Enregistrer des données avec déversoir dans HDFS
Certaines des données qui finit dans le système de fichiers distribués Hadoop (HDFS) pourrait atterrir là, via les opérations de chargement de base de données ou d'autres types de processus de traitement par lots, mais que faire si vous voulez capturer les données qui coule en haut débit des flux de données, tels que les données des journaux d'application? Apache Flume est le moyen le standard actuel pour le faire facilement, efficacement et en toute sécurité.
Apache Flume, un autre projet de haut niveau de l'Apache Software Foundation, est un système distribué pour l'agrégation et le déplacement de grandes quantités de flux de données provenant de différentes sources dans un magasin de données centralisée.
Autrement dit, Flume est conçu pour l'ingestion continue de données dans HDFS. Les données peuvent être tout type de données, mais Flume est particulièrement bien adapté à la manipulation des données de journal, comme les données des journaux de serveurs Web. Unités de données que les processus sont appelés Flume événements- un exemple d'un événement est un enregistrement de journal.
Pour comprendre comment fonctionne Flume sein d'un cluster Hadoop, vous devez savoir que Flume fonctionne comme un ou plusieurs agents, et que chaque agent a trois composants connectables: sources, les canaux et les puits:
Sources récupérer des données et l'envoyer à canaux.
Chaînes organiser les files d'attente de données et servir de relais entre les sources et les puits, ce qui est utile lorsque le débit entrant dépasse le débit sortant.
Éviers données de processus qui a été prise à partir des canaux et de le livrer à une destination, tels que HDFS.
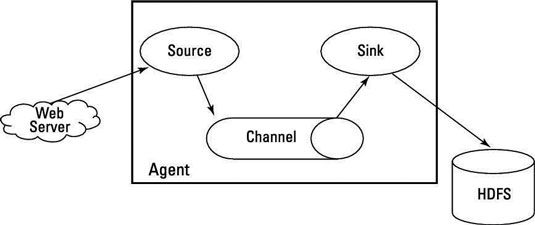
Un agent doit avoir au moins un de chaque composant afin de fonctionner, et chaque agent est contenu dans sa propre instance de la machine virtuelle Java (JVM).
Un événement qui est écrit à un canal par une source est pas retiré de ce canal jusqu'à un évier enlève au moyen d'une transaction. Si une panne de réseau se produit, les canaux de garder leurs événements en file d'attente jusqu'à ce que les puits peuvent les écrire dans le cluster. Un canal en mémoire peut traiter les événements rapidement, mais il est volatil et ne peut être récupéré, alors un canal basé sur des fichiers propose persistance et peut être récupéré en cas d'échec.
Chaque agent peut avoir plusieurs sources, les canaux et les puits, et même si une source peut écrire à de nombreuses chaînes, un évier peut prendre des données d'un seul canal.
Un agent est juste une JVM qui exécute Flume, et les éviers pour chaque noeud d'agent dans le cluster Hadoop envoyer des données à nœuds de collection, qui agréger les données provenant de nombreux agents avant de les écrire à HDFS, où il peut être analysé par d'autres outils Hadoop.
Les agents peuvent être enchaînés de telle sorte que l'évier d'un agent envoie les données à la source d'un autre agent. Avro, cadre d'appel et de sérialisation à distance d'Apache, est la façon habituelle de l'envoi de données à travers un réseau avec Flume, car il sert comme un outil utile pour la sérialisation efficace ou la transformation de données dans un format binaire compact.
Dans le contexte de la Flume, la compatibilité est important: Un événement Avro nécessite une source Avro, par exemple, et un évier doit livrer les événements qui sont appropriés à la destination.
Ce qui rend cette grande chaîne de sources, les canaux, les puits et le travail est la configuration de l'agent Flume, qui est stocké dans un fichier texte local qui est structuré comme un fichier de propriétés Java. Vous pouvez configurer plusieurs agents dans le même fichier. Regardez un exemple de fichier, qui est nommé canal-agent.conf - il est mis à configurer un agent chaman nommé:
# Identifier les composants sur l'agent chaman: shaman.sources = netcat_s1shaman.sinks = = hdfs_w1shaman.channels en mem_c1 # configurer la source: shaman.sources.netcat_s1.type = netcatshaman.sources.netcat_s1.bind = localhostshaman.sources.netcat_s1. Port = 44444 # Décrire l'évier: shaman.sinks.hdfs_w1.type = hdfsshaman.sinks.hdfs_w1.hdfs.path = HDFS: //shaman.sinks.hdfs_w1.hdfs.writeFormat = Textshaman.sinks.hdfs_w1.hdfs.fileType = DataStream # Configurer un canal qui tamponne les évènements en mémoire: shaman.channels.in-mem_c1.type = memoryshaman.channels.in-mem_c1.capacity = 20000shaman.channels.in-mem_c1.transactionCapacity = 100 # Bind la source et l'évier à la chaîne: shaman.sources.netcat_s1.channels = de = en-mem_c1shaman.sinks.hdfs_w1.channels à-mem_c1
Le fichier de configuration comprend les propriétés de chaque source, le canal, et l'évier dans l'agent et précise comment ils sont connectés. Dans cet exemple, l'agent chaman a une source qui écoute les données (messages à netcat) sur le port 44444, un canal qui tamponne les données d'événements dans la mémoire, et un évier qui enregistre les données d'événements à la console.
