La découverte des données et des bacs à sable dans Hadoop
La découverte des données devient une activité de plus en plus important pour les organisations qui comptent sur leurs données d'être un facteur de différenciation. Aujourd'hui, qui décrit la plupart des entreprises, comme la capacité de voir les tendances et extraire sens à partir d'ensembles de données disponibles applique à presque toutes les industries.
Qu'est-ce que cela exige est deux composantes essentielles: les analystes avec la créativité de penser à de nouvelles façons d'analyser des ensembles de données à poser de nouvelles questions (souvent ces sortes d'analystes sont appelés de données scientifiques) - Et de fournir ces analystes avec accès à autant de données que possible.
Envisager l'approche traditionnelle de l'analyse dans le paysage informatique d'aujourd'hui: La communauté des utilisateurs d'entreprise maintenant détermine généralement les questions d'affaires à poser - ils soumettent une demande, et l'équipe de Il construit un système qui répond à des questions spécifiques. D'un point de vue technique, parce que ce travail a toujours été fait dans une base de données relationnelle, il a été la responsabilité de l'équipe informatique pour construire des schémas, retirez la duplication des données, et ainsi de suite.
Ils investissent beaucoup de temps pour faire de ce queryable de données et de répondre rapidement aux questions préétablies que l'unité d'affaires veut répondu. Voilà pourquoi bases de données relationnelles sont généralement considérés comme schéma à l'écriture parce que vous avez à faire beaucoup de travail afin d'écrire à la base de données.
(Dans de nombreux cas, la quantité de travail vaut le investment Toutefois, dans un monde de grands volumes de données, la valeur et la qualité de nombreux nouveaux types de données avec lesquelles vous travaillez est inconnu.)
Cette approche de base de données relationnelle est bien adapté à de nombreux processus opérationnels communs, comme la surveillance des ventes par zone géographique, produit, ou CHANNEL- extraire un aperçu des enquêtes auprès des clients, des coûts et analyses de rentabilité, et plus encore - en gros, les questions sont posées maintes et maintes fois.
Les données sont généralement très structuré et est probablement très confiance dans cet environnement respectueux de l'environnement dans cette cette activité est Analytics guidées.
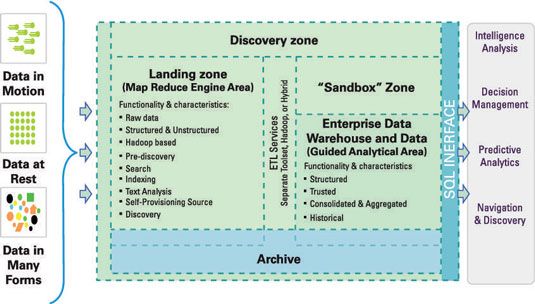
Par analogie, il est comme si votre 8-year-old enfant prend une pause pour la récréation à l'école. Pour la plupart, elle peut faire ce qu'elle veut dans l'enceinte de l'école - tant qu'elle reste dans le long de son périmètre clôturé cependant, elle ne peut pas sauter la clôture pour découvrir ce qui est à l'extérieur. Plus précisément, votre enfant peut explorer une connue, contrôlée (dans le schéma) zone et d'analyser tout ce qui peut être trouvé dans cette zone.
Maintenant, imaginez que votre environnement d'analyse a une zone de découverte. Dans ce scénario, il fournit des données (il est susceptible de ne pas être entièrement confiance, et il est probable “ sale ”) sur une plate-forme de découverte souple pour les utilisateurs professionnels à poser pratiquement toutes les questions qu'ils veulent.
Dans l'analogie, votre enfant est autorisé à escalader la clôture d'école (ce domaine est schéma-moins), incursion dans la forêt, et revenir avec tout ce qu'elle découvre articles. (Bien sûr, dans le monde de l'informatique, vous ne devez pas vous inquiéter au sujet des utilisateurs d'affaires de se perdre ou d'obtenir le sumac vénéneux.)
Si vous pensez cela, miroirs de découverte de données à certains égards, l'évolution de l'exploitation minière de l'or. Pendant les années de ruée vers l'or des vieux, des grèves d'or susciterait l'investissement de ressources parce que quelqu'un a découvert l'or - il était visible à l'œil nu, il avait une valeur claire, et elle a donc justifié l'investissement.
Il ya cinquante ans, personne ne pouvait se permettre de mine de minerai à faible teneur de l'or parce que ne existaient pas rentable ou de technologies propres (équipements pour se déplacer et gérer de grandes quantités de minerai était pas disponible) et le minerai riche qualité était toujours disponible (par rapport à aujourd'hui, l'or a été relativement facile à trouver). Tout simplement, il n'a pas été rentable (ou même possible) de travailler à travers le bruit (minerai à faible teneur) pour trouver les signaux (l'or).
Avec Hadoop, boutiques informatiques ont désormais les biens d'équipement pour traiter des millions de tonnes de minerai (données avec une faible valeur par octet) pour trouver de l'or qui est presque invisible à l'œil nu (données à forte valeur par octet). Et qui est exactement ce que la découverte est tout au sujet.
Il faut avoir un faible coût, référentiel souple où l'investissement prochaine à zéro est faite pour enrichir les données jusqu'à ce qu'une découverte est faite. Après une découverte est faite, il pourrait être judicieux de demander plus de ressources (à la mienne la découverte de l'or) et de formaliser dans un processus d'analyse qui peut être déployée dans un entrepôt de données ou data mart spécialisée.
