Comment utiliser des fréquences ou des densités avec vos données en r
En brisant vos données à des intervalles de R, vous perdez encore certaines informations. Pourtant, la manière la plus complète de décrire vos données est en estimant la fonction de densité de probabilité
(PDF) ou densité de votre variable.Si ce concept est inconnu pour vous, ne vous inquiétez pas. Rappelez-vous que la densité est proportionnelle à la chance que toute valeur à vos données est approximativement égale à cette valeur. En fait, pour un histogramme, la densité est calculée à partir des chiffres, de sorte que la seule différence entre un histogramme des fréquences et une avec des densités, est l'ampleur de la y-axe. Pour le reste, ils sont exactement les mêmes.
Comment faire pour créer un terrain de densité
On peut estimer la fonction de densité d'une variable en utilisant le densité () fonction. La sortie de cette fonction elle-même ne vous dit pas grand-chose, mais vous pouvez facilement l'utiliser dans un complot. Par exemple, vous pouvez obtenir la densité de la variable de kilométrage mpg comme ça:
> Mpgdens lt; - densité (voitures $ mpg)
L'objet que vous obtiendrez de cette façon est une liste contenant beaucoup d'informations que vous ne avez pas vraiment besoin de regarder. Mais cette liste rend traçant la densité aussi facile que de dire “ parcelle la densité ” ;:
> Plot (mpgdens)
L'intrigue semble un peu rude sur les bords, mais la chose importante est de voir comment vos données sort. L'objet de la densité est tracée une ligne, avec les valeurs réelles de vos données sur le X-axe et la densité de la y-axe.
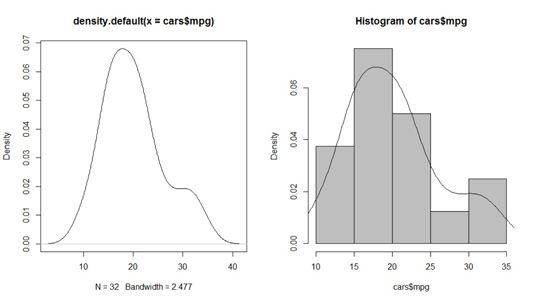
La mpgdens objet de liste contient - entre autres choses - un élément appelé X et un appelé y. Ceux-ci représentent la X- et y-coordonnées pour tracer la densité. Lorsque R calcule la densité, la densité () fonction divise vos données dans un certain nombre de petits intervalles et calcule la densité du milieu de chaque intervalle. Ces milieux sont les valeurs pour X, et les densités calculées sont les valeurs de y.
Comment tracer densités dans un histogramme
Rappelez-vous que le hist () fonction renvoie les chiffres pour chaque intervalle. Maintenant, la chance que la valeur se trouve dans un certain intervalle est directement proportionnelle aux comtes. Les plus de valeurs que vous avez dans un certain intervalle, plus les chances que toute valeur que vous avez choisi est couché dans cet intervalle.
Ainsi, au lieu d'avoir fomenté les chefs de l'histogramme, vous pourriez tout aussi bien tracer les densités. R fait tous les calculs pour vous - la seule chose que vous devez faire est de définir la fréq argument du hist () à FAUX, comme ça:
> Hist (voitures $ mpg, col = 'grise', fréq = FALSE)
Maintenant, la parcelle sera exactement le même que avant- seules les valeurs sur le y-axe sont différents. L'échelle sur le y-axe est réglé de telle manière que vous pouvez ajouter le complot de densité sur l'histogramme. Pour cela, vous utilisez le (lignes) fonctionner avec l'objet de densité comme argument.
Ainsi, vous pouvez, par exemple, fantaisie jusqu'à l'histogramme précédente un peu plus loin en ajoutant la densité estimée en utilisant le code suivant immédiatement après la commande précédente:
> Lignes (mpgdens)
Vous voyez le résultat de ces deux commandes sur le côté droit. Rappelez-vous que (lignes) utilise le X et y des éléments de l'objet de la densité mpgdens pour tracer la ligne.
