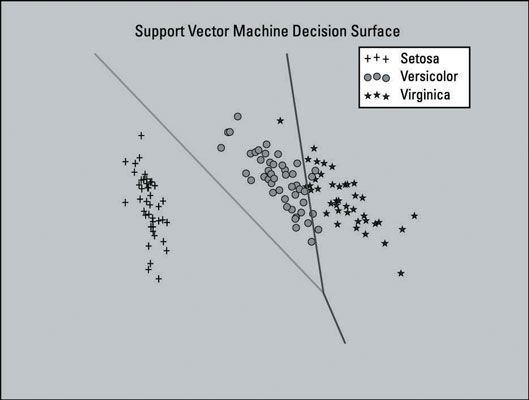
L'image ci-dessous montre un graphique de la (SVM) modèle Support Vector Machine formé avec un ensemble de données qui a été réduite à deux dimensions caractéristiques. Quatre caractéristiques est une petite fonction réglage dans ce cas, vous voulez garder tous les quatre de sorte que les données peuvent conserver la plupart de ses informations utiles. L'intrigue est montré ici comme aide visuelle.
Cette parcelle comprend le surface de décision pour le classificateur - la zone dans le graphique qui représente la fonction de décision que SVM utilise pour déterminer le résultat de la nouvelle entrée de données. Les lignes séparent les zones où le modèle permettra de prédire la classe particulière qui d'un point de données appartient.
La partie gauche de la parcelle permettront de prédire la classe Setosa, la section du milieu permettra de prédire la classe versicolor, et la section de droite permettra de prédire la classe Virginica.
Le modèle SVM que vous avez créé ne pas utiliser l'ensemble des fonctionnalités de dimensions réduites. Ce modèle utilise uniquement la réduction de la dimensionnalité ici pour générer un tracé de la surface de décision du modèle SVM - comme aide visuelle.
La liste complète du code qui crée l'intrigue est fourni comme référence. Il ne devrait pas être exécuté en séquence avec notre exemple, si vous suivez. Il peut remplacer certaines des variables que vous pouvez déjà avoir dans la session.
Le code pour produire ce complot est basé sur l'exemple de code fourni sur le scikit apprendre site Internet. Vous pouvez en apprendre plus sur la création des parcelles comme celles-ci à la scikit-learn site Internet.
Voici la liste complète du code qui crée l'intrigue:
>>> De PCA sklearn.decomposition d'importation de sklearn.datasets >>> >>> importer load_iris de sklearn importation svm >>> from sklearn importation cross_validation >>> pylab d'importation comme pl >>> numpy d'importation comme np >>> iris = load_iris () >>> X_train, X_test, y_train, y_test = cross_validation.train_test_split (iris.data, iris.target, test_size = 0,10, random_state = 111) >>> pca = PCA (n_components = 2) .fit (X_train ) >>> pca_2d = pca.transform (X_train) >>> svmClassifier_2d = svm.LinearSVC (random_state = 111) .fit (pca_2d, y_train) >>> for i in range (0, pca_2d.shape [0]): >>> si y_train [i] == 0: >>> c1 = pl.scatter (pca_2d [i, 0], pca_2d [i, 1], c = 'r', s = 50, marqueur = '+' ) >>> Elif y_train [i] == 1: >>> c2 = pl.scatter (pca_2d [i, 0], pca_2d [i, 1], c = 'g', S = 50, marqueur = 'o ') >>> Elif y_train [i] == 2: >>> c3 = pl.scatter (pca_2d [i, 0], pca_2d [i, 1], c =' b ', S = 50, marqueur =' * ') >>> pl.legend ([c1, c2, c3], [' Setosa ',' Versicolor ',' Virginica ']) >>> x_min, x_max pca_2d = [0 :,] .min () - 1, pca_2d [:, 0] .max () + 1 >>> Y_MIN, y_max = pca_2d [:, 1] .min () - 1, pca_2d [:, 1] .max () + 1 >>> xx , aa = np.meshgrid (np.arange (x_min, x_max, 0,01), np.arange (Y_MIN, y_max, 0,01)) >>> Z = svmClassifier_2d.predict (np.c_ [xx.ravel (), yy.ravel ()]) >>> Z = Z.reshape (xx.shape) >>> pl.contour (xx, yy, Z) >>> pl.title («Support Vector Machine décision Surface ') >> > pl.axis («off») >>> pl.show ()
-
 Notions de base de modèles de classification pour les prédictions analytiques
Notions de base de modèles de classification pour les prédictions analytiques -
 Comment l'analyse prédictive support de machine de vecteur prédit l'avenir
Comment l'analyse prédictive support de machine de vecteur prédit l'avenir - Comment créer et exécuter un modèle d'apprentissage non supervisé de faire des prédictions avec k-means
- Comment créer un classement de r analyse prédictive modèle
