Spécification des fonctions non linéaires appropriées: les modèles probit et logit
Si votre résultat d'intérêt est qualitative, vous utilisez une variable dépendante mannequin et estimer la probabilité que le résultat (Y
Sommaire
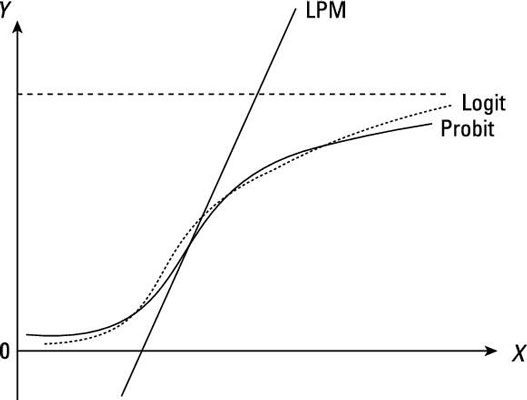
Le problème le plus évident avec l'estimation d'un modèle variable dépendante fictive utilisant OLS est que les probabilités prédites ne sont pas garantis pour être dans le intervalle [0,1]. MCO ne peut pas être modifié pour répondre entièrement à cette question parce que la non-linéarité des paramètres est nécessaire afin de garantir que toutes les probabilités prédites ont des valeurs sensibles. Par conséquent, une autre spécification doit être utilisé. Économètres choisissent soit l'probit ou la fonction logit.
Avec une fonction de probit ou logit, les probabilités conditionnelles sont liées de façon non linéaire à la variable (s) indépendante. En outre, les deux fonctions ont la particularité d'aborder 0 et 1 progressivement (asymptotiquement), de sorte que les probabilités prédites sont toujours judicieux.
La figure illustre les probabilités conditionnelles d'un OLS (aussi connu comme le modèle de probabilité linéaire LPM), un probit, et un modèle logit.
Travailler à partir de la CDF normale standard: Le modèle probit
Le modèle probit est basé sur la norme fonction normale de densité cumulative (CDF), qui est définie comme
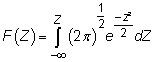
où Z est une variable normale standardisée et e est la base du logarithme naturel (la valeur 2,71828...).
Dans un modèle de probit, la norme CDF normale remplace la fonction linéaire, de sorte que vous estimez
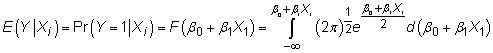
Les termes de bêta ne peuvent être estimés par les MCO, si vous avez besoin d'utiliser une technique connue sous le nom plausibilité maximum (ML).
Pour toute donnée X, le modèle probit fournit la Z valeur pour l'observation. Le PDF normale standard ou CDF peuvent ensuite être utilisés pour obtenir la probabilité que Y = 1 pour cette observation.
La figure suivante montre comment s'y prendre pour trouver la probabilité pour une observation donnée.
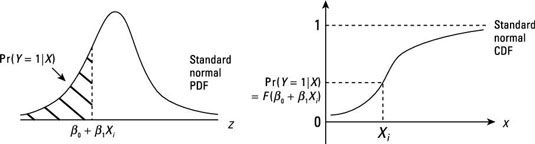
Après avoir estimé un modèle probit, la plupart des logiciels économétriques peut calculer les probabilités prévues pour toutes les observations de l'échantillon.
Fondant au large de la CDF logistique: Le modèle logit
Le modèle logit est basée sur la fonction de densité cumulative logistique (CDF), définie comme
où g est une variable aléatoire logistique et e est la base du logarithme naturel (la valeur 2,71828...).
La distribution logistique peut vous être inconnus, mais il est semblable à une normale standard. Cependant, il n'a moins de densité dans un écart type de la moyenne d'une distribution normale. La figure suivante illustre la différence entre le normal standard et les distributions logistiques.
Dans un modèle logistique, la CDF logistique remplace la fonction linéaire de sorte que vous estimez
Note: Vous ne pouvez pas utiliser MCO pour estimer la betas- la place, vous devez utiliser la technique du maximum de vraisemblance (ML).
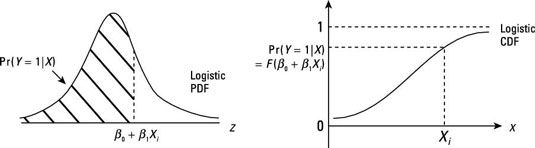
Pour toute donnée X, le modèle logit fournit la valeur pour l'observation qui peut être utilisé avec la CDF logistique pour trouver la probabilité que Y = 1 pour cette observation.
