Comment mettre en place la fonction de régression de la population (PRF) modèle
Avant de commencer avec l'analyse de régression, vous devez identifier le regre de populationsfonction de Sion (PRF). Le PRF définit la réalité (ou votre perception de celui-ci) en ce qui concerne votre sujet d'intérêt. Pour l'identifier, vous devez déterminer vos variables dépendantes et indépendantes (et comment ils seront mesurés) ainsi que la fonction mathématique décrivant la façon dont les variables sont liées.
Après vous affiner votre sujet ou une question d'intérêt, vous êtes prêt à développer votre modèle en utilisant les étapes suivantes:
Fournir la spécification mathématique générale de votre modèle.
La spécification générale dénote votre variable dépendante et toutes les variables indépendantes (ou explicatives) que vous croyez affecte la variable dépendante dans votre population d'intérêt.
Supposons que trois variables influent sur la variable dépendante. La spécification générale ressemblera Y = F(X1,X2,X3), Où Y est la variable dépendante et le Xs représentent les variables indépendantes, qui vous croyez affecter directement (ou faire) les fluctuations de la Y variable.
À moins que le raisonnement est évidente, fournir une justification pour les variables choisies comme variables indépendantes et pour la forme fonctionnelle de la spécification (voir étape 2). Cela vous aide à éviter l'erreur de spécification, ce qui se produit si vous omettez variables importantes ou inclure des variables pertinentes.
Dériver la spécification économétrique de votre modèle.
Dans cette étape, vous prenez les variables identifiées à l'étape 1 et de développer une fonction qui peut être utilisé pour calculer les résultats économétriques. Cette forme fonctionnelle est connu comme le populuntion regresfonction de Sion (PRF). Dans cette étape, vous êtes également en reconnaissant que la relation que vous l'hypothèse à l'étape 1 est prévu d'exister quand vous regardez la moyenne des pas de données pour chaque observation unique.
Supposons que vous avez des raisons de croire que le modèle est linéaire. Il ressemblera à ceci:
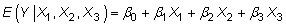
Dans cette fonction, le opérateur moyenne conditionnelle E(Y|X1,X2,X3) Indique que la relation est prévu de tenir, en moyenne, pour des valeurs données des variables indépendantes. Le terme d'interception
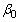
également appelé le constant, est la valeur moyenne prévue de Y lorsque toutes Xs sont égaux à zéro. Les autres bêtas représentent les pentes partielles (effets). Ces pentes partielles vous dire combien vos modifications variable dépendante lorsque vous modifiez la variable indépendante d'une unité, mais maintenez la valeur des autres variables indépendantes constantes.
(Cette idée de changer une chose et en gardant le reste le même est le ceteris paribus, ou toutes choses égales, à condition que vous êtes familier avec de vos cours d'introduction à l'économie.)
Selon le phénomène particulier que vous analysez, une relation non linéaire utilisant carré termes, les journaux, ou une autre méthode à la place de la fonction linéaire
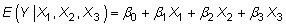
peut être plus approprié.
Le cahier des charges que vous choisissez est supposée décrire la “ true ” relation, donc soyez sûr de le justifier en utilisant la théorie économique saine et de bon sens.
Préciser la nature aléatoire de votre modèle.
Cette étape précise que la relation que vous avez assumé dans les étapes 1 et 2 détient en moyenne, mais peut contenir des erreurs quand une observation spécifique est choisi au hasard dans la population. Ceci est connu comme la fonction de régression de la population stochastique et comme il est écrit
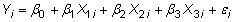
où le je indices désignent toute observation choisie aléatoirement et
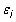
représente le stochastique (ou aléatoire) terme d'erreur associée à cette observation. Noter que stochastic est tout simplement le jargon des statistiques aléatoire.
Peu importe comment vous choisissez de représenter le PRF, le terme d'erreur aléatoire représente la différence entre la valeur observée de la variable dépendante et la moyenne conditionnelle de la variable dépendante dérivé de votre modèle. Cette valeur est positive si la valeur observée est supérieure à la moyenne conditionnelle et négative si elle est inférieure.