-
 Comment créer un modèle d'apprentissage sans surveillance avec dbscan
Comment créer un modèle d'apprentissage sans surveillance avec dbscan -
 Comment créer un modèle d'apprentissage supervisé par régression logistique
Comment créer un modèle d'apprentissage supervisé par régression logistique
Après que vous avez choisi votre nombre de grappes pour l'analyse prédictive et avez mis en place l'algorithme pour remplir les clusters, vous avez un modèle prédictif. Vous pouvez faire des prédictions basées sur les nouvelles données…
Pour l'analyse prédictive, vous devez charger les données de vos algorithmes à utiliser. Chargement du jeu de données dans Iris scikit est aussi simple que la délivrance d'un couple de lignes de code, car scikit a déjà créé une fonction…
Quand vous apprenez un nouveau langage de programmation, il est de coutume d'écrire le “ Bonjour tout le monde ” programme. Pour l'apprentissage automatique et l'analyse prédictive, la création d'un modèle de classer l'ensemble de…
L'apprentissage supervisé est une tâche d'apprentissage qui apprend à la machine à partir de données d'analyse de prédiction qui ont été marqués. Une façon de penser à propos de l'apprentissage supervisé est que l'étiquetage des…
Avant que vous pouvez nourrir le classificateur Support Vector Machine (SVM) avec les données qui ont été chargés pour l'analyse prédictive, vous devez diviser l'ensemble de données complet en un ensemble de formation et un ensemble de…
L'ensemble de données Iris est pas facile à tracer pour l'analyse prédictive dans sa forme originale. Par conséquent, vous devez réduire le nombre de dimensions en appliquant une algorithme de réduction de dimensionnalité qui fonctionne sur…
Il semble que tout le monde utilise Twitter pour faire connaître aujourd'hui ses sentiments. Bien sûr, le problème est que personne ne sait vraiment les points communs de ces sentiments - qui est, si quelqu'un pouvait tirer toute sorte de…
Parfois, il est intéressant de voir comment un bruit ressemble. Entendre le son que vous dit une chose à ce sujet, mais en voyant ça vous dit d'autres choses. En outre, vous pouvez utiliser les données sonores dans le cadre d'une analyse.Par…
La quantité dans laquelle deux variables de données varient ensemble peut être décrite par le Coefficient de corrélation. Dans R, vous obtenez les corrélations entre un ensemble de variables très facilement en utilisant le cor () fonction. Il…
La fonction de la parcelle en R a une type l'argument qui contrôle le type de tracé ce qui est dessiné. Par exemple, pour créer un terrain avec des lignes entre les points de données, utiliser type = "l"- pour tracer seulement les points,…
Maintenant que vous avez examiné les règles pour la création de sous-ensembles, vous pouvez l'essayer avec quelques trames de données dans R. Vous avez juste à rappeler que une trame de données est un objet bidimensionnel et contient des…
Tu utilises tapply () pour créer des résumés tabulaires de données dans R. Avec tapply (), vous pouvez facilement créer des résumés des sous-groupes de données. Cette fonction prend trois arguments:X: Un vecteurINDEX: Un facteur ou liste de…
Si vous avez des données sous la forme d'un tableau ou d'une matrice et que vous voulez pour résumer ces données, les R apply () fonction est vraiment utile. La apply () fonction traverse un tableau ou d'une matrice par colonne ou une ligne et…
Vecteurs, des listes et des trames de données jouent un rôle important dans la représentation de données en R, afin d'être en mesure de préciser succinctement et correctement un sous-ensemble de vos données est importante.Il existe trois…