Ce fichier de configuration aurait pu être utilisé pour définir plusieurs Agents De là, vous configurez seul à garder les choses simples.
Pour démarrer l'agent, utilisez un script shell appelé canal-ng, qui est situé dans le répertoire bin de la distribution Flume. De la ligne de commande, exécutez la commande de l'agent, en spécifiant le chemin vers le fichier de configuration et le nom de l'agent.
L'exemple de commande suivante démarre l'agent Flume:
canal-ng agent de -f /-n chamane
Le journal de l'agent Flume devrait avoir engagements en veillant à ce que la source, le canal, et un évier démarré avec succès.
Pour tester davantage la configuration, vous pouvez telnet sur le port 44444 depuis un autre terminal et envoyer Flume un événement en entrant une chaîne de texte arbitraire. Si tout va bien, la Flume sortie volonté terminal initial de l'événement dans un message de journal que vous devriez être capable de voir dans le journal de l'agent.

")
 fédération")
 haute disponibilité")
Sqoop (SQL-à-Hadoop) est un outil grand de données qui offre la possibilité d'extraire des données à partir des données magasins non Hadoop, transformer les données en une forme utilisable par Hadoop, puis charger les données dans HDFS. Ce…
Le système de fichiers distribués Hadoop est un résilient approche polyvalente, cluster à la gestion des fichiers dans un environnement grand de données. HDFS est pas la destination finale pour les fichiers. Au contraire, il est un service de…
Prêt à plonger dans l'importation de données avec Sqoop? Commencez par jeter un oeil à la figure, qui illustre les étapes d'une opération typique Sqoop d'importation à partir d'un SGBDR ou un système d'entrepôt de données. Rien de trop…
Hadoop, un framework logiciel open-source, utilise HDFS (le système de fichiers distribués Hadoop) et MapReduce pour analyser les données de grandes sur des groupes de produits de base sur le matériel qui est, dans un environnement de calcul…
HDFS est l'une des deux principales composantes de l'Hadoop Structures à l'autre est le paradigme de calcul connu comme MapReduce. UN système de fichiers distribué est un système de fichier qui gère le stockage dans un cluster en réseau des…
Distributed File System Hadoop (HDFS) est conçu pour stocker des données sur peu coûteux et plus fiable, le matériel. Peu coûteux a une jolie bague à elle, mais elle soulève des préoccupations quant à la fiabilité du système dans son…
Dans un cluster Hadoop, chaque noeud de données (également connue en tant que nœud esclave) Exécute un processus de fond nommée DataNode. Ce processus d'arrière-plan (également connu en tant que démon) Garde la trace des tranches de données…
Hadoop est plus que MapReduce et HDFS (Distributed File System Hadoop): Il est également une famille de projets connexes (un écosystème, vraiment) pour le calcul distribué et le traitement de données à grande échelle. La plupart (mais pas…
Un entrepôt de données est, par sa nature même, un magasin physique de données distribuée. Répartition de vos actifs informationnels aide à la performance et la convivialité entre les systèmes et dans toute l'entreprise. Faire ce niveau de…
Faites l'inventaire du type de données que vous traitez avec votre grand projet de données. De nombreuses organisations reconnaissent que beaucoup de données générées en interne n'a pas été utilisé à son plein potentiel dans le passé.En…
Agents jouent un rôle important dans l'architecture Unicenter TNG. Les agents sont des programmes qui Unicenter TNG utilise pour surveiller les objets gérés, qui comprennent les ressources du réseau tels que les serveurs de base de données,…
La relation entre un agent immobilier et un client est appelé relation fiduciaire. Fiduciary signifie fidèle serviteur, et un agent est un fiduciaire du client. Dans l'immobilier, un courtier ou un vendeur peut être l'agent d'un vendeur ou un…
Les canaux MIDI vous permettent de désigner les messages qui vont à une machine particulière. Vous pouvez programmer chaque machine pour recevoir des messages sur un ou plusieurs des 16 canaux MIDI. Par exemple, vous pouvez configurer votre…
En Australie, si vous êtes un comptable du contrat fournissant des services BAS, alors vous devez vous inscrire comme un agent BAS. La pénalité pour fournir des services de BAS sans vous inscrire gammes à partir d'un non négligeable 43 000 $…