L'erreur aléatoire peut résulter d'une ou de plusieurs des facteurs suivants:
Données insuffisantes ou mal mesurées
Un manque de connaissances théoriques pour rendre pleinement compte de tous les facteurs qui influent sur la variable dépendante
Application d'un coffrage fonctionnelle incorrecte par exemple, en supposant que la relation est linéaire quand il est quadratique
Caractéristiques non observables
Éléments imprévisibles de comportement
Si vous avez plusieurs variables explicatives, vous pouvez gagner du temps en écrivant le modèle économétrique utilisant certains raccourci mathématique. Avec la notation algébrique, il ressemblerait à l'une des deux fonctions suivantes:
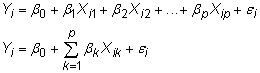




La fonction de régression est généralement exprimée mathématiquement dans l'une des façons suivantes: la notation de base, la notation de sommation, ou la notation matricielle. La Y variable représente le résultat que vous êtes intéressé…
Effets de saisonnalité peuvent être corrélées avec vos deux variables dépendantes et indépendantes. Afin d'éviter de confondre les effets de saisonnalité avec ceux de vos variables indépendantes, vous devez contrôler explicitement pour la…
Vous devez rappeler à partir de votre cours de statistiques façon de mener la t-test pour examiner les différences de moyens entre les deux groupes. Mais ce que vous ne pouvez pas savoir est que vous pouvez utiliser des variables nominales et…
En économétrie, la valeur attendue (ou moyenne) d'une variable aléatoire fournit une mesure de la tendance centrale, ce qui signifie qu'il fournit une mesure de l'endroit où les données tend à se regrouper.La valeur attendue correspond à la…
L'une des décisions les plus importantes que vous faites lorsque vous spécifiez votre modèle économétrique est variables à inclure comme variables indépendantes. Ici, vous trouverez ce que des problèmes peuvent survenir si vous incluez trop…
Variables dépendantes limitées surgissent quand une certaine valeur de seuil minimum doit être atteint avant que les valeurs de la variable dépendante sont observées et / ou quand une certaine valeur maximale de seuil limite les valeurs…
Obtenir une emprise sur multicolinéarité parfaite, ce qui est rare, est plus facile si vous pouvez imaginer un modèle économétrique qui utilise deux variables indépendantes, telles que les suivantes:Supposons que, dans ce modèle,où les…
En économétrie, une variable aléatoire avec une distribution normale a une fonction de densité de probabilité qui est continue, symétrique, et en forme de cloche. Bien que de nombreuses variables aléatoires peuvent avoir une distribution en…
En économétrie, le modèle de régression est un point de départ commun d'une analyse. Comme vous définir votre modèle de régression, vous devez tenir compte de plusieurs éléments:La théorie économique, l'intuition et le bon sens devraient…
Multicollinearity lorsque survient une relation linéaire existe entre deux ou plusieurs variables indépendantes dans un modèle de régression. Dans la pratique, vous rencontrez rarement multicolinéarité parfaite, mais de haute…
Graphiques décrivent facilement la relation économique entre deux variables- par exemple, une courbe d'offre décrit la relation entre le prix et la quantité fournie. Les relations économiques sont également exprimés en fonctions…
L'analyse de régression est un outil statistique utilisé pour l'étude des relations entre les variables. Habituellement, l'enquêteur cherche à savoir l'effet causal d'une variable sur une autre - l'effet d'une hausse des prix sur demande, par…
Dans les statistiques de la psychologie, les études de recherche qui impliquent la collecte des données quantitatives (toutes les données qui peut être compté ou rendu sous forme de nombres) exigent habituellement que vous récupériez et…
Être capable d'interpréter les variables est une compétence importante que vous aurez besoin pour le test GED Science. Variables sont tout ce qui change au cours d'une expérience, et ils viennent dans les deux variétés suivantes:Independent:…