3 modèles de probabilité linéaire (LPM) Principaux problèmes
En utilisant la technique des moindres carrés ordinaires (MCO) pour estimer un modèle avec une variable dépendante factice est connu comme la création d'un modèle de probabilité linéaire,
ou LPM. LPM ne sont pas parfaits. Trois problèmes spécifiques peuvent se présenter:La non-normalité du terme d'erreur
Erreurs hétéroscédastiques
Prédictions potentiellement absurdes
La non-normalité du terme d'erreur
L'hypothèse que l'erreur est normalement distribué est essentiel pour effectuer des tests d'hypothèses après l'estimation de votre modèle économétrique.
Le terme d'erreur d'un LPM a une distribution binomiale au lieu d'une distribution normale. Il implique que la traditionnelle t-les tests de signification individuelle et F-les tests de signification globale ne sont pas valides.
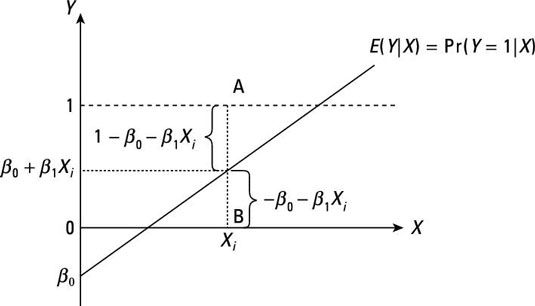
Comme vous pouvez le voir, le terme d'erreur dans un LPM a l'une des deux valeurs possibles pour une donnée X valeur. Une valeur possible pour l'erreur (si Y = 1) est donné par A, et l'autre valeur possible de l'erreur (si Y = 0) est donnée par B. Par conséquent, il est impossible pour le terme d'erreur d'avoir une distribution normale.
Heteroskedasticity
Le modèle de régression linéaire classique (CLRM) suppose que le terme d'erreur est homoscédastique. L'hypothèse d'homoscédasticité est tenu de prouver que les estimateurs MCO sont efficaces (ou mieux). La preuve que estimateurs MCO sont efficaces est une composante importante du théorème de Gauss-Markov. La présence d'hétéroscédasticité peut provoquer le théorème de Gauss-Markov pour être violée et conduire à d'autres caractéristiques indésirables pour les estimateurs MCO.
Le terme d'erreur dans un LPM est hétéroscédastique parce que la variance est pas constante. Au lieu de cela, la variance du terme d'erreur LPM dépend de la valeur de la variable (s) indépendante.
Utilisation de la structure de la LPM, vous permet de caractériser la variance de son terme d'erreur comme suit
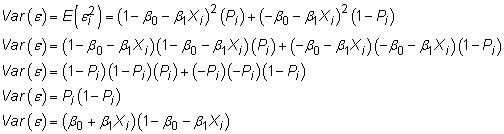
Étant donné que la variance de l'erreur dépend de la valeur de X, il présente hétéroscédasticité plutôt que homoscédasticité.
Probabilités prédites Unbounded
La plupart des lois de base de probabilité indique que la probabilité d'un événement doit être contenue dans l'intervalle [0,1]. Mais la nature d'un LPM est telle qu'elle ne permet pas d'assurer cette loi fondamentale de la probabilité est satisfaite. Bien que la plupart des probabilités prédites à partir d'un LPM ont des valeurs raisonnables (entre 0 et 1), certaines probabilités prédites peuvent avoir des valeurs absurdes qui sont inférieur à 0 ou supérieur à 1.
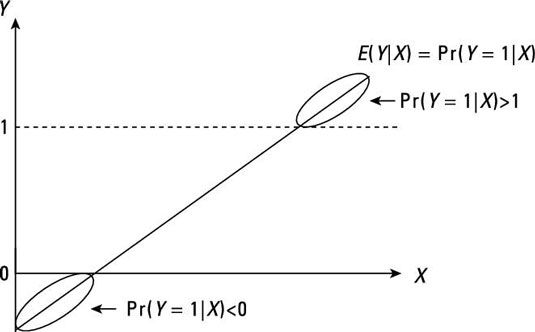
Jetez un oeil à la figure suivante et de concentrer votre attention sur les segments de la ligne de régression où la probabilité conditionnelle est supérieure à 1 ou inférieure à 0. Lorsque la variable dépendante est continue, vous ne devez pas vous inquiéter au sujet des valeurs sans bornes pour le moyennes conditionnelles. Cependant, les variables dichotomiques sont problématiques parce que les moyens sursis représentent probabilités conditionnelles. Interprétation probabilités qui ne sont pas limitées par des 0 et 1 est difficile.