-
 Envisager la densité et l'apparence de vos infographie
Envisager la densité et l'apparence de vos infographie -
 Comment créer des types de terrain différents à r
Comment créer des types de terrain différents à r - Comment extraire des données de parcelles dans r
-
 Comment tracer des histogrammes avec vos données en r
Comment tracer des histogrammes avec vos données en r -
 Changer d'échelle et d'ajuster bacs sur un histogramme
Changer d'échelle et d'ajuster bacs sur un histogramme -
 Comment tracer une valeur sur un histogramme TI-Nspire
Comment tracer une valeur sur un histogramme TI-Nspire
Un des défis que vous rencontrerez au cours de votre temps comme un développeur Android développe des applications pour plusieurs tailles d'écran. Il ya beaucoup de choses à garder à l'esprit au cours de votre aventure dans les tailles…
Parce qu'un objectif principal de l'économétrie est d'examiner les relations entre les variables, vous devez être familier avec les probabilités qui combinent des informations sur les deux variables. UN bivariées ou densité de probabilité…
La fonction de densité cumulative (CDF) d'une variable aléatoire X est le somme ou exercice des probabilités jusqu'à une certaine valeur. Il montre comment la somme des probabilités est proche de 1, ce qui se produit parfois à un taux constant…
UN fonction de densité de probabilité (PDF) présente les probabilités d'une variable aléatoire de toutes les valeurs possibles. Les probabilités associées à des valeurs spécifiques (ou des événements) à partir d'une variable aléatoire…
En économétrie, une version spécifique d'une variable aléatoire normalement distribué est la normale standard. UN distribution normale est une distribution normale avec une moyenne de 0 et une variance de 1. Il est utile parce que vous pouvez…
En économétrie, une variable aléatoire avec une distribution normale a une fonction de densité de probabilité qui est continue, symétrique, et en forme de cloche. Bien que de nombreuses variables aléatoires peuvent avoir une distribution en…
La nanotechnologie a beaucoup à offrir dans le domaine du stockage de l'énergie. Bien qu'une grande partie de la recherche est axée sur l'amélioration des batteries et des piles à combustible, une partie de la plus excitante pourrait être avec…
Dans la physique, de la densité est le rapport de masse de volume. Tout objet solide qui est moins dense que l'eau des flotteurs. La densité est une propriété importante d'un fluide car la masse est distribuée en continu tout au long d'un…
Utilisation de la physique, vous pouvez montrer comment masse et le volume sont liée à la densité. Vous pouvez également calculer la densité d'un matériau, comme l'essence, si vous connaissez sa densité.Voici quelques questions pratiques que…
En physique, une substance de densité est le rapport de la densité de cette substance à la densité de l'eau à 4 degrés Celsius. Parce que la densité de l'eau à 4 degrés Celsius est de 1000 kg / m3, ce rapport est facile à trouver. Par…
Le test GED science va poser des questions liées aux statistiques descriptives. Vous pouvez souvent résumer un ensemble de données (d'une expérience, des observations, ou des enquêtes, par exemple) en utilisant statistiques descriptives,…
UN lipoprotéine est un croisement entre un lipide, tel que le cholestérol ou les triglycérides, et une protéine. Parce que les graisses et l'eau ne se mélangent pas bien, lipoprotéine sert de mode de transport pour le cholestérol et d'autres…
Les investisseurs de l'énergie ont besoin de comprendre comment le pétrole est classé. Les termes conventionnel et non conventionnelle tout simplement se rapporter à la façon dont l'huile est produite. Que conventionnelles ou non, il est tout…
Si vous souhaitez investir dans l'industrie du pétrole, vous avez besoin de savoir quel type d'huile que vous allez obtenir pour votre argent. Le pétrole brut est classé en deux grandes catégories: légers et doux, lourds et aigre.Une entreprise…