Déterminer le lien de causalité avec l'analyse de la clientèle
Bien que la corrélation est pas le seul lien de causalité, il existe des moyens pour déterminer et démontrer la causalité entre les variables des clients. Le montant de la foi que vous pouvez avoir dans les revendications de la causalité dépend de la méthode utilisée pour recueillir les données. Alors que vous pouvez penser que une nouvelle conception de page Web a abouti à plus de pages vues, il se pourrait que de pages vues avaient déjà augmenté.
Sommaire
Vous pouvez utiliser l'une des cinq méthodes pour faire des allégations sur le lien de causalité, à partir de la plus forte et de procéder par la plus faible.
Étude expérimentale randomisée
Attribuer au hasard les participants à différents traitements de conception et / ou un contrôle dans une étude de recherche est un modèle expérimental. Par exemple, si vous voulez savoir quels clients de conception comprendraient le plus sur une page check-out, vous pouvez créer trois modèles différents:
La variable dépendante pourrait être quelque chose comme
Précision à répondre aux questions
Difficulté à vérifier
Confiance à vérifier
Le temps de vérifier
La variable indépendante est la conception - avec trois variations.
La caractéristique de la recherche expérimentale est d'attribuer au hasard les participants à différents traitements. Vous identifiez la conception que les utilisateurs correctement sélectionnés et étaient les plus confiants dans l'utilisation à faire leur choix.
Il ya toutes sortes de variables que vous ne pouvez pas contrôler pour - ou ne sont pas conscients - qui pourraient affecter les résultats. Mais par l'assignation aléatoire aux participants de différents dessins ou des conditions de traitement, vous répartissez ces variables nuisance uniformément à travers des dessins. Cela augmente la validité interne et de généraliser les conclusions.
Comme autre exemple, les chercheurs en Europe ont mené une expérience dans laquelle ils manipulés à la fois la convivialité et l'attrait visuel d'un site e-commerce en ligne. Ils ont essentiellement un site, faites la navigation intuitive ou non intuitive, puis changé les couleurs et le contraste pour être attrayant ou attrayante.
Ils ont constaté que les clients à trouver des sites plus utilisables plus attrayant. Les chercheurs ont conclu que meilleure ergonomie augmente opinions sur l'attractivité. Leur conclusion est bien fondée, car ils ont utilisé un modèle expérimental aléatoire.
Expériences (avec assignation aléatoire) fournissent les contrôles les plus forts contre les variables parasites et fournissent les plus hauts niveaux de validité interne. Ceux-ci génèrent les types les plus forts des résultats de recherche. Mais qu'advient-il si vous ne pouvez pas attribuer au hasard les participants?
Modèle quasi-expérimental
Si vous voulez tester différentes conditions, mais vous ne pouvez pas attribuer au hasard les participants aux différentes conditions, l'étude est quasi-expérimentale. Par exemple, vous voudrez peut-être de savoir si les clients trouvent la version bêta d'un produit logiciel plus utilisable que une version existante. Les clients des logiciels bêta du bénévolat en général d'utiliser le logiciel pendant la période de beta-test.
Cette auto-sélection cession (non aléatoire) introduit une source potentielle de biais dans les résultats. Il a validité externe plus élevé parce que ces groupes sont naturellement segmentés, mais a la fiabilité interne inférieure.
Lorsque vous comparez les attitudes de convivialité (-dire du SUS ou SUPR-Q) des clients de logiciels bêta pour les clients de version existante et de trouver une différence, la différence pourrait être due à des différences dans le type de personnes qui utilisent le logiciel et les différences ne réels dans l'attitude. Ce type de problème est la confusion et rend la quasi-expérimental type moins une validité interne que la condition expérimentale de conception.
La faiblesse des études quasi-expérimentale est que vous ne pouvez jamais être aussi sûr que vous pouvez avec assignation aléatoire que toute augmentation des ventes est attribuable à la variable (dans ce cas, les ventes) ou à d'autres variables de nuisance (dans ce cas, les différences seulement entre les marchés).
Étude corrélationnelle
UN étude de corrélation, comme son nom l'indique, est quand vous regardez la relation entre deux variables et de signaler la corrélation. Par exemple, la relation entre la facilité d'utilisation du produit et de la probabilité de recommander une forte corrélation positive (facilité signifiant est fortement associé à, et probablement prédit, une grande partie de la raison pour laquelle les utilisateurs font et ne recommande pas de produits).
Alors que les études de corrélation des résultats précieux, ils ne disposent pas de l'assignation aléatoire et les variables indépendantes ne sont pas manipulés, ce qui réduit la validité interne des résultats et affaiblit la thèse de la causalité.
La prochaine fois que vous entendez que l'on mesure à la clientèle entraîne une autre mesure, regardez pour identifier la façon dont a été déterminée. Il ya des chances, il a été fait avec soit une étude de corrélation ou une conception quasi-expérimentale. Cela ne signifie pas une variable ne provoque pas l'autre- il signifie simplement que vous ne pouvez pas être aussi confiant.
Seule étude-sujets
Il est souvent le cas que l'obtention de l'accès aux clients est extrêmement difficile. Par exemple, vous pourriez être intéressés à savoir si une nouvelle interface pour un scanner TEP réduit le temps qu'il faut assister aux radiologues de régler un paramètre sur le scanner.
Si vous aviez accès à un de ces clients, vous pourriez lui demander d'effectuer une tâche sur la version existante du logiciel à trois reprises, record combien de temps il a fallu pour compléter, ont sa tentative la même tâche trois fois sur le nouveau logiciel, et enfin, Sa tentative ont à nouveau trois fois sur l'ancienne version. La figure montre comment ces données semble sur un nuage.