Lorsque idées sont faites dans la zone de la découverte, qui est probablement un bon moment pour engager le département IT et de formaliser un processus, ou ont ces gens prêtent assistance à plus découverte en profondeur. En fait, ce nouveau modèle pourrait même se déplacer dans la zone de l'analyse guidées.
Le point est qu'il provisionné la zone de découverte pour les utilisateurs professionnels à poser et inventent des questions qu'ils ont pas pensé avant. Parce que cette zone réside dans Hadoop, il est agile et permet aux utilisateurs de se hasardent dans le Wild Blue Yonder.
Notez que la figure a une zone de sandbox. Dans certaines architectures de référence, cette zone est associé à la zone de détection. Gardez ces zones distinctes parce que cette région est utilisée par les développeurs d'applications et de boutiques informatiques pour faire leur propre recherche, les applications de test, et, peut-être, de formaliser les conclusions et les constatations dans la Zone de découvertes lorsque l'assistance informatique est nécessaire après une découverte potentielle est faite.
L'architecture de référence est flexible et peut facilement être modifié. Rien est coulé dans le béton: vous pouvez prendre ce que vous avez besoin, laissez ce que vous ne le faites pas, et ajouter vos propres nuances.
Par exemple, certaines organisations peuvent choisir de co-localiser toutes les zones en une seule Hadoop clustering certains peuvent choisir d'exploiter un seul cluster conçu pour purposes- multiples et d'autres physiquement peut les séparer.
-
 Intégrer les grandes données avec l'entrepôt de données traditionnelle
Intégrer les grandes données avec l'entrepôt de données traditionnelle -
 La modernisation de l'entrepôt de données avec Hadoop
La modernisation de l'entrepôt de données avec Hadoop -
 Les facteurs qui augmentent l'échelle d'analyse statistique dans Hadoop
Les facteurs qui augmentent l'échelle d'analyse statistique dans Hadoop - Hadapt et Hadoop
-
 Hadoop comme un moteur de prétraitement des données
Hadoop comme un moteur de prétraitement des données - Hadoop comme une archive interrogeable des données de l'entrepôt froid
Le coût peu onéreux de stockage pour Hadoop plus la possibilité d'interroger les données Hadoop Hadoop avec SQL rend la destination de choix pour les données d'archives. Ce cas d'utilisation a un faible impact sur votre organisation parce que…
Il ya des raisons impérieuses que SQL a su résister. L'industrie des TI a eu 40 ans d'expérience avec SQL, car il a d'abord été développé par IBM au début des années 1970. Avec l'augmentation de l'adoption de bases de données…
Lorsque vous essayez de déchiffrer ce que l'environnement de l'analyse pourrait ressembler à l'avenir, vous tomberez sur le modèle du temps et le temps basé sur Hadoop zone d'atterrissage à nouveau. En fait, il est même plus une discussion à…
Après il est initialement collectées, les données sont généralement dispersé dans une déclaration il réside dans plusieurs systèmes de bases de données et ou doit être analysé avant prédire rien. Avant que vous pouvez l'utiliser pour un…
Si votre entreprise n'a pas encore d'utiliser la classification des données utilisées dans l'analyse prédictive, peut-être il est temps de le présenter comme un moyen de prendre de meilleures décisions de gestion ou d'exploitation. Ce…
Vous trouverez la valeur en apportant les capacités de l'entrepôt de données et de l'environnement de données grand ensemble. Vous devez créer un environnement hybride où les grandes données peuvent travailler main dans la main avec…
L'idée d'un data mart est loin d'être révolutionnaire, malgré ce que vous pouvez lire sur les blogs et dans la presse professionnelle de l'ordinateur, et ce que vous pouvez entendre lors de conférences ou séminaires. Un magasin de données est…
À certains moments, l'exploration de données pour l'entreposage de données ne sont pas mélangés avec les autres formes de business intelligence. Ce manque d'intégration se produit pour deux raisons:Les utilisateurs professionnels ne disposent…
Alors, qu'est-ce qu'un entrepôt de données? Dans un sens littéral, il est correctement décrite par les définitions spécifiques des deux mots qui composent le terme:Données: Faits et informations sur quelque choseEntrepôt: Un emplacement ou…
UN entrepôt de données est une maison pour vos données de grande valeur, ou actifs de données. La plupart des organisations à construire un entrepôt de données pour les actifs de données fabriqués d'une manière relativement simple,…
Les produits traditionnels de business intelligence sont pas vraiment conçus pour traiter les données volumineuses, ils peuvent nécessiter une certaine modification. Ils ont été conçus pour fonctionner avec des données hautement structurées,…
Avec l'avènement de grands volumes de données, les modèles de déploiement pour la gestion des données sont en train de changer. L'entrepôt de données traditionnelle est généralement mis en œuvre sur un seul grand système au sein du centre…
Le marché de l'entrepôt de données a en effet commencé à changer et à évoluer avec l'avènement de grands volumes de données. Dans le passé, il était tout simplement pas rentable pour les entreprises de stocker la quantité massive de…
Entreprises nagent dans les grandes données. Le problème est que souvent ils ne savent pas comment l'utiliser de manière pragmatique que les données pour être en mesure de prédire l'avenir, exécuter des processus d'affaires importants, ou…