Analyse des journaux de données avec Hadoop
L'analyse du journal est un cas d'utilisation commune pour un projet inaugurale Hadoop. En effet, les premières utilisations de Hadoop étaient pour l'analyse à grande échelle de clickstream grumes - grumes que les données sur les pages Web que les gens visitent et dans quel ordre ils les visitent record.
Tous les journaux de données générées par votre infrastructure informatique sont souvent désignés comme échappement de données. Un journal est un sous-produit d'un serveur de fonctionnement, tout comme la fumée provenant de la tuyau d'échappement d'un moteur de travail. Échappement de données a la connotation de la pollution ou des déchets, et de nombreuses entreprises se rapproche indubitablement ce genre de données avec cette pensée en tête.
Données journal augmente souvent rapidement, et en raison des hauts volumes produits, il peut être fastidieux d'analyser. Et, la valeur potentielle de ces données est souvent difficile. Alors la tentation dans les services informatiques est de stocker ces données de log pour aussi peu de temps que possible. (Après tout, il coûte de l'argent pour conserver les données, et si il n'y a aucune valeur commerciale perçue, pourquoi stocker?)
Mais Hadoop change le calcul: Le coût de stockage de données est relativement peu coûteux, et Hadoop a été initialement développé spécialement pour le traitement par lots à grande échelle des données du journal.
Le cas des données de journal analyse de l'utilisation est un lieu utile de commencer votre voyage Hadoop parce que les chances sont bonnes que les données que vous travaillez avec est en cours de suppression, ou “ est tombé à l'étage ”. Certaines entreprises qui enregistrent constamment un téraoctet (To) ou plus de l'activité web de client par semaine Jeter les données avec aucune analyse (qui vous fait vous demander pourquoi ils pris la peine de recueillir).
Pour commencer rapidement, les données dans ce cas d'utilisation est susceptible facile à obtenir et généralement ne pas englober les mêmes problèmes que vous rencontrerez si vous commencez votre voyage Hadoop avec d'autres données (régies).
Lorsque les analystes de l'industrie discutent des volumes croissants de données rapide qui existent (4.1 exaoctets en 2014 - les disques durs de plus de 4 millions de 1 To), connecter les comptes de données pour une grande partie de cette croissance. Et pas étonnant: Presque tous les aspects de la vie se traduit maintenant dans la production de données. Un smartphone peut générer des centaines d'entrées de journal par jour pour un utilisateur actif, le suivi non seulement la voix, le texte, et le transfert de données, mais aussi des données de géolocalisation.
La plupart des ménages ont maintenant des compteurs intelligents qui se connectent leur consommation d'électricité. Les nouvelles voitures ont des milliers de capteurs qui enregistrent les aspects de leur condition et l'utilisation. Chaque clic et la souris mouvement que vous faites tout en naviguant sur l'Internet provoque une cascade d'entrées de journal à générer.
Chaque fois que vous achetez quelque chose - même sans l'aide d'une carte de crédit ou carte de débit - systèmes enregistrent l'activité des bases de données - et dans les journaux. Vous pouvez voir quelques-unes des sources les plus courantes de données de journal: serveurs informatiques, clickstreams web, des capteurs et des systèmes de transaction.
Chaque secteur d'activité (ainsi que tous les types de journaux viennent d'être décrites) ont l'énorme potentiel d'analyse précieux - surtout quand vous pouvez vous concentrer sur un type spécifique de l'activité et ensuite corréler vos résultats avec un autre ensemble pour fournir le contexte des données.
Comme un exemple, considérez ceci navigation et d'achat d'expérience sur le Web typique:
Vous surfez sur le site, à la recherche d'articles à acheter.
Vous cliquez pour lire les descriptions d'un produit qui attire votre attention.
Finalement, vous ajoutez un article à votre panier et passez à la caisse (l'action d'achat).
Après avoir vu le coût de l'expédition, cependant, vous décidez que le produit ne vaut pas le prix et vous fermez la fenêtre du navigateur. Chaque clic vous avez fait - et ensuite arrêté faisant - a le potentiel d'offrir un aperçu précieux pour l'entreprise derrière ce site e-commerce.
Dans cet exemple, supposons que cette entreprise recueille des données clickstream (données concernant chaque clic de souris et page vue que le visiteur “ touche ”) dans le but de comprendre comment mieux servir ses clients. Un défi commun entre les entreprises d'e-commerce est de reconnaître les facteurs clés derrière des caddies abandonnés. Lorsque vous effectuez une analyse plus approfondie sur les données de parcours et d'examiner le comportement des utilisateurs sur le site, les modèles sont liés à émerger.
Votre entreprise connaît la réponse à la question apparemment simple, “ ya certains produits abandonné plus que d'autres ”?; Ou la réponse à la question, “? Combien de revenus peuvent être repris si vous diminuez abandon de panier de 10 pour cent ” Ce qui suit donne un exemple du genre de rapports que vous pouvez montrer à vos chefs d'entreprises pour solliciter leur investissement dans votre cause Hadoop.