Vous pouvez voir un exemple de ce problème avec les données réelles:
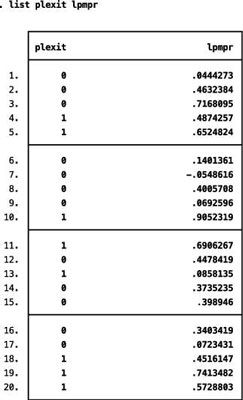
La plupart des probabilités estimées à partir de l'estimation LPM sont contenus dans l'intervalle [0,1], mais la probabilité prédite pour la septième observation est négative. Malheureusement, rien dans l'estimation d'un LPM assure que toutes les probabilités prévues restent dans des valeurs raisonnables.
-
 La densité et de l'économétrie ou bivariées probabilité conjointe
La densité et de l'économétrie ou bivariées probabilité conjointe -
 L'estimation économétrique et les hypothèses de CLRM
L'estimation économétrique et les hypothèses de CLRM -
") Économétrie et de la fonction de densité cumulative (CDF)
Économétrie et de la fonction de densité cumulative (CDF) -
 Économétrie pour les nuls
Économétrie pour les nuls -
 Comment vérifier l'hétéroscédasticité en examinant les résidus représentées graphiquement
Comment vérifier l'hétéroscédasticité en examinant les résidus représentées graphiquement -
 Comment distinguer entre les perturbations homoscédastiques et hétéroscédastiques
Comment distinguer entre les perturbations homoscédastiques et hétéroscédastiques
Prédiction en économétrie implique une certaine connaissance préalable. Par exemple, vous pouvez tenter de prédire combien de «aime» votre mise à jour de statut sur Facebook obtiendra donné le nombre d '"amis" que vous avez et…
UNutocorrelation, aussi connu comme corrélation sérielle, peuvent exister dans un modèle de régression lorsque l'ordre des observations dans les données sont pertinentes ou importantes. En d'autres termes, avec des séries chronologiques (et…
En économétrie, une version spécifique d'une variable aléatoire normalement distribué est la normale standard. UN distribution normale est une distribution normale avec une moyenne de 0 et une variance de 1. Il est utile parce que vous pouvez…
En économétrie, le modèle de régression est un point de départ commun d'une analyse. Comme vous définir votre modèle de régression, vous devez tenir compte de plusieurs éléments:La théorie économique, l'intuition et le bon sens devraient…
Si votre résultat d'intérêt est qualitative, vous utilisez une variable dépendante mannequin et estimer la probabilité que le résultat (Y = 1) se produit en utilisant votre modèle économétrique. Bien MCO peuvent être utilisés pour estimer…
Lorsque vous travaillez avec des populations et des échantillons (un sous-ensemble d'une population) dans les statistiques commerciales, vous pouvez utiliser trois types de mesures pour décrire l'ensemble de données: la tendance centrale,…
UN distribution de probabilité est une formule ou d'une table pour affecter des probabilités utilisée pour chaque valeur possible d'une variable aléatoire X. Une distribution de probabilité peut être soit discret ou continue. Une distribution…
Dans les statistiques, htests ypothesis se réfère au processus de choix entre hypothèses concurrentes sur une distribution de probabilités, basée sur les données observées à partir de la distribution. Il est un sujet de base et une partie…
Les intervalles de confiance estimer les paramètres de la population, comme la moyenne de population, en utilisant une statistique (par exemple, la moyenne de l'échantillon) plus ou moins une marge d'erreur. Pour calculer la marge d'erreur pour un…
Une façon d'illustrer la distribution binomiale est avec un histogramme. Un histogramme montre les valeurs possibles d'une distribution de probabilité d'une série de barres verticales. La hauteur de chaque barre reflète la probabilité de chaque…
Variables aléatoires et distributions de probabilité sont deux des concepts les plus importants en matière de statistiques. UN variable aléatoire assigne des valeurs numériques uniques pour les résultats d'un experiment- aléatoire ceci est un…
Lorsque vous travaillez avec des distributions de probabilités continues, les fonctions peuvent prendre de nombreuses formes. Ceux-ci comprennent uniforme continue, exponentielle, normale, normale standard (Z), approximation binomiale, Poisson…
Dans probabilité, une distribution discrète a soit un fini ou un nombre infini dénombrable de valeurs possibles. Cela signifie que vous pouvez énumérer ou de faire une liste de toutes les valeurs possibles, comme 1, 2, 3, 4, 5, 6 ou 1, 2, 3,. .…
Le domaine de la probabilité de mathématiques a ses règles propres, les définitions et les lois, que vous pouvez utiliser pour trouver la probabilité des résultats, des événements ou des combinaisons de résultats et les événements. Pour…