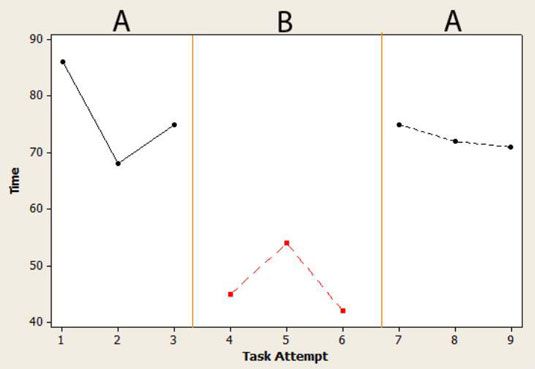
Ce type d'étude à sujet unique utilise ce qu'on appelle un état de l'ABA (où A est le logiciel existant et B est le nouveau logiciel). Les essais répétés aident à établir la stabilité dans les mesures et d'augmenter la validité interne de la constatation (autant que vous le pouvez à partir d'un seul sujet).
La limitation évidente avec la conception unique objet est de généraliser. Tout ce que vous savez est que lorsque vous manipulez une variable indépendante (le logiciel), le temps de la tâche descend pour un utilisateur. Il pourrait y avoir un certain nombre de variables que vous n'êtes pas représentant. Pour cette raison, des dessins à sujet unique ne sont pas utilisés très souvent dans la recherche de la clientèle.
Vous pouvez réellement utiliser plus d'un participant dans un design unique sujet (par exemple, deux ou trois radiologues) et utiliser la même technique pour établir le motif. Pour être plus sophistiquée dans votre analyse, vous pouvez également utiliser l'analyse de séries chronologiques pour examiner les tendances au fil du temps et par condition pour chaque utilisateur ou les données dans leur ensemble.
Anecdotes
Malheureusement, de nombreuses décisions d'affaires sont prises en fonction de l'opinion ou de l'audition d'un client ou représentant vocale. Alors qu'une bonne histoire d'une stratégie de produit à succès peut être convaincant émotionnellement, il a peu de poids lors de l'établissement du lien de causalité.
-
 Comment estimer les effets de saisonnalité
Comment estimer les effets de saisonnalité -
 Reconnaissant variables habituelles: distribution normale
Reconnaissant variables habituelles: distribution normale -
 Déterminer la relation entre les variables à l'aide de covariance et de corrélation
Déterminer la relation entre les variables à l'aide de covariance et de corrélation - Comment les entreprises utilisent des statistiques d'analyse de régression
- Comment corrélation, régression, et deux tableaux à clarifier les données statistiques
-
 Comment covariance et de corrélation sont liés
Comment covariance et de corrélation sont liés
De tous les problèmes statistiques mal compris, celui qui est peut-être le plus problématique est la mauvaise utilisation des concepts de corrélation et causalité. Corrélation, comme un terme statistique, est la mesure dans laquelle les deux…
Dans les statistiques, un variable aléatoire est une caractéristique, la mesure ou le nombre qui change de façon aléatoire selon un certain ensemble ou un motif. Variables aléatoires sont généralement désignés par des lettres majuscules,…
Dans les statistiques, variables aléatoires numériques représentent un compte et des mesures. Ils viennent dans deux saveurs différentes: discrètes et continues, selon le type de résultats qui sont possibles:Variables aléatoires discrètes.…
Parfois, les élèves sont un peu incertain de la façon dont le nombre de variables à inclure quand ils sont la planification d'une étude de recherche en psychologie. Mais il est facile d'inclure un trop grand nombre, ce qui a le potentiel pour…
Comme beaucoup d'autres domaines, la psychologie est dépendante de la recherche en tant que discipline. Il est important de maintenir les principes éthiques au cours des recherches. Cinq principes éthiques clés sous-tendent la recherche…
Dans les statistiques de la psychologie, les études de recherche qui impliquent la collecte des données quantitatives (toutes les données qui peut être compté ou rendu sous forme de nombres) exigent habituellement que vous récupériez et…
Comme vous le feriez avec une discipline, vous voulez vous assurer que vous êtes vos résultats de recherche sont valables en psychologie. La recherche quantitative en psychologie utilise différents types de test ou le questionnaire…
Dans les statistiques de la psychologie, les études de recherche qui impliquent la collecte des données quantitatives (toutes les données qui peut être compté ou rendu sous forme de nombres) exigent habituellement que vous récupériez et…
Le test GED science va attendre que vous êtes en mesure d'identifier les forces et les faiblesses dans une enquête scientifique. Les recherches scientifiques devraient être empirico qui est, les conclusions devraient être fondées sur…
Pour l'adjoint au médecin Exam (PANCE), vous devez être conscient des différences entre les types d'études épidémiologiques. La première étape est de reconnaître si l'étude est une étude rétrospective ou une étude…
Réalisation d'un bien planifiée 2k expérience factorielle for Six Sigma est facile - il est comme tomber un journal. Vous avez juste à retrousser vos manches et rentrez dans les tranchées scientifiques.Aléatoire: Protéger contre les facteurs…
Avec analyse de la clientèle, la collecte de données à partir d'un échantillon de clients coûte beaucoup moins cher et prend beaucoup moins de temps que la mesure de chaque client. Le niveau de précision que vous obtenez de même un petit…
Vous pouvez numériquement quantifier la force d'une association en utilisant le Moment corrélation de Pearson produit. Il est souvent simplement appelé le coefficient de corrélation et est représenté par le symbole r. La corrélation est…
Bien qu'une corrélation parle à la force d'une relation entre les deux variables, et la r2 contribue à expliquer que la force de la relation, ce que vous devez faire pour prédire une variable d'un autre est d'utiliser une extension de l'analyse…