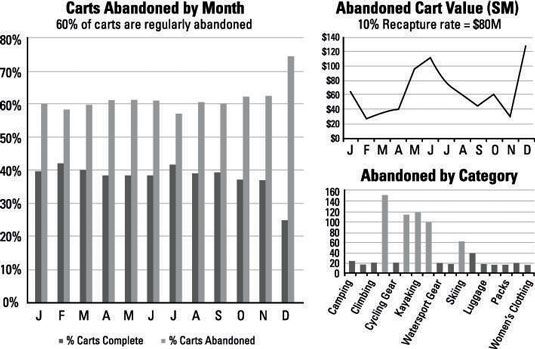
Pour en arriver au point où vous pouvez générer les données pour construire les graphiques présentés, vous isolez les sessions de navigation Web des utilisateurs individuels (un processus connu sous le nom sessionization), identifier le contenu de leurs paniers d'achat, puis établir l'état de la transaction à la fin de la session - tout en examinant les données de parcours.
Ce qui suit est un exemple de la façon d'assembler les sessions de navigation Web des utilisateurs en regroupant tous les clics et les adresses URL par adresse IP.
Dans un contexte Hadoop, vous travaillez toujours avec les touches et les valeurs - chaque phase des entrées de MapReduce et délivre des données en ensembles de clés et de valeurs. La clé est l'adresse IP, et la valeur se compose de l'horodatage et l'URL. Pendant la phase de la carte, les sessions des utilisateurs sont assemblés en parallèle pour tous les blocs de fichiers de l'ensemble de données clickstream qui est stocké dans votre cluster Hadoop.

La phase de la carte renvoie ces éléments:
La dernière page qui est visité
Une liste d'articles dans le panier
L'état de la transaction pour chaque session utilisateur (indexée par la clé de l'adresse IP)
Le réducteur ramasse ces dossiers et effectue des agrégations au total, le nombre et la valeur des paniers abandonnés par mois et de fournir des totaux des dernières pages les plus courantes que quelqu'un consulté avant de terminer la session de l'utilisateur.
-
 Cloudera Impala et Hadoop
Cloudera Impala et Hadoop -
") Les blocs de données dans le système de fichiers distribué Hadoop (HDFS)
Les blocs de données dans le système de fichiers distribué Hadoop (HDFS) - La transformation des données dans Hadoop
-
 La modernisation de l'entrepôt de données avec Hadoop
La modernisation de l'entrepôt de données avec Hadoop - Traitement distribué Hadoop MapReduce avec
- Les facteurs qui augmentent l'échelle d'analyse statistique dans Hadoop
Vers la fin de l'année 2010, Hadapt a été formé comme une start-up par deux étudiants de l'Université de Yale et professeur adjoint de science informatique. Professeur Daniel Abadi et Kamil Bajda-Pawlikowski, un étudiant au doctorat du…
Un des premiers cas d'utilisation de Hadoop dans l'entreprise était comme un moteur de transformation programmatique utilisé pour prétraiter les données à destination d'un entrepôt de données. Essentiellement, ce cas d'utilisation exploite la…
Sqoop (SQL-à-Hadoop) est un outil grand de données qui offre la possibilité d'extraire des données à partir des données magasins non Hadoop, transformer les données en une forme utilisable par Hadoop, puis charger les données dans HDFS. Ce…
IBM a une longue histoire de collaboration avec SQL et de la technologie de base de données. En accord avec cette histoire, la solution d'IBM pour SQL sur Hadoop exploite des composants de ses technologies de base de données relationnelles qui…
Hadoop, un framework logiciel open-source, utilise HDFS (le système de fichiers distribués Hadoop) et MapReduce pour analyser les données de grandes sur des groupes de produits de base sur le matériel qui est, dans un environnement de calcul…
Pour permettre une meilleure compréhension des alternatives SQL-sur-Hadoop Hive, il pourrait être utile d'examiner une amorce sur le traitement massivement parallèle (MPP) des bases de données en premier.Apache Hive est posée sur le dessus du…
Parce que de nombreux déploiements Hadoop existants ne sont toujours pas encore à l'aide de Yet Another négociateur des ressources (FIL), de prendre un coup d'oeil à la façon dont Hadoop a réussi son traitement de données avant les jours de…
Il ya des raisons impérieuses que SQL a su résister. L'industrie des TI a eu 40 ans d'expérience avec SQL, car il a d'abord été développé par IBM au début des années 1970. Avec l'augmentation de l'adoption de bases de données…
Hadoop est plus que MapReduce et HDFS (Distributed File System Hadoop): Il est également une famille de projets connexes (un écosystème, vraiment) pour le calcul distribué et le traitement de données à grande échelle. La plupart (mais pas…
Lorsque vous essayez de déchiffrer ce que l'environnement de l'analyse pourrait ressembler à l'avenir, vous tomberez sur le modèle du temps et le temps basé sur Hadoop zone d'atterrissage à nouveau. En fait, il est même plus une discussion à…
Hadoop est une plate-forme de logiciel libre, open-source pour l'écriture et l'exécution d'applications qui traitent une grande quantité de données pour l'analyse prédictive. Il permet un traitement parallèle distribué de grands ensembles de…
Faites l'inventaire du type de données que vous traitez avec votre grand projet de données. De nombreuses organisations reconnaissent que beaucoup de données générées en interne n'a pas été utilisé à son plein potentiel dans le passé.En…
Beaucoup d'entreprises explorent de gros problèmes de données et à venir avec des solutions innovantes. Il est maintenant temps de prêter attention à un certain les meilleures pratiques, ou principes de base, qui vous servira ainsi que vous…
Obtenir le bon point de vue sur la qualité des données peut être très difficile dans le monde du big data. Avec la majorité des grandes sources de données, vous devez supposer que vous travaillez avec des données qui ne sont pas propres. En…