La figure suivante illustre comment vous trouvez la probabilité pour une observation donnée.
Lorsque vous avez votre modèle de logit estimatif, vous pouvez utiliser des logiciels tels que économétrique STATA pour calculer les probabilités prédites pour toutes vos observations de l'échantillon.
-
 Principaux problèmes") 3 modèles de probabilité linéaire (LPM) Principaux problèmes
3 modèles de probabilité linéaire (LPM) Principaux problèmes -
 L'estimation économétrique et les hypothèses de CLRM
L'estimation économétrique et les hypothèses de CLRM -
") Économétrie et de la fonction de densité cumulative (CDF)
Économétrie et de la fonction de densité cumulative (CDF) -
 Econométrie et le modèle log-linéaire
Econométrie et le modèle log-linéaire -
 Econométrie et le modèle log-log
Econométrie et le modèle log-log -
 Comment trouver les différences moyennes en utilisant une variable fictive
Comment trouver les différences moyennes en utilisant une variable fictive
Prédiction en économétrie implique une certaine connaissance préalable. Par exemple, vous pouvez tenter de prédire combien de «aime» votre mise à jour de statut sur Facebook obtiendra donné le nombre d '"amis" que vous avez et…
Avant de commencer avec l'analyse de régression, vous devez identifier le regre de populationsfonction de Sion (PRF). Le PRF définit la réalité (ou votre perception de celui-ci) en ce qui concerne votre sujet d'intérêt. Pour l'identifier, vous…
Variables dépendantes limitées surgissent quand une certaine valeur de seuil minimum doit être atteint avant que les valeurs de la variable dépendante sont observées et / ou quand une certaine valeur maximale de seuil limite les valeurs…
Obtenir une emprise sur multicolinéarité parfaite, ce qui est rare, est plus facile si vous pouvez imaginer un modèle économétrique qui utilise deux variables indépendantes, telles que les suivantes:Supposons que, dans ce modèle,où les…
En économétrie, une version spécifique d'une variable aléatoire normalement distribué est la normale standard. UN distribution normale est une distribution normale avec une moyenne de 0 et une variance de 1. Il est utile parce que vous pouvez…
En économétrie, une variable aléatoire avec une distribution normale a une fonction de densité de probabilité qui est continue, symétrique, et en forme de cloche. Bien que de nombreuses variables aléatoires peuvent avoir une distribution en…
Beaucoup de phénomènes économiques sont dichotomique en nature- en d'autres termes, le résultat soit se produit ou ne se produit pas. Résultats dichotomiques sont le type le plus commun de variables dépendantes discrètes ou qualitatives…
UN distribution de probabilité est une formule ou d'une table pour affecter des probabilités utilisée pour chaque valeur possible d'une variable aléatoire X. Une distribution de probabilité peut être soit discret ou continue. Une distribution…
Les deux types de base de distributions de probabilité sont connus comme discret et continu. Discret distributions décrivent les propriétés d'un variable aléatoire pour lequel chaque résultat individuel est attribué une probabilité…
Vous pouvez utiliser le théorème central limite pour convertir une distribution d'échantillonnage à une variable aléatoire normale standard. Basé sur le théorème central limite, si vous dessinez des échantillons à partir d'une population…
Vous pouvez utiliser le Z-table pour trouver un ensemble complet de probabilités «moins-que" pour une large gamme de z-des valeurs. Pour utiliser le Z-table pour trouver les probabilités pour un échantillon statistique avec une normale…
Dans les statistiques, vous pouvez facilement trouver les probabilités pour une moyenne de l'échantillon si elle a une distribution normale. Même si elle n'a pas une distribution normale, ou la distribution est pas connue, vous pouvez trouver des…
Lorsque vous travaillez avec des distributions de probabilités continues, les fonctions peuvent prendre de nombreuses formes. Ceux-ci comprennent uniforme continue, exponentielle, normale, normale standard (Z), approximation binomiale, Poisson…
Toutes les données de processus et de produits dans les projets Six Sigma ont variation- chaque instance répétée de tout point de données mesurée est différente de l'instance avant. Et comme la collecte de mesures répétées entasse, une…